Foreword
As an IT-person and Apple geek I started listening to the NosillaCast podcast by Allison Sheridan somewhere in the early '10s. It’s a podcast with a wide variety of tech topics with a slight Apple bias. Topics range from an interview of a blind person using an iPhone to an article on the security measures of a certain bank’s webapp to tutorials on how to fix a tech problem with one of your devices. I especially enjoyed the sections where Bart was explaining some technical topic. The podcasts kept me company on my long commute to and from work.
Somewhere in 2013 Bart announced he was starting a series of tutorials on the Terminal and all kinds of commands to teach Allison. Cool, let’s see how much I already know. The first sessions were easy. I knew most of what Bart was explaining, and yes, I was one of those persons yelling in the car when Bart quizzed Allison.
Soon I heard new things and quickly it became a game. What would Bart explain this time and would I know it or would it be new. I started to look forward to the commute time because that’s the time I would listen to the podcast. I even felt sad when Bart explained that episode 35 was the last one of the series. Luckily time proved him wrong and now the episodes kept coming.
When people at work expressed fear of Terminal commands, I would point them to the series on Bart’s website, allowing my co-workers to read his tutorials and listen to the podcast audio. I even added the most relevant episodes to the training we had for our new junior developers.
In 2016 I went to Dublin for a holiday and actually met Bart in real life. Turns out he’s a great guy and a kindred spirit. It’s his passion to teach people about the stuff he loves that makes him so valuable to the community. He combines that with academic precision to present well-researched information in bite-sized chunks that makes it easy to follow along, no matter what your skill level is.
I hope you get as much fun and knowledge out of this series as I did, now in an eBook.
Helma van der Linden
TTT fan
Preface
Taming the Terminal was created as a podcast and written tutorial with Bart Busschots as the instructor and Allison Sheridan as the student. Taming the Terminal started its life as part of the NosillaCast Apple Podcast and was eventually spun off as a standalone Podcast. Bart and Allison have been podcasting together for many years, and their friendship and camaraderie make the recordings a delightful way to learn these technical concepts. To our American readers, note that the text is written in British English so some words such as "instalment" may appear misspelled, but they are not.
The book version of the podcast was a labor of love by Allison Sheridan and Helma van der Linden as a surprise gift to Bart Busschots for all he has done for the community.
If you enjoy Taming the Terminal, you may also enjoy Bart and Allison’s second podcast entitled Programming By Stealth. This is a fortnightly podcast where Bart is teaching the audience to program, starting with HTML and CSS (that’s the stealthy part since it’s not proper programming), into JavaScript and beyond. As with Taming the Terminal, Bart creates fantastic written tutorials for Programming By Stealth, including challenges to cement the listener’s skills.
You can find Programming By Stealth and Taming the Terminal podcasts along with Allison’s other shows at podfeet.com/blog/subscribe-to-the-podcasts/.
Contributors to Taming the Terminal
Bart Busschots is the author of all of the written tutorials in the Taming the Terminal series so the lion’s share of the credit goes to him. Allison Sheridan is the student of the series asking the dumb questions, and she created the podcast. Steve Sheridan convinced Bart and Allison that instead of having the series buried inside the larger NosillaCast Podcast, that it should be a standalone podcast. He did all of the editing to pull out the audio for the 35 original episodes from the NosillaCast, top and tail with music, and pushed Bart and Allison to record the intros. Steve even created the Taming the Terminal logo.
Allison had a vision of Taming the Terminal becoming an eBook but had no idea how to accomplish this. Helma van der Linden figured out how to programmatically turn the original feature-rich set of HTML web pages into an ePub book as well as producing a PDF version, and even an HTML version. She managed the GitHub project and fixed the technical aspects of the book and kept Allison on task as she did the proofreading and editing of the entire book. Allison created the book cover as well.
Introduction
Taming the Terminal is specifically targeted at learning the macOS Terminal but most of the content is applicable to the Linux command line. If you’re on Windows, it is recommended that you use the Linux Subsystem for Windows to learn along with this book. Wherever practical, Bart explains the differences that you may encounter if you’re not on macOS.
The series started in April 2013 and was essentially complete in 2015 after 35 of n lessons, but Bart carefully labeled them as "of n" because he knew that over time there likely would be new episodes. More episodes have indeed come out, and this book will be updated over time as the new instalments are released.
Zsh vs Bash
In macOS Catalina, released after much of the tutorial content in this book was released, Apple replaced the default shell bash with the zsh shell. As a result you’ll notice the prompt change from $ to % partway through the book. There may be cases where the instructions given during the bash days might not work with today’s zsh.
To switch back to bash if you do run into problems, simply enter:
bash --loginYou’ll be shown this warning explaining how to switch your default interactive shell back to zsh, and can proceed with the lessons.
The default interactive shell is now zsh.
To update your account to use zsh, please run `chsh -s /bin/zsh`.
For more details, please visit https://support.apple.com/kb/HT208050.If you’d like to see these instalments in their web form, you can go to ttt.bartificer.net.
If you enjoy the format of this series, you might also enjoy the podcast and written tutorials for Bart and Allison’s next series, Programming By Stealth at pbs.bartificer.net.
Feedback on the book can be sent to allison@podfeet.com.
We hope you enjoy your journey with Taming the Terminal.
Full Disk Access
Starting with macOS 10.14 Mojave, Apple added privacy controls that prevent apps from accessing your entire disk without explicit permission. This series assumes the Terminal app has been granted either Files and Folders or Full Disk Access permission under Privacy & Security in the macOS settings.
TTT Part 1 of n — Command Shells
I have no idea whether or not this idea is going to work out, but on this week’s Chit Chat Across the Pond audio podcast segment on the NosillaCast Apple Podcast (to be released Sunday evening PST), I’m going to try to start what will hopefully be an on-going series of short unintimidating segments to gently introduce Mac users to the power contained within the OS X Terminal app.
Note: this entire series was later moved to a standalone podcast called Taming the Terminal at podfeet.com/….
I’m on with Allison every second week, and I’ll have other topics to talk about, so the most frequent the instalments in this series could be would be biweekly, but I think they’ll turn out to be closer to monthly on average. While the focus will be on OS X, the majority of the content will be equally applicable to any other Unix or Linux operating system.
In the last CCATP, we did a very detailed segment on email security, and despite the fact that with the benefit of hindsight, I realise it was too much to do at once and should have been split into two segments, it received the strongest listener response of anything of any of my many contributions to the NosillaCast in the last 5 or more years. I hope I’m right in interpreting that as evidence that there are a lot of NosillaCast listeners who want to get a little more technical and get their hands dirty with some good old-fashioned nerdery!
Listen Along: Taming the Terminal Podcast Episode 1
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
The basics
In this first segment, I just want to lay a very basic foundation. I plan to take things very slowly with this series, so I’m going to start the way I mean to continue. Let’s start with some history and some wider context.
Before the days of GUIs (Graphical User Interfaces), and even before the days of simple menu-driven non-graphical interfaces like the original Word Perfect on DOS, the way humans interacted with computers was through a “command shell”. Computers couldn’t (and still can’t) speak or interpret human languages properly, and humans find it very hard to speak in native computer languages like binary machine codes (though early programmers did actually have to do that). New languages were invented to help bridge the gap, and allow humans and computers to meet somewhere in the middle.
{kind=link}
The really big problem is that computers have absolutely no intelligence, so they can’t deal with ambiguity at all. Command shells use commands that look Englishy, but they have very rigid structures (or grammars if you will) that remove all ambiguity. It’s this rigid structure that allows the automated translation from shell commands to binary machine code the computer can execute.
When using any command shell, the single most important thing to remember is that computers are absolutely stupid, so they will do EXACTLY what you tell them to, no matter how silly the command you give them. If you tell a computer to delete all the files on a hard drive, it will, because, well, that’s what you asked it to do! Another important effect of computers’ total lack of intelligence is that there is no such thing as “close enough” — if you give it a command that’s nearly valid, a computer can no more execute it than if you’d just mashed the keyboard with your face. Nearly right and absolute gibberish are just as unintelligible to a computer. You must be exact, and you must be explicit at all times.
No wonder we went on to invent the GUI, this command shell malarky sounds really complicated! There is no doubt that if the GUI hadn’t been invented the personal computer wouldn’t have taken off like it has. If it wasn’t for the GUI, there’s no way there would be more computers than people in my parents home (two of them, and including iPhones and tablets, 6 computers!) Even the nerdiest of nerds use GUI operating systems most of the time because they make a lot of things both easier and more pleasant. BUT — not everything.
We all know that a picture says a thousand words, but when you are using a GUI it’s the computer that is showing you a picture, all you get to do is make crude hand gestures at the computer, which I’d say is worth about a thousandth of a word — so, a single shell command can easily be worth a thousand clicks. This is why all desktop OSes still have command shells built in — not as their ONLY user interface like in times past, but as a window within the GUI environment that lets you communicate with the computer using the power of a command shell.
Even Microsoft understands the power of the command shell. DOS may be dead, but the new Windows Power Shell is giving Windows power users a new, more modern, and more powerful command shell than ever before. Windows 8 may have removed the Start menu, but Powershell is still there! All Linux and Unix distros have command shells, and OS X gives you access to an array of different Command Shells through Terminal.app.
Just like there is no one GUI interface, there is no one command shell. Also, just like most GUIs are at least somewhat similar to each other, they all use icons for example, most command shells are also quite similar, having a command prompt that accepts commands with arguments to supply input to the commands or alter their behaviour. OS X does not ship with one command shell, it ships with SIX (sh, bash, zsh, csh, tcsh, and ksh)!
You can see the list of available shells (and set your default shell) by opening System Preferences, going to the Users & Groups pref pane, unlocking it, then right-clicking on your username in the sidebar, and selecting Advanced Options ...:
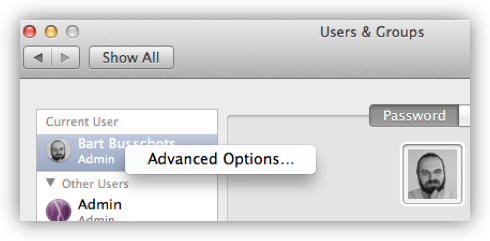
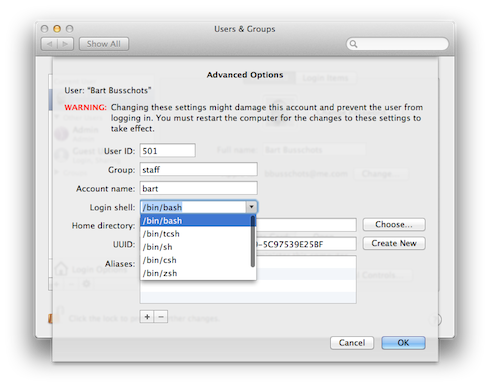
The default shell on OS X is the Bourne Again Shell (Bash), so that’s the shell we’ll be using for the remainder of this series. If you’ve not altered the defaults, then whenever you open a Terminal window on OS X, what you’re presented with is a Bash command shell. Bash is an updated and improved version of the older Bourne Shell (sh), which was the default shell in Unix for many years. The original Bourne Shell dates all the way back to 1977 and is called after its creator, Stephen Bourne. The Bourne Again Shell is a ‘newer’ update to the Bourne Shell dating back to 1989, the name being a nerdy religious joke by its author, Brian Fox. The Bourne Again Shell was not the last in the line of shells tracing their origins to the Bourne Shell, there is also zsh which dates back to 1990, but despite being a more powerful shell, it hasn’t taken off like Bash has.
So, what does a shell do?
Does it just let you enter a single command and then run it?
Or is there more to it?
Unsurprisingly, there’s a lot more to it!
The shell does its own pre-processing before issuing a command for you, so a lot of things that we think of as being part of how a command works are actually features provided by the command shell.
The best example is the almost ubiquitous * symbol.
When you issue a command like chmod 755 *.php, the actual command is not given *.php as a single argument that it must then interpret. No, the * is interpreted and processed by the shell before being passed on to the chmod command.
It’s the shell that goes and looks for all the files in the current folder that end in .php, and replaces the *.php bit of the command with a list of all the actual files that end in .php, and passes that list on to the chmod command.
As well as providing wildcard substitution (the * thing), almost all shells also provide ‘plumbing’ for routing command inputs and outputs between commands and files, the definition of variables to allow sequences of commands to be generalised in a more reusable way, simple programming constructs to enable conditional actions, looping, and the grouping of sequences of commands into named functions, and the execution of a sequence of commands inside a file (scripting), and much more. Different shells also provide their own custom features to help make life at the command prompt easier for users. My favourite is tab-completion which is the single best thing Bash has to offer over sh in my opinion. OS X also brings some unique features to the table, with superb integration between the GUI and the command shell through features like drag-and-drop support in Terminal.app and shell scripting support in Automator.app. Of all the OSes I’ve used, OS X is the one that makes it the easiest to integrate command-line programs into the GUI.
I’ll end today by explaining an important part of the Unix philosophy, a part that’s still very much alive and well within OS X today. Unix aims to provide a suite of many simple command-line tools that each do just one thing, but do it very well. Complex tasks can then be achieved by chaining these simple commands together using a powerful command shell. Each Unix/Linux command-line program can be seen as a lego brick — not all that exciting on their own, but using a bunch of them, you can build fantastic things! My hope for this series is to help readers and listeners like you develop the skills to build your own fantastic things to make your computing lives easier. Ultimately the goal is to help you create more and better things by using automation to free you from as many of your repetitive tasks as possible!
TTT Part 2 of n — Commands
This is the second instalment of an ongoing series. In the first instalment, I tried to give you a sort of 40,000-foot view of command shells — some context, some history, a very general description of what command shells do, and a little bit on why they are still very useful in the modern GUI age. The most important points to remember from last time are that command shells execute commands, that there are lots of different command shells on lots of different OSes, but that we will be focusing on Bash on Linux/Unix in general, and Bash on OS X in particular. The vast majority of topics I plan to discuss in these segments will be applicable on any system that runs Bash, but, the screenshots I use will be from OS X, and some of the cooler stuff will be OS X only. This segment, like all the others, will be used as part of my bi-weekly Chit Chat Across The Pond (CCATP) audio podcast segment with Allison Sheridan on podfeet.com/…
Last time I focused on the shell and avoided getting in any way specific about the actual commands that we will be executing within the Bash shell. I thought it was very important to make as clear a distinction between command shells and commands as possible, so I split the two concepts into two separate segments. Having focused on command shells last time, this instalment will focus on the anatomy of a command but will start with a quick intro to the Terminal app in OS X first.
Listen Along: Taming the Terminal Podcast Episode 2
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Introducing the Terminal Window
You’ll find Terminal.app in /Applications/Utilities.
Unless you’ve changed some of the default settings (or are using a very old version of OS X), you will now see a white window that is running the bash command shell that looks something like this:
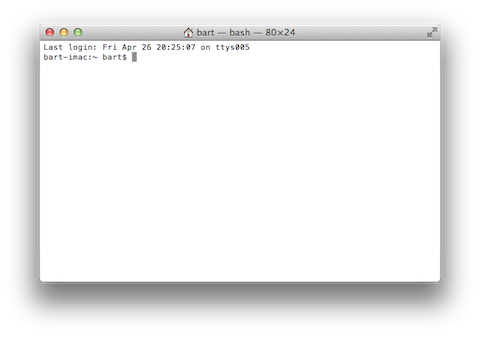
Let’s start at the very top of the window with its title bar. At the left of the title is a proxy icon representing the current directory for the current Bash command shell and beside it the name of that folder. (Note that directory is the Unix/Linux/DOS word for what OS X and Windows refers to as a folder.) Like Finder windows, Terminal sessions are always “in” a particular directory/folder. After the current directory will be a dash, followed by the name of the process currently running in the Terminal session (in our case, a bash shell). The current process is followed by another dash, and then the dimensions of the window in fixed-width characters.
Within the window itself you will likely see a line of output telling you when you last logged in, and from where (if it was on this computer it will say ttys followed by some number, if it was from another computer, it will give the computer’s hostname). This will be followed on the next line by the so-called command prompt, and then the input cursor.
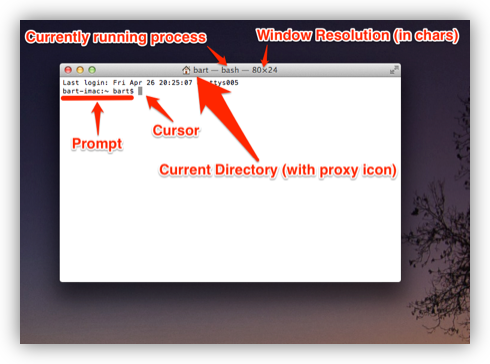
Let’s have a closer look at the command prompt. As with almost everything in Linux/Unix, the prompt is entirely customisable, so although Bash is the default shell on lots of different operating systems, the default prompt on each of those systems can be different. Let’s first look at the default Bash command prompt on OS X:

On OS X, the prompt takes the following form:
hostname:current_directory username$
First, you have the hostname of the computer on which the command shell is running (defined in ). This might seem superfluous, but it becomes exceptionally useful once you start using ssh to log in to other computers via the Terminal.
The hostname is followed by a : and then the command shell’s current directory (note that ~ is short-hand for “the current user’s home folder”, more on this next time).
The current directory is followed by a space, and then the Unix username of the user running the command shell (defined when you created your OS X account, defaults to your first name if available).
Finally, there is a $ character (which changes to a # when you run bash as the root user).
Again, this might not seem very useful at first, but there are many reasons you may want to switch your command shell to run as a different user from time to time, so it is also very useful information.
As an example of how the default shells differ on different operating systems, below is an example from a RedHat-style Linux distribution (CentOS in this case):

As you can see, it contains the same information, but arranged a little differently:
[username@hostname current_directory]$
Finally, Debian-style Linux distributions like Ubuntu use a different default prompt again, but also showing the same information:

username@hostname:current_directory$
Handy Tip: if you find the text in the Terminal window to small to read, you can make it bigger or smaller with ⌘++ or ⌘+-. This will affect just your current Terminal window. You can permanently change the default by editing the default profile in .
The Anatomy of a Command
Now that we understand the different parts of our Terminal window, let’s have a look at the structure of the actual commands we will be typing at that cursor!
I want to start by stressing that the commands executed by a command shell are not determined by the command shell, but by the operating system. Regardless of whether you use Bash on OS X, or zsh on OS X, you will have to enter OS X commands. Similarly, if you use Bash on Linux, you will have to enter Linux commands. Thankfully Linux and Unix agree almost entirely on the structure of their basic commands, so with a very few (and very annoying) exceptions, you can use the same basic commands on any Linux or Unix distribution (remember that at its heart OS X is Free BSD Unix).
Commands take the form of the command itself optionally followed by a list of arguments separated by spaces, e.g.:
command argument_1 argument_2 … argument_n
Arguments are a mechanism for passing information to a command. Most commands need at least one argument to be able to perform their task, but some don’t. Both commands and arguments are case-sensitive, so beware your capitalisation!
For example, the cd (change directory) command takes one argument (a directory path):
bart-imac:~ bart$ cd /Users/Shared/
bart-imac:Shared bart$In this example, the command is cd, and the one argument passed is /Users/Shared/.
Some commands don’t require any arguments at all, e.g.
the pwd (present working directory) command:
bart-imac:~ bart$ pwd
/Users/bart
bart-imac:~ bart$It is up to each command to determine how it will process the arguments it is given. When the developer was creating the command he or she will have had to make decisions about what arguments are compulsory, what arguments are optional, and how to parse the list of arguments the command is given by the shell when being executed.
In theory, every developer could come up with their own mad complex scheme for parsing argument lists, but in reality most developers loath re-inventing the wheel (thank goodness), so a small number of standard libraries have come into use for parsing arguments. This means that many apps use very similar argument styles.
As well as accepting simple arguments like the cd command above, many apps accept specially formatted arguments referred to as flags.
Flags are usually used to specify optional extra information, with information that is required taken as simple arguments.
Flags are arguments (or pairs of arguments) that start with the - symbol.
The simplest kinds of flags are those that don’t take a value, they are specified using a single argument consisting of a - sign followed by a single letter.
For example, the ls (list directory) command can accept the flag -l (long-form listing) as an argument.
e.g.
bart-imac:Shared bart$ ls -l
total 632
drwxrwxrwx 3 root wheel 102 5 Dec 2010 Adobe
drwxrwxrwx 3 bart wheel 102 27 Mar 2012 Library
drwxrwxrwx@ 5 bart wheel 170 28 Dec 21:24 SC Info
drwxr-xr-x 4 bart wheel 136 22 Feb 21:42 cfx collagepro
bart-imac:Shared bart$The way the standard argument processing libraries work, flags can generally be specified in an arbitrary order.
The ls command also accepts the flag -a (list all), so the following are both valid and equivalent:
bart-imac:Shared bart$ ls -l -aand
bart-imac:Shared bart$ ls -a -lThe standard libraries also allow flags that don’t specify values to be compressed into a single argument like so:
bart-imac:Shared bart$ ls -alSometimes flags need to accept a value, in which case the flag stretches over two arguments which have to be contiguous.
For example, the ssh (secure shell) command allows the port to be used for the connection to be specified with the -p flag, and the username to connect as with the -l flag, e.g.:
bart-imac:Shared bart$ ssh bw-server.localdomain -l bart -p 443These single-letter flags work great for simple commands that don’t have too many options, but more complex commands often support many tens of optional flags.
For that reason, another commonly used argument processing library came into use that accepts long-form flags that start with a -- instead of a single -.
As well as allowing a command to support more flags, these longer form flags also allow values to be set within a single argument by using the = sign.
As an example, the mysql command (needs to be installed separately on OS X) allows the username and password to be used when making a database connection to be specified using long-form flags:
...$ mysql --username=bart --password=open123 example_databaseMany commands support both long and short form arguments, and they can be used together, e.g.:
...$ mysql --username=bart --password=open123 example_database -vSo far we know that commands consist of a command optionally followed by a list of arguments separated by spaces, and that many Unix/Linux commands use similar schemes for processing arguments where arguments starting with - or -- are treated in a special way, and referred to as flags.
That all seems very simple, but, there is one important complication that we have to address before finishing up for this segment, and that’s special characters.
Within Bash (and indeed every other command shell), there are some characters that have a special meaning, so they cannot be used in commands or arguments without signifying to the command shell in some way that it should interpret these symbols as literal symbols, and not as representations of some sort of special value or function.
The most obvious example from what we have learned today is the space character, it is used as the separator between commands and the argument list that follows, and within that argument list as the separator between individual arguments. What if we want to pass some text that contains a space to a command as an argument? This happens a lot because spaces are valid characters within file and folder names on Unix and Linux, and file and folder names are often passed as arguments.
As well as the space there are other symbols that have special meanings. I won’t explain what they mean today, but I will list them:
-
space
-
# -
; -
" -
' -
` -
\ -
! -
$ -
( -
) -
& -
< -
> -
|
You have two choices for how you deal with these special characters when you need to include them within an argument, you can escape each individual special character within the argument, or you can quote the entire argument.
Escaping is easy, you simply prefix the special character in question with a \.
If there are only one or two special characters in an argument this is the simplest and easiest solution.
But, it can become tedious if there are many such special characters.
Let’s use the echo command to illustrate escaping.
The echo command simply prints out the input it receives.
The following example passes the phrase Hello World! to the echo command as a single argument.
Note that this phrase contains two special characters that will need to be escaped, the space and the !:
bart-imac:~ bart$ echo Hello\ World\!
Hello World!
bart-imac:~ bart$If you don’t want to escape each special character in an argument, you can quote the argument by prepending and appending either a " or a ' symbol to it.
There is a subtle difference between using ' or ".
When you quote with ' you are doing so-called full quoting, every special character can be used inside a full quote, but, it is impossible to use a ' character inside a fully quoted argument.
For example:
bart-imac:~ bart$ echo '# ;"\!$()&<>|'
# ;"\!$()&<>|
bart-imac:~ bart$When you quote with " on the other hand you are doing so-called partial quoting, which means you can use most special characters without escaping them, but not all.
Partial quoting will become very important later when we start to use variables and things because the biggest difference between full and partial quoting is that you can’t use variable substitution with full quoting, but you can with partial quoting (don’t worry if that makes no sense at the moment, it will later in the series).
When using partial quoting you still have to escape the following special characters:
-
" -
` -
\ -
$
For example:
bart-imac:~ bart$ echo "# ;\!()&<>|"
# ;\!()&<>|
bart-imac:~ bart$and:
bart-imac:~ bart$ echo "\\ \$ \" \`"
\ $ " `
bart-imac:~ bart$There are a few other peculiar edge cases with partial quoting — for example, you can’t end a partial quote with a !, and you can’t quote just a * on its own (there may well be more edge cases I haven’t bumped into yet).
That’s where we’ll leave it for this segment. We’ve now familiarised ourselves with the OS X Terminal window, and we’ve described the anatomy of a Unix/Linux command. In the next segment, we’ll look at the Unix/Linux file system, and at some of the commands used to navigate around it.
TTT Part 3 of n — File Systems
This is the third instalment of an on-going series. These blog posts are only part of the series, they are actually the side-show, being effectively just my show notes for discussions with Allison Sheridan on my bi-weekly Chit Chat Across the Pond audio podcast on podfeet.com/…. This instalment will be featured in NosillaCast episode 418 (scheduled for release late on Sunday the 12th of May 2013).
In the first instalment, we started with the 40,000ft view, looking at what command shells are, and why they’re still relevant in today’s GUI-dominated world. In the second instalment we looked at OS X’s Terminal.app, the anatomy of the Bash command prompt, and the anatomy of a Unix/Linux command. This time we’ll be looking at the anatomy of file systems in general, and the Unix/Linux file system in particular, and how it differs from the Windows/DOS file system many of us grew up using.
Listen Along: Taming the Terminal Podcast Episode 3
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
File systems
Physical storage media are nothing more than a massive array of virtual pigeon holes, each of which can hold a single 1 or 0. All your information is stored by grouping together a whole bunch of these pigeon holes and giving that grouping of 1s and 0s some kind of name. Humans simply could not deal with remembering that the essay they were working on is stored in sectors 4 to 1024 on cylinder 213 on the disk connected to the first SATA channel on the motherboard. We need some kind of abstraction to bring order to the chaos and to allow us to organise our data in a human-friendly way.
A good analogy would be a pre-computer office where the unit of storage was a single sheet of paper. Without some sort of logical system for organising all this paper, no one would ever be able to find anything, hence, in the real world, we developed ‘systems’ for ‘filing’ paper. Or, to put it another way, we invented physical filesystems, based around different ways of grouping and naming the pieces of paper. If a single document contained so much information that it ran over multiple pages, those piece of paper were physically attached to each other using a tie, a paperclip, or a staple. To be able to recognise a given document at a glance, documents were given titles. Related documents were then put together into holders that, for some reason were generally green, and those holders were then placed into cabinets with rails designed to hold the green holders in an organised way. I.e. we had filing cabinets containing folders which contained files. The exact organisation of the files and folders were up to the individual clerks who managed the data and were dependant on the kind of data being stored. Doctors tend to store files alphabetically by surname, while libraries love the Dewey Decimal system.
When it comes to computers, the job of bringing order to the chaos falls to our operating systems. We call the many different schemes that have been devised to provide that order, filesystems. Some filesystems are media dependent, while others are operating system dependent. E.g. the Joliet file system is used on CDs and DVDs regardless of OS, while FAT and NTFS are Windows filesystems, EXT is a family of Linux file systems, and HFS+ is a Mac file system.
There is an infinite number of possible ways computer scientists could have chosen to bring order to the chaos of bits on our various media, but, as is often the case, a single real-world analogy was settled on by just about all operating system authors. Whether you use Linux, Windows, or OS X, you live in a world of filesystems that contain folders (AKA directories) that contain files and folders. Each folder and file in this recursive hierarchical structure has a name, so it allows us humans, to keep our digital documents organised in a way that we can get our heads around. Although all our modern filesystems have their own little quirks under the hood, they all share the same simple architecture, your data goes in files which go in folders which can go in other folders which eventually go into file systems.
You can have lots of files with the same name in this kind of file system, but, you can never have two items with the same name in the same folder.
This means that each file and folder can be uniquely identified by listing all the folders you pass to get from the so-called ‘root’ of the filesystem as far as the file or folder you are describing.
This is what we call the full path to a file or folder.
Where operating systems diverge is in their choice of separator, and in the rules they impose on file and folder names.
On all modern consumer operating systems, we write file paths as a list of folder and file names separated by some character, called the ‘path separator’.
DOS and Windows use \ (the backslash) as the path separator, on classic MacOS it was : (old OS X apps that use Carbon instead of Cocoa still use : when showing file paths, iTunes did this up until the recent version 11!), and on Linux/Unix (including OS X), / (the forward-slash) is used.
A single floppy disk and a single CD or DVD contain a single file system to hold all the data on a given disk, but that’s not true for hard drives, thumb drives, or networks. When formatting our hard drives or thumb drives we can choose to sub-divide a single physical device into multiple so-called partitions, each of which will then contain a single filesystem.
You’ve probably guessed by now that on our modern computers we tend to have more than one filesystem. Even if we only have one internal hard disk in our computer that has been formatted to have only a single partition, every CD, DVD, or thumb drive we own contains a filesystem, and, each network share we connect to is seen by our OS as yet another file system. In fact, we can even choose to store an entire filesystem (even an encrypted one) in a single file, e.g. DMG files, or TrueCrypt vaults.
So, all operating systems have to merge lots of file systems into a single over-arching namespace for their users. Or, put another way, even if two files have identical paths on two filesystems mounted by the OS at the same time, there has to be a way to distinguish them from each other. There are lots of different ways you could combine multiple filesystems into a single unified namespace, and this is where the DOS/Windows designers parted ways with the Unix/Linux folks. Microsoft combines multiple file systems together in a very different way to Unix/Linux/OS X.
Let’s start by looking at the approach Microsoft chose.
In DOS, and later Windows, each filesystem is presented to the user as a separate island of data named with a single letter, referred to as a drive letter.
This approach has an obvious limitation, you can only have 26 file systems in use at any one time!
For historical reasons, A:\ and B:\ were reserved for floppy drives, so, the first partition on the hard drive connected to the first IDE/SATA bus on the motherboard is given the drive letter C:\, the second one D:\ and so on.
Whenever you plug in a USB thumb drive or a memory card from a camera it gets ‘mounted’ on the next free drive letter.
Network shares also get mounted to drive letters.
Just like files and folders, filesystems themselves have names too, often referred to as Volume Names. Windows makes very little use of these volume names though, they don’t show up in file paths, but, Windows Explorer will show them in some situations to help you figure out which of your USB hard drives ended up as K:\ today.
An analogy you can use for file systems is that of a tree. The trunk of the tree is the base of the file system, each branch is a folder, and each leaf a file. Branches ‘contain’ branches and leaves, just like folders contain folders and files. If you bring that analogy to Microsoft’s way of handling filesystems, then the global namespace is not a single tree, but a small copse of between 1 and 26 trees, each a separate entity, and each named with a single letter.
If we continue this analogy, Linux/Unix doesn’t plant a little copse of separate trees like DOS/Windows, instead, they construct one massive Franken-tree by grafting smaller trees onto the branches of a single all-containing master tree.
When Linux/Unix boots, one filesystem is considered to be the main filesystem and used as the master file system into which other file systems get inserted as folders.
In OS X parlance, we call the partition containing this master file system the System Disk.
Because the system disk becomes the root of the entire filesystem it is gets assigned the shortest possible file path, /.
If your system disk’s file system contained just two folders, folder_1 and folder_2, they would get the file paths /folder_1/ and /folder_2/ in Linux/Unix/OS X.
The Unix/Linux command mount can then be used to ‘graft’ filesystems into the master filesystem using any empty folder as the so-called mount point.
On Linux systems, it’s common practice to keep home folders on a separate partition, and to then mount that separate partition’s file system as /home/.
This means that the main filesystem has an empty folder in it called home and that as the computer boots, the OS mounts a specified partition’s file system into that folder.
A folder at the root of the that partition’s file system called just allison would then become /home/allison/.
On regular Linux/Unix distributions the file /etc/fstab (file system table) tells the OS what filesystems to mount to what mount points.
A basic version of this file will be created by the installer, but in the past, whenever you added a new disk to a Linux/Unix system you had to manually edit this file.
Thankfully, we now have something called automount to automatically mount any readable filesystems to a predefined location on the filesystem when they are connected.
The exact details will change from OS to OS, but on Ubuntu, the folder /media/ is used to hold mount points for any file system you connect to the computer.
Unlike Windows, most Linux/Unix systems make use of filesystems’ volume names and use them to give the mount points sensible names, rather than random letters.
If I connect a USB drive containing a single partition with a filesystem with the volume name Allison_Pen_Drive, Ubuntu will automatically mount the filesystem on that thumb drive when you plug it in, using the mount point /media/Allison_Pen_Drive/.
If that pen drive contained a single folder called myFolder containing a single file called myFile.txt, then myFile.txt would be added to the filesystem as /media/Allison_Pen_Drive/myFolder/myFile.txt.
Having the ability to mount any filesystem as any folder within a single master filesystem allows you to easily separate different parts of your OS across different drives.
This is very useful if you are a Linux/Unix sysadmin or power user, but it can really confuse regular users.
Because of this, OS X took a simpler route.
There is no /etc/fstab by default (though if you create one OS X will correctly execute it as it boots).
The OS X installer does not allow you to split OS X over multiple partitions. Everything belonging to the OS X system, including all the users home folders, are installed on a single partition, the system disk, and all other file systems, be they internal, external, network, or disk images, get automatically mounted in /Volumes/ as folders named for the file systems’ volume labels.
Going back to our imaginary thumb drive called Allison_Pen_Drive (which Ubuntu would mount as /media/Allison_Pen_Drive/), OS X will mount that as /Volumes/Allison_Pen_Drive/ when you plug it in.
If you had a second partition, or a second internal drive, called, say, Fatso (a little in-joke for Allison), OS X would mount that as /Volumes/Fatso/.
Likewise, if you double-clicked on a DMG file you downloaded from the net, say with the Adium installer, OS X would mount that as something like /Volumes/Adium/ until you eject the DMG.
The ‘disks’ listed in the Finder sidebar in the section headed Devices are just links to the contents of /Volumes/.
You can see this for yourself by opening a Finder Window and either hitting the key-combo ⌘+shift+g, or navigating to in the menubar to bring up the Go To Folder text box, and then typing the path /Volumes and hitting return.
OS X’s greatly simplified handling of mount points definitely makes OS X less confusing, but, the simplicity comes at a price. If you DO want to do more complicated things like having your home folders on a separate partition, you are stepping outside of what Apple considers the norm, and into a world of pain. On Linux/Unix separating out home folders is trivial, on OS X it’s a mine-field!
We’ll leave it here, for now, next time we’ll learn how to navigate around a Unix/Linux/OS X filesystem.
TTT Part 4 of n — Navigation
In the previous segment, we discussed the concept of a file system in detail.
We described how filesystems contain folders which contain files or folders, and we
described the different ways in which Windows and Linux/Unix/OS X combine all the
filesystems on our computers into a single name-space, within which every file has a
unique ‘path’ (F:\myFolder\myFile.txt -v- /Volumes/myThumbDrive/myFolder/myFile.txt).
In this instalment, we’ll look at how to navigate around the Unix/Linux/OS X filesystem in a Bash command shell.
Listen Along: Taming the Terminal Podcast Episode 4
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Navigating around
Two instalments ago we learned that, just like a Finder window, a command prompt is ‘in’ a single folder/directory at any time.
That folder is known as the current working directory or the present working directory.
Although the default Bash command prompt on OS X will show us the name of our current folder, it doesn’t show us the full path.
To see the full path of the folder you are currently in, you need the pwd (present working directory) command.
This is a very simple command that doesn’t need any arguments.
When you open an OS X Terminal, by default your current working directory will be your home directory, so, if you open a Terminal now and type just pwd you’ll see something like:
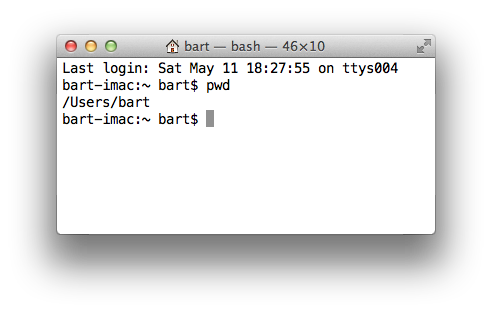
Knowing where you are is one thing, the next thing you might want to do is look around to see what’s around you, and for that, you’ll need the ls (list) command.
If you run the command without any arguments you’ll see a listing of all the visible files and folders in the current directory. On OS X, this default view is annoying in two ways. Firstly, you’ll see your files and folders spread out over multiple columns, so scanning for a file name alphabetically becomes annoyingly confusing, especially if the list scrolls. Secondly, on OS X (though not on most Linux distros), you won’t be able to tell what is a file and what is a folder at a glance, you’ll just see names, which is really dumb (even DOS does a better job by default!).
You can force ls to display the contents of a folder in a single column in two ways.
You can either use the -l flag to request a long-form listing, showing lots of metadata along with each file name, or, you can use the -1 flag to specify that you just want the names but in a single column.
For now, most of the metadata shown in the long-form listing is just confusing garbage, so you are probably better off using -1.
If you do want to use the long-form listing, I suggest adding the -h flag to convert the file size column to human-readable file sizes like 100K, 5M, and 64G.
I’ve trained myself to always use ls -lh and never to use just ls -l.
You have two options for making it easy to distinguish files from folders in the output from ls on OS X.
You can either use the -F flag to append a / to the end of every folder’s name, or, the -G flag to use colour outputs (folders will be in blue).
The -F flag will work on Linux and Unix, but the -G flag is a BSD Unix thing and doesn’t work on Linux.
Linux users need to use the more logical --color instead.
I said that ls shows you all the visible files in your current directory, what if you want to see all the files, including hidden files?
Simple, just use the -a flag.
Finally, before we move away from ls (for now), I should mention that you can use ls to show you the content of any folder, not just the content of your current folder.
To show the content of any folder or folders, use the path(s) as regular arguments to ls.
E.g.
to see what is in your system-level library folder you can run:
ls -1G /LibraryNow that we can see where we are with pwd, and look around us with ls, the next obvious step is moving around the filesystem, but, we need to take a small detour before we’re ready to talk about that.
In the last instalment, we talked about file paths like the imaginary file on Allison’s thumb drive with the path /Volumes/Allison_Pen_Drive/myFolder/myFile.txt.
That type of path is called an absolute path and is one of two types of path you can use as arguments to Linux/Unix commands.
Absolute paths (AKA full paths) are like full addresses, or phone numbers starting with the + symbol, they describe the location of a file without reference to anything but the root of the filesystem.
They will work no matter what your present working directory is.
When you need to be explicit, like say when you’re doing shell scripting, you probably want to use absolute paths, but, they can be tediously long and unwieldy.
This is where relative paths come in, relative paths don’t describe where a file or folder is relative to the root of the file system, but, instead, relative to your present working directory.
If you are stopped for directions and someone wants to know where the nearest gas station is, you don’t give them the full address, you give them directions relative to where they are at that moment.
Similarly, if you want to phone someone in the same street you don’t dial + then the country code then the area code then their number, you just dial the number because, like your command shell is in a current working directory, your telephone is in an area code.
With phone numbers, you can tell whether something is a relative or an absolute phone number by whether or not it starts with a +.
With Unix/Linux paths the magic character is /.
Any path that starts with a / will be interpreted as an absolute path by the OS, and conversely, any path that does not begin with a / will be interpreted as a relative path.
If you are in your home folder, you can describe the relative path to your iTunes library file as Music/iTunes/iTunes\ Library.xml (note the backslash to escape the space in the path).
That means that your home folder contains a folder called Music, which contains a folder called iTunes, which contains a file called iTunes Library.xml.
Describing relative paths to items deeper in the file system hierarchy from you is easy, but what if you need to go the other way, not to folders contained in your current folder, but instead to the folders that contain your current folder?
Have another look at the output of ls -aG1 in any folder.
What are the top two entries?
I don’t have to know what folder you are in to know the answer, the first entry will be a folder called ., and the second entry will be a folder called .. which are the key to allowing relative paths that go up the chain.
The folder . is a hard link to the current folder.
If you are in your home folder, ls ./Documents and ls Documents will do the same thing, show you the contents of a folder called Documents in your current folder.
This seems pointless, but trust me, it will prove to be important and useful in the future.
For now, the more interesting folder is .., which is a hard link to the folder that contains the current folder.
I.e.
it allows you to specify relative paths that move back towards / from where you are.
In OS X, home directories are stored in a folder called /Users.
As well as one folder for each user (named for the user), /Users also contains a folder called Shared which is accessible by every user to facilitate easy local file sharing.
Regardless of your username, the relative path from your home folder to /Users/Shared is always ../Shared (unless you moved your home folder to a non-standard location of course).
.. means go back one level, then move forward to Shared.
You can go back as many levels as you want until you hit / (where .. is hard-linked to itself), e.g.
the relative path from your home folder to / is ../../.
Finally, the Bash shell (and all other common Unix/Linux shells) provides one other very special type of path, home folders.
We have mentioned in passing in previous instalments that ~ means ‘your home directory’.
No matter where on the filesystem you are, ~/Music/iTunes/iTunes\ Library.xml is always a relative path to your iTunes library file.
But, the ~ character does a little more than that, it can take you to ANY user’s home folder simply by putting their username after the ~.
Imagine Allison & Steve share a computer.
Allison’s username is allison, and Steve’s is steve.
Allison and Steve can each access their own iTunes libraries at ~/Music/iTunes/iTunes\ Library.xml, but, Allison can also access Steve’s at ~steve/Music/iTunes/iTunes\ Library.xml, and likewise, Steve can access Allison’s at ~allison/Music/iTunes/iTunes\ Library.xml (all assuming the file permissions we are ignoring for now, are set appropriately of course).
So — now that we understand that we can have absolute or relative paths, we are finally ready to start navigating the file system by changing our current directory.
The command to do this is cd (change directory).
Firstly, if you ever get lost and you want to get straight back to your home directory, just run the cd command with no arguments and it will take you home!
Generally, though we want to use the cd command to navigate to a particular folder, to do that, simply use either the absolute or relative path to the folder you want to navigate to as the only argument to the cd command and assuming the path you entered is free of typos, off you’ll go!
Finally, for this instalment, I just want to mention one other nice trick the cd command has up its sleeve, it has a (very short) memory.
If you type cd - you will go back to wherever you were before you last used cd.
As an example, let’s say you spent ages navigating a very complex file system and are now 20 folders deep.
You’ve forgotten how you got there, but you’ve finally found that obscure system file you need to edit to make some app do some non-standard thing.
Then, you make a boo-boo, and you accidentally type just cd on its own, and all of a sudden, you are back in your home folder.
Don’t panic, you won’t have to find that complicated path again, just type cd - and you’ll be right back where you were before you rubber-fingered the cd command!
That’s where we’ll leave things for this instalment. We now understand the structure of our file systems and how to navigate around them. Next time we’ll dive head-long into these file permissions we’ve been ignoring for the last two instalments.
For any Windows users out there, the DOS equivalents are as follows:
-
instead of
pwd, usecdwith no arguments -
instead of
ls, usedir(though it has way less cool options) -
cdiscd, though again, it has way fewer cool options
TTT Part 5 of n — File Permissions
In this instalment, it’s time to make a start on one of the most important Unix/Linux concepts, file permissions. This can get quite confusing, but it’s impossible to overstate the importance of understanding how to read and set permissions on files and folders. To keep things manageable, I’m splitting understanding and altering permissions into two separate instalments.
Linux and Unix (and hence OS X) all share a common file permissions system, but while they share the same common core, they do each add their own more advanced permissions systems on top of that common core. In this first instalment, we’re only going to look at the common core, so everything in this instalment applies equally to Linux, Unix, and OS X. In future instalments, we’ll take a brief look at the extra file information and permissions OS X associates with files, but we won’t be looking at the Linux side of things, where more granular permissions are provided through kernel extensions like SELinux.
Listen Along: Taming the Terminal Podcast Episode 5
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Files and permissions
Let’s start with some context. Just like every command shell has a present working directory, every process on a Linux/Unix system is also owned by a user, including shell processes. So, when you execute a command in a command shell, that process has a file system location associated with it and a username. By default your shell will be running as the user you logged into your computer as, though you can become a different user if and when you need to (more on that in future instalments). You can see which user you are running as with the very intuitive command:
whoamiSecondly, users on Unix/Linux systems can be members of one or more groups.
On OS X there are a number of system groups to which your user account may belong, including one called staff to which all admin users belong.
You can see what groups you belong to with the command:
groups(You can even see the groups any username belongs to by adding the username as an argument.)
On older versions of OS X creating your own custom groups was hard.
Thankfully Apple has addressed this shortcoming in more recent versions of the OS, and you can now create and manage your own custom groups in the Users & Groups preference pane (click the + button and choose group as the user type, then use the radio buttons to add or remove people from the group).
Unix/Linux file systems like EXT and HFS+ store metadata about each file and folder as part of that file or folder’s entry in the file system. Some of that metadata is purely informational, things like the date the file was created, and the date it was last modified, but that metadata also includes ownership information and a so-called Unix File Permission Mask.
There are two pieces of ownership information stored about every file and folder: a UID, and a GID. What this means is that every file and folder belongs to one user and one group.
In the standard Linux/Unix file permissions model there are only three permissions that can be granted on a file or folder:
-
Read (
r): if set on a file it means the contents of the file can be read. If set on a folder it means the contents of the files and folders contained within the folder can be read, assuming the permissions masks further down the filesystem tree also allow that. If you are trying to access a file, and read permission is blocked at even one point along the absolute path to the file, access will be denied. -
Write (
w): if set on a file it means the contents can be altered, or the file deleted. If set on a folder it means new files or folders can be created within the folder. -
Execute (
x): if set on a file it means the file can be run. The OS will refuse to run any file, be it a script or a binary executable, if the user does not have execute permission. When set on a folder, execute permission controls whether or not the user has the right to list the contents of a directory.
All permutations of these three permissions are possible on any file, even if some of them are counter-intuitive and rarely needed.
The Unix file Permission Mask ties all these concepts together.
The combination of the context of the executing process and the metadata in a file or folder determines the permissions that apply.
You can use the ls -l command to see the ownership information and file permission mask associated with any file or folder.
The hard part is interpreting the meaning of the file permission mask.
On standard Unix/Linux systems, this mask contains ten characters, though on OS X it can contain an optional 11th or even 12th character appended to the end of the mask (we’ll be ignoring these for this instalment).
The first character specifies the ‘type’ of the file:
-
-signifies a regular file -
dsignifies a directory (i.e. a folder) -
lsignifies a symbolic link (more on these in a later instalment) -
bcpandsare also valid file types, but they are used to represent things like block devices and sockets rather than ‘normal’ files, and we’ll be ignoring them in this series.
The remaining nine characters represent three sets of read, write, and execute permissions (rwx), specified in that order.
If a permission is present then it is represented by an r, w, or x, and if it’s not present, it’s represented by a -.
The first group of three permission characters are the permissions granted to the user who owns the file, the second three are the permissions granted to all users who are members of the group that owns the file, and the last three are the permissions granted to everyone, regardless of username or group membership.
To figure out what permissions you have on a file you need to know the following things:
-
your username
-
what groups you belong to
-
what user the file or folder belongs to
-
what group the file or folder belongs to
-
the file or folder’s permission mask
When you try to read the contents of a file, your OS will figure out whether or not to grant you that access using the following algorithm:
-
is the user trying to read the file the owner of the file? If so, check if the owner is granted read permission, if yes, allow to read, if no, continue.
-
is the user trying to read the file a member of the group that owns the file? If so, check if the group is granted read permission, if yes, allow read, if no, continue.
-
check the global read permission, and allow or deny access as specified.
Write and execute permissions are processed in exactly the same way.
When you see the output of ls -l, you need to mentally follow the same algorithm to figure out whether or not you have a given permission on a given file or folder.
The three columns to look at are the mask, the file owner, and the file group.
We’ll stop here for now.
In the next instalment, we will explain the meaning of the + and @ characters which can show up at the end of a file permission masks on OS X, and we’ll look at the commands for altering the permissions on a file or folder.
TTT Part 6 of n — More File Permissions
In the previous instalment of this series, we had a look at how standard Unix File Permissions worked. We looked at how to understand the permissions on existing files and folders, but not at how to change them. We also mentioned that the standard Unix file permissions are now only a subset of the file permissions on OS X and Linux (OS X also supports file ACLs, and Linux has SELinux as an optional extra layer of security).
In this instalment, we’ll start by biting the bullet and dive into how to alter standard Unix File permissions. This could well turn out to be the most difficult segment in this entire series, regardless of how big 'n' gets, but it is very important, so if you have trouble with it, please don’t give up. After we do all that hard work we’ll end with a simpler topic, reading OS X file ACLs, and OS X extended file attributes. We’ll only be looking at how to read these attributes though, not how to alter them.
Listen Along: Taming the Terminal Podcast Episode 6
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
As a reminder, last time we learned that every file and folder in a Unix/Linux file system has three pieces of metadata associated with it that control the standard Unix file permissions that apply to that file or folder. Files have an owner (a user), a group, and a Unix File Permission Mask associated with them, and all three of these pieces of information can be displayed with ls -l.
We’ll be altering each of these three pieces of metadata in this instalment.
Altering Unix File Permissions — Setting the File Ownership
The command to change the user that owns one or more files or folders is chown (change owner).
The command takes a minimum of two arguments, the username to change the ownership to, and one or more files or folders to modify.
E.g.:
chown bart myFile.txtThe command can also optionally take a -R flag to indicate that the changes should be applied ‘recursively’, that is that if the ownership of a folder is changed, the ownership of all files and folders contained within that folder should also be changed.
The chown command is very picky about the placement of the flag though, it MUST come before any other arguments E.g.:
chown -R bart myFolderSimilarly, the command to change the group that a file belongs to is chgrp (change group). It behaves in the same way as chown, and also supports the -R flag to recursively change the group.
E.g.:
chgrp -R staff myFolderFinally, if you want to change both user and group ownership of files or folders at the same time, the chown command provides a handy shortcut. Instead of passing just a username as the first argument, you can pass a username and group name pair separated by a :, so the previous two examples can be rolled into the one example below:
chown -R bart:staff myFolderAltering Unix File Permissions — Setting the Permission Mask
The command to alter the permission mask, or file mode, is chmod (change mode).
In many ways it’s similar to the chown and chgrp commands. It takes the same basic form, and supports the -R flag, however, the formatting of the first argument — the permission you want to set — can be very confusing.
The command actually supports two entirely different approaches to setting the permissions. I find both of them equally obtuse, and my advice to people is to pick one and stick with it. Long ago I chose the numeric approach to setting file permissions, so that’s the approach we’ll use here.
This approach is based on treating the three permissions, read, write, and execute as a three-digit binary number, if you have read permission, the first digit is a 1, if not, it’s a 0, and the same for the write and execute permissions.
So, the permissions rwx would be represented by the binary number 111, the permissions r-x by 101, and r-- by 100.
Since there are three sets of rwx permissions (user, group, everyone), a full Unix file permission mask is defined by three three-digit binary numbers.
Unfortunately, the chmod command doesn’t take the binary numbers in binary form, it expects you to convert them to decimal [1] first, and pass it the three sets of permissions as three digits.
This sounds hard, but with a little practice, it’ll soon become second-nature.
The key to reading off the permissions is this table:
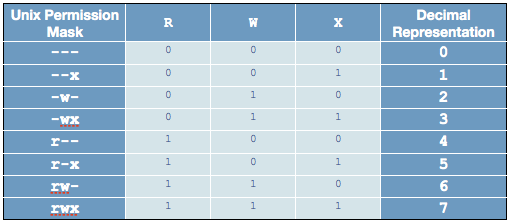
Rather than trying to memorise the table itself, you should try to learn the process for creating it instead.
The lighter coloured cells in the centre of the table are the important ones to be able to re-create on demand.
They are not random, they are a standard binary to decimal conversion table, and you should notice that the three columns have a distinct pattern. The right-most column alternates from 0 to 1 as you go down, the column second from the right has two 0s, then two 1s, then two 0s etc, and finally the third column from the right has four 0s, then four 1s.
If you wanted to convert a 4 digit binary number to decimal you would add a fourth column that has 8 0s then 1s, if you wanted to convert a 5-bit binary number you’d add yet another column where it’s eight 0s then eight 1s, and so on — each column you go to the left doubles the number of 0s and 1s before repeating.
If you can reproduce this table on demand you’ll have learned two things — how to do Unix file permissions, and how to convert any arbitrary binary number to decimal (though there are better ways if the binary number has many digits).
Even if you don’t want to learn how to create the table, you’ll probably still be fine if you remember just the most common permissions:
-
4= read-only -
5= read and execute -
6= read and write -
7= full access
If you run a website, for example, regular files like images or HTML pages and images should have permissions 644 (rw-r--r--: you get read and write, everyone gets read). Executable files and folders should have 755 (rwxr-xr-x: you get full permission, everyone can list the folder contents and read the files within).
Let’s end with a few examples. If you want to alter a file you own so that you have read, write and execute permission, but no one else can access the file in any way you would use the command:
chmod 700 myFile.txtIf the file should not be executable even by you, then you would use:
chmod 600 myFile.txtClearly, this is not intuitive, and it’s understandably very confusing to most people at first. Everyone needs to go over this a few times before it sinks in, so if it doesn’t make sense straight away, you’re not alone. Do please keep at it though, this is very important stuff.
Reading OS X File ACLs
We said last time that on OS X, a + at the end of a file permission mask signifies that the file has ACLs (access control lists) associated with it.
These ACLs allow more granular permissions to be applied to files on top of the standard Unix File Permissions.
If either the ACLs OR the standard Unix permissions deny you the access you are requesting, OS X will block you.
You can read the ACLs associated with files by adding the -le flags to the ls command.
If a file in the folder you are listing the contents of has file ACLs, they will be listed underneath the file, one ACL per line, and indented relative to the files in the list.
Each ACL associated with a file is numbered, and the numbering starts from 0.
The ACLs read as quite Englishy, so you should be able to figure out what they mean just by looking at them. As an example, let’s have a look at the extended permissions on OS X home directories:
bart-imac:~ bart$ ls -le /Users
total 0
drwxrwxrwt 10 root wheel 340 22 Feb 21:42 Shared
drwxr-xr-x+ 12 admin staff 408 26 Dec 2011 admin
0: group:everyone deny delete
drwxr-xr-x+ 53 bart staff 1802 13 Jul 14:35 bart
0: group:everyone deny delete
bart-imac:~ bart$By default, all OS X home folders are in the folder /Users, which is the folder the above commands lists the contents of.
You can see here that my home folder (bart) has one or more file ACLs associated with it because it has a + at the end of the permissions mask.
On the lines below you can see that there is only one ACL associated with my home folder and that it’s numbered 0.
The contents of the ACL are:
group:everyone deny deleteAs you might expect, this means that the group everyone is denied permission to delete my home folder.
Everyone includes me, so while the Unix file permissions (rwxr-xr-x) give me full control over my home folder, the ACL stops me deleting it.
The same is true of the standard folders within my account like Documents, Downloads, Library, Movies, Music, etc..
If you’re interested in learning to add ACLs to files or folders, you might find this link helpful: www.techrepublic.com/blog/mac/…
Reading OS X Extended File Attributes
In the last instalment, we mentioned that all files in a Linux/Unix file system have metadata associated with them such as their creation date, last modified date, and their ownership and file permission information. OS X allows arbitrary extra metadata to be added to any file. This metadata can be used by applications or the OS when interacting with the file.
For example, when you give a file a colour label, that label is stored in an extended attribute. If you give a file or folder a custom Finder icon, that gets stored in an extended attribute (this is how DropBox.app makes your DropBox folder look different even though it’s a regular folder.) Similarly, spotlight comments are stored in an extended attribute, and third-party tagging apps also use extended attributes to store the tags you associate with a given file (presumably OS X Mavericks will adopt the same approach for the new standard file tagging system it will introduce to OS X).
Extended attributes take the form of name-value-pairs.
The name, or key, is usually quite long to prevent collisions between applications, and, like plist files, is usually named in reverse-DNS order.
E.g., all extended attributes set by Apple have names that start with com.apple, which is the reverse of Apple’s domain name, apple.com.
So, if I were to write an OS X app that used extended file attributes, the correct thing for me to do would be for me to prefix all my extended attribute names with ie.bartb, and if Allison were to do the same she should prefix hers with com.podfeet.
(Note that this is a great way to avoid name-space collisions since every domain only has one owner.
This approach is used in many places, including Java package naming.)
The values associated with the keys are stored as strings, with complex data and binary data stored as 64bit encoded (i.e.
HEX) strings.
This means the contents of many extended attributes is not easily human-readable.
Any file that has extended attributes will have an @ symbol appended to its Unix file permission mask in the output of ls -l.
To see the list of the names/keys for the extended attributes belonging to a file you can use ls -l@.
You can’t use ls to see the actual contents of the extended attributes though, only to get their names.
To see the names and values of all extended attributes on one or more files use:
xattr -l [file list]The nice thing about the -l flag is that if the value stored in an extended attribute looks like it’s a base 64 encoded HEX string it automatically does a conversion to ASCII for you and displays the ASCII value next to the HEX value.
Apple uses extended attributes to track where files have been downloaded from, by what app, and if they are executable, and whether or not you have dismissed the warning you get the first time you run a downloaded file.
Because of this, every file in your Downloads folder will contain extended attributes, so ~/Downloads is a great place to experiment with xattr.
As an example, I downloaded the latest version of the XKpasswd library from my website (xkpasswd-v0.2.1.zip).
I can now use xattr to see all the extended attributes OS X added to that file like so:
bart-imac:~ bart$ xattr -l ~/Downloads/xkpasswd-v0.2.1.zip
com.apple.metadata:kMDItemDownloadedDate:
00000000 62 70 6C 69 73 74 30 30 A1 01 33 41 B7 91 BF D6 |bplist00..3A....|
00000010 37 DB A1 08 0A 00 00 00 00 00 00 01 01 00 00 00 |7...............|
00000020 00 00 00 00 02 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 13 |.....|
00000035
com.apple.metadata:kMDItemWhereFroms:
00000000 62 70 6C 69 73 74 30 30 A2 01 02 5F 10 39 68 74 |bplist00..._.9ht|
00000010 74 70 3A 2F 2F 77 77 77 2E 62 61 72 74 62 75 73 |tp://www.bartbus|
00000020 73 63 68 6F 74 73 2E 69 65 2F 64 6F 77 6E 6C 6F |schots.ie/downlo|
00000030 61 64 73 2F 78 6B 70 61 73 73 77 64 2D 76 30 2E |ads/xkpasswd-v0.|
00000040 32 2E 31 2E 7A 69 70 5F 10 2E 68 74 74 70 3A 2F |2.1.zip_..http:/|
00000050 2F 77 77 77 2E 62 61 72 74 62 75 73 73 63 68 6F |/www.bartbusscho|
00000060 74 73 2E 69 65 2F 62 6C 6F 67 2F 3F 70 61 67 65 |ts.ie/blog/?page|
00000070 5F 69 64 3D 32 31 33 37 08 0B 47 00 00 00 00 00 |_id=2137..G.....|
00000080 00 01 01 00 00 00 00 00 00 00 03 00 00 00 00 00 |................|
00000090 00 00 00 00 00 00 00 00 00 00 78 |..........x|
0000009b
com.apple.quarantine: 0002;51e18856;Safari;6425B1FC-1E4C-4DB1-BD0D-6161A2DE0593
bart-imac:~ bart$You can see that OS X has added three extended attributes to the file, com.apple.metadata:kMDItemDownloadedDate, com.apple.metadata:kMDItemWhereFroms and com.apple.quarantine.
All three of these attributes are base 64 encoded HEX.
The HEX representation of the data looks meaningless to us humans of course, but OS X understands what it all means, and the xattr command is nice enough to display the ASCII next to the HEX for us.
In the case of the download date, it’s encoded in such a way that even the ASCII representation of the data is of no use to us, but we can read the URL from the second extended attribute, and we can see that Safari didn’t just save the URL of the file (https://www.bartbusschots.ie/downloads/xkpasswd-v0.2.1.zip), but also the URL of the page we were on when we clicked to download the file (https://www.bartbusschots.ie/blog/?page_id=2137).
Finally, the quarantine information is mostly meaningless to humans, except that we can clearly see that the file was downloaded by Safari.
The xattr command can also be used to add, edit, or remove extended attributes from a file, but we won’t be going into that here.
Wrapup
That’s where we’ll leave things for this instalment. Hopefully, you can now read all the metadata and security permissions associated with files and folders in OS X, and you can alter the Unix file permissions on files and folders.
We’ve almost covered all the basics when it comes to dealing with files in the Terminal now. We’ll finish up with files next time when we look at how to copy, move, delete, and create files from the Terminal.
TTT Part 7 of n — Managing Files
So far in this series we’ve focused mostly on the file system, looking at the details of file systems, how to navigate them, and at file permissions and metadata. We’re almost ready to move on and start looking at how processes work in Unix/Linux/OS X, but we have a few more file-related commands to look at before we do.
In this instalment, we’ll be looking at how to manipulate the file system. In other words, how to create files and folders, how to copy them, how to move them, how to rename them, and finally how to delete them.
Listen Along: Taming the Terminal Podcast Episode 7
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Creating Folders & Files
This is one of those topics that I think is best taught through example, so let’s start by opening a Terminal window and navigating to our Documents folder:
cd ~/DocumentsWe’ll then create a folder called TtT6n in our Documents folder with the command:
mkdir TtT6nAs you can see, directories/folders are created using the mkdir (make directory) command.
When used normally the command can only create folders within existing folders.
A handy flag to know is the -p (for path) flag which will instruct mkdir to create all parts of a path that do not yet exist in one go, e.g.:
mkdir -p TtT6n/topLevelFolder/secondLevelFolderSince the TtT6n folder already existed the command will have no effect on it, however, within that folder it will first create a folder called topLevelFolder, and then within that folder, it will create a folder called secondLevelFolder.
At this stage let’s move into the TtT6n folder from where we’ll execute the remainder of our examples:
cd TtT6nWe can now use the -R (for recursive) flag for ls to verify that the mkdir -p command did what we expect it to. I like to use the -F flag we met before with -R so that folder names have a trailing / appended:
ls -RFWhen using ls -R the contents of each folder is separated by a blank line, and for folders deeper down than the current folder each listing is prefixed with the relative path to the folder about to be listed followed by a :.
In other words, we are expecting to see just a single entry in the first segment, a folder called topLevelFolder, then we expect to see a blank line followed by the name of the next folder to be listed, which will be the aforementioned topLevelFolder, followed by the listing of its contents, which is also just one folder, this time called secondLevelFolder.
This will then be followed by a header and listing of the contents of secondLevelFolder, which is currently empty.
Let’s now create two empty files in the deepest folder within our test folder (secondLevelFolder).
There are many ways to create a file in Unix/Linux, but one of the simplest is to use the touch command. The main purpose of this command is to change the last edited date of an existing file to the current time, but if you try to touch a file that doesn’t exist, touch creates it for you:
touch topLevelFolder/secondLevelFolder/file1.txt topLevelFolder/secondLevelFolder/file2.txtYou can use ls -RF to verify that these files have indeed been created (you can use the -lh flags along with the -RF flags to see that the files are indeed empty — i.e.
0 bytes in size).
ls -RFlhCopying Files/Folders
Let’s now create a second top-level folder, and copy the files to it:
mkdir topLevelFolder2
cp topLevelFolder/secondLevelFolder/file1.txt topLevelFolder2
cp topLevelFolder/secondLevelFolder/file2.txt topLevelFolder2As you can see, the command to copy a file is cp.
Here we have used cp in its simplest form, with just two arguments, the first being what to copy, the second being where to copy it to.
The first argument must be a file and the last a folder.
The cp command is a cleverer than this though — it can take any number of arguments greater than two. All arguments but the last one will be treated as sources, and the last one will be treated as the destination to copy all these sources to.
So, we can re-write our two cp commands above as simply:
cp topLevelFolder/secondLevelFolder/file1.txt topLevelFolder/secondLevelFolder/file2.txt topLevelFolder2(You can verify that the copy has worked with the ls -RF command.)
We can be even more efficient though — we can use the shell’s wild card completion functionality to simplify things even further:
cp topLevelFolder/secondLevelFolder/*.txt topLevelFolder2Note that the cp command will happily work with either full or relative paths.
Also, you may remember that a few instalments back I mentioned that every folder contains a file called . that’s a reference to the folder containing it, and that while this sounds useless, it’s actually very useful.
Well, the cp command provides a great example to illustrate this point.
To copy a file to the folder you are currently in, you can use . as the destination path.
By default, cp will only copy files, but, it can copy folders (and their contents) if you use the -R (recursive) flag.
The flag should precede the argument list.
Let’s now create yet another empty folder and copy the folder secondLevelFolder, and all its contents, into the new folder:
mkdir topLevelFolder3
cp -R topLevelFolder/secondLevelFolder topLevelFolder3(Again, you can use ls -RF to verify that the copy has worked as expected.)
Moving Files/Folders
The mv (move) command works in a similar way to cp, but, it removes the source files and folders after it has copied them to the destination folder.
The mv command can move folders without needing to specify any flags.
As an example, let’s create yet another folder, and move our original secondLevelFolder and its contents to it:
mkdir topLevelFolder4
mv topLevelFolder/secondLevelFolder topLevelFolder4(Again, we can use ls -RF to verify that the folder and the files within it have indeed been moved.)
Users of DOS may remember that in DOS the commands to copy and move were simply copy and move, and, that there was a separate command to rename a file or folder which was simply rename.
Unix/Linux does not have a separate rename command, instead, you rename a file or folder by moving it from its old name to its new name.
As an example, let’s rename our first folder (topLevelFolder) to topLevelFolder0:
mv topLevelFolder topLevelFolder0We can use a simple ls command to verify that the folder has indeed been renamed.
Deleting Files & folders
Finally, I want to briefly mention the rm (remove) command, which can be used to delete files and/or folders.
The rm command simply takes the list of files to be nuked as arguments.
Unlike deleting files in the Finder, the rm command doesn’t have any kind of safety net — it does not use the recycle bin. If you mess it up, you’d better hope you have a recent backup because your files are GONE!
This is why I advise people to avoid using deleting files/folders from the command line unless you absolutely have to, or, are very comfortable on the Terminal.
It’s much safer to delete things in the Finder.
Whenever you do use the rm command, ALWAYS check over your command before hitting enter!
To adapt the older carpentry adage that you should always measure twice and cut once, my advice when using rm is to think twice and execute once.
By default, the rm command will only allow you to delete regular files, but if you add the -r flag it will delete folders and their contents too.
A great additional safety net when using rm either in recursive mode or with shell wild card completion is the use the -i flag to enter interactive mode — in this mode, you will be asked to confirm the deletion of each file and folder.
Let’s end by going back up one level, and then deleting our digital playpen recursively:
cd ..
rm -ri TtT6nConclusion
Today we learned how to create files and folders with touch and mkdir, to copy files with cp, move and rename them with mv, and delete them with rm.
Next time we’ll move on to looking at how Unix/Linux/OS X handled processes.
TTT Part 8 of n — Processes
For various reasons, there’s been a bit of a gap between the previous instalment and this one. A big part of the reason is that I’d been putting off a lot of topics I wanted to talk about on Chit Chat Across the Pond until there was a logical break in this Terminal series. Having finished with the file system at the end of part 7, I had my logical breakpoint. Now it’s time to get stuck back in though, and start a whole new topic — processes.
We’ll start with a little history for context, then have a look at the model OS X uses to represent processes and finish by looking at some commands for listing the currently-running processes on your system.
Listen Along: Taming the Terminal Podcast Episode 8
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
A Little History for Context
We now live in a world where multitasking is a normal and expected part of our computing experiences, be that on our servers, desktops, laptops, tablets, or phones. Multitasking is not something that comes naturally to our computers though. Until relatively recently, our home computers had a single CPU that could execute only a single task at a time. Or, in computer-science-speak, our computers could only execute a single simultaneous thread of execution. In the days of DOS that was true of the hardware as well as the software. You booted DOS, it then handed control over to the program you launched with it, which then had full control of your computer until it exited and handed control back to DOS. You could not run two programs at the same time.
Many of us got our first introduction to the concept of multitasking with Windows 3.1. Windows ran on the same single-CPU hardware as DOS, so how could it do many things at once on hardware that could only do a single thing at a time? Well, it didn’t, it just looked like it did. Even back in the early 90s, our computers were doing millions of calculations per second, so the way Windows 3.1 did multitasking was through a software abstraction. Every task that wanted to use the CPU was represented in software as a “process”. This representation could store the entire CPU-state of the thread of execution, allowing Windows to play and pause it at will. A few thousand times a second, Windows would use hardware interrupts to wrest control of the CPU from the running process, take a snap-shot of its state, save it, then load the last saved state of the next process in the queue, and let it run for a bit. If you had 10 processes and a 1 MHz CPU, then each process got about 100,000 CPU cycles to work with per second, enough to give you the impression that all your programs were all running at the same time.
Our modern hardware can do more than one thing at once, even on many of our phones. Firstly, modern CPUs are hyper-threaded. That means that they support more than one thread of execution at the same time on a single CPU (more than 1 does not mean 100s, it usually means two). Secondly, many of our CPUs now have multiple cores on the same piece of silicon. This means that they are effectively two, or even four, CPUs in one, and each one of those cores can be hyper-threaded too! Finally, many of our computers now support multiple CPUs, so if you have four quad-core multi-threaded CPUs (like the much-loved octo-macs), you have the ability to execute 4x4x2, i.e., 32 threads, at the same time. Mind you, your average Mac has many fewer than that; a dual-core hyper-threaded CPU is common, giving you ‘just’ four actually simultaneous threads of execution.
Clearly, being able to run just 4 processes at the same time is just not enough, hence, even our modern computers use the same software trick as Windows 3.1 to appear to run many tens or even hundreds of processes at the same time.
There is literally an entire university semester of material in designing strategies for efficiently dividing up available CPU-time between processes. All we’ll say on the topic for now, is that the OS gets to arbitrate which process gets how much time, and that that arbitration is a lot more involved than a simple queuing system. The OS can associate priorities with processes, and it can use those priorities to give some processes preferential access over others.
We should also clarify that there is not a one-to-one mapping between processes and applications. Each app does have at least one process associated with it, but once an app is running it can fork or spawn as many child processes as it wants/needs. You could imagine a word processing app having one process to deal with the UI and another separate process for doing spell checking simultaneously in the background.
We should also note that on modern operating systems there are two broad classes of processes, those used by the OS to provide system services (often referred to as system processes), and those instigated by users to do tasks for them (often called user processes). There is no fundamental difference between these two groups of processes though, it’s just a taxonomy thing really. If you boot up your Mac and leave it at the login screen, there will already be tens of system processes running. Exactly how many will vary from user to user depending on how many or few services are enabled.
Finally, we should note that not all running processes are represented in the UI we see in front of us. When we launch an app there is a clear mapping between the process we started and one or more windows on our screen or icons in our menubar, but there are many processes that don’t have any windows, don’t show up in the dock, and don’t have an icon in the menubar. These hidden processes are often referred to as background processes.
Unix/Linux/OS X Processes
Each running process on a Unix/Linux/OS X computer has an associated process ID or PID.
This is simply an integer number that the OS uses to identify the process.
The very first process (the OS kernel), gets the PID 0, and every process that starts after that gets the next free PID.
On Linux systems, the process with the PID 1 is usually init, which is the process Linux uses to manage system services, so the Kernel will start init which then starts all the other system processes.
OS X uses the same idea, but instead of using init, it uses something called launchd (the launch daemon) to manage system processes.
If your system has been running for a long time it’s normal to see PIDs with 5 digits or more.
As well as having a PID, each Linux/Unix/OS X process (except for the kernel), also has a reference to the process that started it, called a Parent Process ID, or a PPID. This gives us the concept of a hierarchy of processes, with the kernel at the top of the pyramid.
As well as a PID and PPID, each process also runs as a particular user. Whether a given file can or can’t be accessed by a given process is determined by the user the process is running as, and the permissions set on the file.
Now it’s time to open up the Terminal and get stuck in with some real-world commands.
Some Terminal Commands
Let’s start with the most basic process-related command, ps, which lists running processes.
Note that ps is one of the few basic terminal commands that behave differently on Linux and Unix.
On a Mac, if you run the ps command without arguments, all that will be listed are the terminal-based processes owned by the user running the shell.
In all likelihood, all you’ll see is just a single bash process, which is your current shell (if you have multiple Terminal windows/tabs open you’ll probably see a bash processes for each one).
The columns you’ll see listed are PID (process ID), TTY (ignore this for now, it’s not really relevant on modern computers), TIME (how much CPU time the process is currently using), and CMD, the running command (including arguments if any).
Most of the time, the output of ps without arguments is of little to no interest. you need to use one or more arguments to get anything useful from ps.
Let’s start by listing all the processes owned by a given user, regardless of whether or not they are terminal-based processes:
ps -u [username]e.g.
ps -u allisonIf you’re a big multitasker like me, you may be surprised by just how many processes you have spawned. If you use Chrome as your browser you may also notice that it uses a separate process for each open tab.
Something else you’re likely to want to do is to see all current processes, regardless of who they belong to.
On Linux, we would do that with the -e (for everyone) flag, while on Unix we would do that with the -A (for ALL) flag.
OS X conveniently supports both, so just use whichever one you find easiest to remember.
ps -eor
ps -AAt this stage, you’ll be seeing a very long list, but for each entry, all you’re seeing is the standard four headers.
You’re viewing the list of all processes for all users, but there is no column to tell you which process belongs to which user!
For this list to be useful you need to ask ps to give you more information about each process.
Your first instinct might well be to try the -l flag in the hope that ps behaves like ls.
Give it a go:
ps -elAs you can see, you now get much more information about each process, but it’s not actually particularly useful information!
While giving you too much irrelevant information, -l doesn’t actually give you all the information you probably do want.
For example, -l gives the UID number of the user who owns the process, rather than the username.
A better, though still imperfect, option is the -j flag (no idea what it stands for).
Try it:
ps -ejThis still gives you more information than you need, but it does at least give you usernames rather than UIDs.
Thankfully there is a better option, you can use the -o flag to specify the list of headings you want in the output from ps.
To see a list of all the possible headings, use:
ps -LTo specify the headings you want, use the -o flag followed by a comma-separated list of headings without spaces after the commas.
In my opinion, the following gives the most useful output format:
ps -e -o user,pid,%cpu,%mem,commandFinally, you can also use flags to sort the output in different ways.
Of particular use are -m to sort by memory usage, and -r to sort by CPU usage.
ps -er -o user,pid,%cpu,%mem,command
ps -em -o user,pid,%cpu,%mem,commandThe ps command is a good way to get an instantaneous snapshot of the processes running on your system, but usually, what you really want is a real-time sorted list of processes, and for that, we have the top command:
topYou’ll now see real-time statistics on memory and CPU usage as well as a list of your top processes.
On most Linux distributions the default sorting for top is by CPU usage, which is actually very useful, but Apple didn’t think like that. Instead, Apple chose a default sort order of descending PID, i.e.
the most recently started processes.
You can either re-sort after starting top by hitting o and then typing something like -cpu (for descending CPU sorting), or -vsize (for descending memory usage), and hitting enter.
Or, you can pass the same arguments when starting top from the command line:
top -o -cpu
top -o -vsizeFinally, to exit out of top just type q.
When looking at top, a very important thing to look at is the so-called load averages, which are shown in the metadata above the process list at the top of the top screen.
There will be three of them, the first is the average over the last minute, the second is the average over the last 5 minutes, and the third is the average over the last 15 minutes.
The actual definition of the load average is a bit esoteric, so we’re not going to go into it here.
What you should know is that the load average is a pretty good metric for the amount of stress a computer is under.
If any bottleneck starts to slow processes down, the result will be increased load averages.
If your CPU is stressed, load averages will go up, if you’ve run out of RAM and your system is having to do a lot of swapping, load averages will go up, if you’re doing a lot of IO and your disk is too slow to keep up, your load averages will go up.
The next obvious question is, how high a load average is too high? A good metric is that ideally none of your load averages should cross the number of logical CPUs you have during regular user.
|
You can find out how many effective CPUs you have with the command:
|
It’s OK for the 1-minute average to cross the number of CPUs you have occasionally, but if the 15-minute average crosses the number of CPUs you have when you’re not doing something unusually stressful like transcoding video, then your computer is probably in need of an upgrade.
Clearly, ps and top can give you a lot of information about the processes that are running on your system, but they are both quite clunky because to get the most out of them you have to use a lot of flags.
On OS X, a much better choice is to use the built-in Activity Monitor app ().
This will show you all the same information but in a nice easy-to-use GUI.
You can choose which processes you see with a drop-down at the top right of the window, and you can sort on any column by clicking on its header.
To visually see the hierarchy of processes, you can choose All Processes, Hierarchically from the drop-down.
Bear in mind though that this view is not good for sorting or filtering.
If you’re trying to figure out which apps are using the most CPU or RAM, it’s best to stick with the All Processes option.
Final Thoughts
So far we’ve looked at commands for listing processes. Next time we’ll move on to commands for interacting with processes, particularly, for stopping processes that are causing problems.
TTT Part 9 of n — Controlling Processes
In the previous instalment, we looked at how Unix-like operating systems such as Linux and Mac OS X represent processes. We then went on to look at the commands for listing running processes and filtering and sorting them in various ways. This time we’ll move on to controlling processes, specifically starting and stopping them.
Listen Along: Taming the Terminal Podcast Episode 9
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Starting Processes
Whether or not you think of it in this way, you’re always starting processes. Each time you launch an app, you’ve started a process. Also, each time you issue a command on the Terminal, you’re starting a process.
So far, each time we’ve started a process from the command shell, it’s been a so-called foreground process.
We enter the command, this starts a new process, and that new process gets control of our terminal until it finishes, at which time we get returned to the command shell.
When we run very simple commands like ps or ls, the processes take just milliseconds to run, so we don’t really notice that we lose our prompt for a moment while the new process takes charge, does its thing, and then hands control back.
However, sometimes you want to start a process from the command shell, and not have it take control of your Terminal. A good example might be using a command shell to start a GUI app. You want the app to start, and to stay running, but you also want your command prompt back! We can do this using something called a background process. Should that process produce any text output, it will still show in our Terminal window, but as soon as we hit enter we’ll have our command prompt back.
Backgrounding a process is actually very easy to do, just add an & to the end of the command, and it will start in the background!
Let’s illustrate this with a quick example. For this to work you’ll need to be on OS X, have FireFox installed, and have it not be running when we start.
First, let’s start FireFox from the Terminal as a regular foreground process:
/Applications/Firefox.app/Contents/MacOS/firefox-binYou’ll see that the FireFox GUI launches as normal and that it outputs some information on what it’s doing to the Terminal. You’ll also notice that you have lost your command prompt. You can hammer the enter key all you want, but you’re not getting that command prompt back until the FireFox process exits and hands control back to your command shell. Go ahead and do that through the GUI as normal. Notice how the moment FireFox quits you get your command prompt back.
Now, let’s start FireFox as a background process:
/Applications/Firefox.app/Contents/MacOS/firefox-bin &The FireFox GUI will start just like before, and the same debugging information will be displayed in the Terminal window, but this time you just have to hit enter to get your command prompt back. Firefox is still running, but you have your command prompt back.
If you scroll up you’ll see that the very first piece of output when you ran the command was a line consisting of a number in square brackets, followed by another number, something like: [1] 1714
The number in square brackets is a counter for the number of background processes the current command shell is running, and the second number is the PID of the new background processes, in this case, FireFox’s PID.
|
You can use a command prompt to quickly check your FireFox version number without even having to launch the FireFox GUI with: Also, when you launch FireFox from a command shell you can pass it flags and arguments to alter its behaviour, for a list of valid options run: |
On Unix and Linux it’s normal to launch GUI apps from the command line by backgrounding them, and as you can see, it works on the Mac too.
However, the Mac has another, better, way of opening things from the command line that other versions of Linux and Unix don’t have: the open command.
The best way to think of open is as the command-line equivalent of double-clicking something in the Finder.
When you pass open one or more files as arguments it will open those files using the default app for their file type. As an added bonus, it will automatically background any apps it starts, so you don’t even have to remember the &!
Note that if you pass open a folder rather than a file it will open the folder in a new Finder window.
A very handy trick is to use open to get a Finder window showing the contents of your command shell’s present working directory as follows:
open .Another useful tip is to use open to quickly view hidden folders in the Finder.
On recent versions of OS X, where the Library folder is hidden, I often use:
open ~/LibraryAs well as opening things with the default app for their type, open can also open files or folders with any other app that supports the given type.
The -a flag allows you to specify the app the item should be opened with.
I do a lot of Perl programming, and I have two apps installed that I regularly use to edit Perl code.
I have OS X configured to open .pl and .pm files with Komodo Edit by default.
Komodo Edit is a nice free Perl IDE, and I do all my big programming jobs in it.
However, being a big IDE, it’s a bit of a hog — it takes so long to open that it has a splash screen!
So, when I just want to make a quick edit, I prefer to use the light-weight Smultron editor instead.
I can use open with the -a flag to specify that I want my Perl file opened with Smultron using a command something like:
open my_perl_file.pl -a /Applications/Smultron\ 5.app/Similarly, if I was using a computer that didn’t have Smultron installed I could open the Perl file with TextEdit using a command like:
open my_perl_file.pl -a /Applications/TextEdit.app/That’s all we really need to know about starting processes, so let’s move on to ending them.
Ending Processes
The command to quit a process is kill, which sounds very draconian indeed.
Despite how scary it sounds, you don’t have to be overly afraid of it, because if used without flags, all it does is politely ask the process if it would please quit.
In other words, it’s the command-line equivalent of
⌘+Q
or selecting Quit from an app’s menu.
The kill command needs at least one argument: the PID of the process you’d like to end.
This is where the ps and top commands we learned about last time come in very handy (or indeed the Activity Monitor app if you are on a Mac).
Note that you can use kill to end as many processes at once as you like; just keep adding more PIDs as arguments.
Let’s work through another example, using FireFox again. We’ll start by opening FireFox and backgrounding it with:
/Applications/Firefox.app/Contents/MacOS/firefox-bin &Before we can quit FireFox with the kill command we need to know its PID.
We can either scroll up and read it from the first line of output or, we can use the ps command to get it.
Since we started FireFox from the terminal, it will show up when we use ps without any arguments at all.
Once you have the PID you can quit FireFox with (replacing [the_PID] with the actual PID of course):
kill [the_PID]You should see FireFox exit, and the next time you hit enter on your Terminal you should see a message telling you that a process you started and backgrounded has ended.
Finding PIDs can be a bit of a pain, so you’ll be happy to know that you don’t have to!
There is another command for ending processes that uses process names rather than PIDs, it’s the even more scary-sounding killall command.
For what seems like the millionth time today, let’s start FireFox and background it:
/Applications/Firefox.app/Contents/MacOS/firefox-bin &Rather than looking up its PID, let’s now exit it with the killall command:
killall firefox-binNote that you need to be careful with killall because, as its name suggests, it will kill ALL processes with a given name, not just one!
Dealing with Stubborn Processes
Up until now, we’ve been polite, and we’ve used kill and killall to ask processes to please quit themselves.
When an app crashes or hangs, that won’t get you very far.
If the app is so messed up it can’t deal with mouse input anymore, it’s also not going to respond when kill or killall politely ask it to stop.
When this happens, it’s time to bring out the big guns!
Both kill and killall take an optional argument -KILL, which tells kill/killall to instruct the OS to terminate the process, rather than asking the process to terminate itself.
ONLY DO THIS AS A LAST RESORT, YOU CAN LOSE UNSAVED DATA THIS WAY!
Note that on older Unix systems killall didn’t exist at all, and kill only took numeric arguments.
The old numeric equivalent of -KILL is -9, and both kill and killall on OS X (and Linux) will accept this old-fashioned flag as well as the more modern -KILL.
Before we finish I want to reiterate how important it is to always try kill and killall without the -KILL option first.
Think of it this way, it’s basic good manners to ask the process to please leave before you call the bouncers over to eject it!
Next Time …
We’ll be revisiting processes again later in the series, but we’re done with them for now.
In the next instalment, we’ll be taking a look at the built-in manual that comes with every Unix/Linux OS, including Mac OS X. You don’t need a book to tell you what flags or arguments a command expects, or what exactly they mean, you can find it all out right from the command shell, even if it takes a little practice to learn to interpret the information.
TTT Part 10 of n — man
Like with so many things in tech, it doesn’t matter if you don’t know everything. What matters is that you have the skills to quickly find the information you need when you need it. Programmers don’t memorise entire APIs, they simply learn how to search them, and how to interpret the results of their searches.
This is an area where the Linux/Unix command-line environment really shines. All Linux & Unix distributions, including OS X, have a built-in manual that allows you to quickly find the documentation you need, when you need it. Every command-line command/program can add its documentation to the system manual. In fact, each command/program can actually add multiple documents to the manual. Tools that make use of configuration files will often add a separate document to describe the structure of the configuration file for example.
Every built-in command will have an entry in the manual, and any software you install via the standard package management tools for your distribution will almost certainly bundle the related manual entries as part of the package.
This is also true on OS X, where package mangers like Mac Ports will also bundle manual pages with the software they install, and even stand-alone .pkg installers for command-line tools will usually also install manual entries.
If you run it from the command line, the chances are very high that there will be a manual entry for it on Linux, Unix and OS X.
Listen Along: Taming the Terminal Podcast Episode 10
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
I’m getting tired of typing ‘manual entry’, so let’s introduce a little jargon.
The command to read a manual entry is man, so command-line aficionados will almost always refer to manual entries simply as man pages. I’m going to do the same from here on.
In theory, the authors of man pages are free to write in any style they wish and to organise their pages into any structure they see fit. Thankfully, a very strong convention has established itself, so just about every man page in existence is written in the same style and organised in approximately the same way. Initially, you’ll find the style odd, and perhaps even off-putting, but you’ll soon get used to it. Sadly there is no shortcut — the only way to get good at reading man pages, is to read man pages!
Navigation
Let’s start with the practicalities of opening, closing, and navigating a man page before we look at the structure and formatting.
To open a man page simply use the man command with a single argument, the name of the command or config file you would like to read the entry for.
As an example, let’s call up the documentation for the ls command:
man lsYou’ll immediately notice that you’ve lost your command prompt, and are viewing a text document in your terminal window. The most important thing to learn is how to exit out of the man page and get back to your command prompt. To get out, simply hit the q key (for quit)!
OK, now that we know to get back out, let’s re-open the man page for ls and have a look around.
You can navigate up and down in a man page with the up and down arrow keys. You can also scroll down a single line by hitting enter, or a whole page at once with the spacebar. To scroll up a whole page at once hit b (for back). You can also go back half a page with the u key (for up).
You can search in a document by typing / followed by your search pattern, and then hitting enter.
To get to the next result hit the n key (and to get to the previous result, Shift+n).
Structure
Now that we can navigate around, let’s have a closer look at the structure of a man page. The first thing to note is that each man page is divided into sections, which are labelled in all capitals, and their content is indented by one tab. Sections can contain sub-sections who’s content is indented by two tabs, and so on.
Just about every man page you’ll ever see will have the following three sections:
NAME — this will be the first section, and will simply contain the name of the thing the man page is documenting, perhaps with a very short description.
E.g.
the name section in the ls man page contains ls -- list directory contents.
SYNOPSIS — this is a very important section and one we’ll look at in a lot more detail below. This section uses a somewhat cryptic notation to describe the structure of the arguments a command expects.
DESCRIPTION — this is where the main body of the documentation will be contained. The description is usually the longest section by far, and often contains sub-sections. This is where you expect to find a list of all the options a command accepts and a description of what they do.
Just to reiterate, there is no formal structure every man page has to follow, but there are conventions, so most man pages will contain at least some of the sections listed below, in addition to the three above. A man page may contain custom sections though, so the list below is not exhaustive.
OVERVIEW — very long man pages sometimes contain a one-paragraph summary of what the command does between the SYNOPSIS and DESCRIPTION sections.
OPTIONS — more complicated commands may separate their list of command-line flags into a separate OPTIONS section immediately after the DESCRIPTION section.
EXAMPLES — many man pages contain annotated examples of how the command being documented can be used. If present, this is usually a very helpful section, and often worth jumping straight to.
TIPS — some man pages use this section to offer some useful advice to users.
SEE ALSO — this section is used to list related man pages, often describing related commands or associated configuration files.
FILES — if a command’s function is affected by one or more configuration files, the default file system locations for these files are often listed in this section.
E.g.
the FILES section from the ntpdate man page:
FILES
/etc/ntp.keys contains the encryption keys used by ntpdate.STANDARDS — if the command conforms to some kind of standard set out by some sort of standards authority (perhaps the IEEE or the ISO), then the relevant standards may be listed in this section.
E.g.
the STANDARDS section from the ls man page:
STANDARDS
The ls utility conforms to IEEE Std 1003.1-2001 (``POSIX.1'').DIAGNOSTICS — for now, you can probably ignore this section. If it’s present it contains information that’s usually only useful when writing or debugging scripts.
ENVIRONMENT — we haven’t discussed the command-line environment yet in this series, although it is next on the list. For now, you can ignore this section.
COMPATIBILITY — this section will only be present if the command has potential compatibility problems; perhaps it doesn’t quite comply with a standard or something like that.
LEGACY DESCRIPTION — some commands have changed their behaviour over time. This section is where the old behaviours will be documented. This is really only useful when working with old scripts which might still be assuming the command’s old behaviour.
BUGS — if there are known problems with the command or known conditions which cause unusual or undesirable behaviour, they may be listed in this section.
HISTORY — this can be a fun section, and is usually very short, and details the origins of the command.
E.g.
the HISTORY section of the ls man page tells us that “An ls command appeared in Version 1 AT&T UNIX”.
AUTHOR — details the authors of the command being documented.
COPYRIGHT — the copyright information for the command being documented.
Understanding the SYNOPSIS Section
When you’re first learning about a command, the DESCRIPTION section is probably the most useful to you, but when it comes to relearning something you were once familiar with, the SYNOPSIS section is often the most useful. Although it’s short, it’s very dense with information. However, to be able to extract the meaning from this short section you need to understand the meaning of the formatting:
BOLD TEXT — any text in bold should be entered verbatim
UNDERLINED /ITALIC — any text that is either in italics or underlined (depending on your version of man, usually underline in modern OSes) needs to be replaced with a real value as described by the text.
E.g.
file should be replaced with the path to an actual file.
… — anything followed by an ellipsis (three dots) can be optionally repeated
[] — anything contained within square brackets is optional
| — the pipe symbol should be read as ‘or’
Final Thoughts
The most important thing is not to be afraid of man pages. At first, they will seem archaic and confusing, but you’ll soon get used to their style, and you might even come to like it! There is no substitute for practice though — the only way to learn to read man pages is to read man pages!
Finally, let’s end on a really bad nerd joke!
Q: How do you know women are more complicated than men?
A: Because you can man man, but you can’t man woman!
$ man woman
No manual entry for woman
$TTT Part 11 of n — Text Files
In the next instalment we’ll be moving on to look at the so-called Environment within a command shell, but before we do that we need to lay some groundwork. Specifically, we need to learn how to read and edit text files from the command line.
In this instalment, we’ll start with the most common commands for reading files, and then move on to look at the simplest of the command-line editors. For those interested in learning a little more I’ll also give a very quick overview of one of the more powerful command-line editors, but feel free to skip over that section if you like. Future instalments won’t assume that knowledge.
Listen Along: Taming the Terminal Podcast Episode 11
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Reading Text Files
The simplest command for dealing with text files is cat.
You can use cat to print the contents of a text file to the screen by calling it with one argument, the path to the text file you’d like printed out.
E.g., using cat to read the content of your computer’s network time configuration (definitely works on OS X, should work on most other Linux and Unix distros too):
cat /etc/ntp.confcat works great for short files, but it’s not well suited for reading longer files.
For example, using cat to show the config for man:
cat /etc/man.confWhile it’s useful to be able to print out the contents of a file, what would be much more useful is a command to allow us to read a file at our own pace. In Unix-speak, what we want is a pager.
Historically the pager of choice on Unix and Linux systems was more.
Like cat, you invoke more by passing it a file as an argument, but unlike cat, after more has printed a screen-full of text, it will stop.
You can then use the enter key or the down arrow key to move down one line at a time, or the spacebar to move down a whole screen at a time.
E.g.
more /etc/man.confWhile you’ll find more included in just about every modern Unix or Linux OS, it’s only there for legacy reasons.
more has been superseded by a newer and more feature-rich pager, which is humorously called less (because we all know less is more).
We’re actually already familiar with less because it’s the pager used by the man command.
All the commands we learned in the previous instalment for navigating around man pages are actually commands for navigation around text files with less!
The less command is invoked in the same way as cat and more, e.g.:
less /etc/man.conf|
On OS X |
The less command is very powerful, and it can deal with very large files without getting bogged down. As an example, most Linux and Unix distributions contain a dictionary file, usually located at /usr/share/dict/words.
This file is 235,886 lines long on OS X, and less has no problems searching or navigating it:
less /usr/share/dict/wordsWhile less is, without doubt, the best pager on modern Unix/Linux systems, and while it should be your command of choice for reading most text files, there is another pair of text-file-related commands every command-line user should know — head and tail.
The head and tail commands really come into their own when it comes to dealing with log files.
The head command will show you the first 10 lines of a file, and the tail command the last 10.
Simply using head and tail on a log file will quickly answer a very simple but very important question — what date range does my log file span?
(Note — Linux and most Unix users will find the system log at /var/log/messages, OS X is unusual in storing its system log in system.log)
head /var/log/system.log
tail /var/log/system.logBoth head and tail can actually show any number of lines at the beginning or end of a file by using a rather strange flag, - followed by an integer number.
E.g.
to see the last 50 lines of the system log use:
tail -50 /var/log/system.logOr, to see just the first line use:
head -1 /var/log/system.logFinally, the tail command has one more very useful trick up its sleeve, it can continue to print out new lines at the end of a file in real-time as they are added.
This is perfect for monitoring log files while you’re troubleshooting.
To enter this real-time mode invoke tail with the -f flag.
Remember that the only way out of a tail -f is with Ctrl+c.
You could run the command below to get a live view of the system log, but it’s hard to force log entries to appear there. On OS X, a nice example to use is the WiFi log file. If you run the command below in a Terminal window and then switch networks, you should see entries appear in the log file in real-time:
tail -f /var/log/wifi.logEditing Files — The Easy Way
You can roughly divide the command-line text editors into two categories, the quick and simple editors, and the power editors. The simpler editors are much easier to learn but much less powerful. If you spend a lot of time on the command line, learning at least one of the power editors is worth the effort in my opinion.
Anyway, let’s start simple.
There are two common, quick and simple command-line text editors, pico and nano, and the chances are very high that no matter what modern Linux or Unix OS you are using, one of these two will be available.
(OS X comes with nano, but like with more, it pretends to have pico too, until you run pico --version when it fesses up to really being nano.)
Once opened pico and nano are virtually indistinguishable anyway, so which you have really doesn’t matter.
If you want to edit an existing file, you invoke nano (or pico) with the path to the file you want to edit.
If you want to create a new file, you invoke nano with the path you’d like the new file to be created at.
Let’s play it safe and start a new file for our experimentations:
nano ~/Documents/nanoTest.txt(On OSes other than OS X use nano ~/nanoTest.txt instead.)
Once in nano, you’ll see a cursor where you can start to type, and along the bottom a list of possible commands with their key combinations next to them (remember, ^ is short-hand for the Ctrl key).
Let’s keep this simple and just type the utterly clicheéd sentence:
Hello World!You’re probably guessing that to save a file you’d use some kind of save option, perhaps ^s, but that would be much too simple.
Instead, in nano-speak, you want to write the file out, so you use the command ^o.
After hitting Ctrl+o, nano will then show you the path it’s about to write the file to (which is editable should you change your mind about the destination of your edits.) When you’re happy with the path, you hit enter to actually save the file.
Note that if you try to exit nano without writing out first, nano will offer to save the file for you, so you can also save with the sequence ^+x, y, Enter.
At this stage, you actually have all the skills you’re likely to truly need, so feel free to tune out at this point. However, if you’re interested, I’m also going to give a very brief and very superficial overview of one of the two most popular modal editors.
A Quick Taste of Advanced Editing with vi — OPTIONAL
There are two leviathans in the command-line text editing world, and both have been around since the 1970s.
In nerd circles, your choice of text editor is about as polarising as the Republican and Democratic political parties in the US.
You almost never meet someone who excels at both of them, and every Unix nerd has their favourite of the two.
The two editors I’m talking about are Emacs and vi.
As it happens I’m a vi guy, so it’s vi that I’m going to give a quick overview of.
|
There are actually two major variants of |
The single most important thing to know about vi is that it is modal, that means that at any given time vi is in one mode OR another.
Specifically, vi is always in either insert mode OR command mode.
In insert mode, everything you type is entered into the file where the cursor is, and in command mode, nothing you type is entered into the file, and everything you type is interpreted as a command by vi.
This confuses the heck out of people, and it takes some getting used to!
You invoke vi in the same way you would nano, so for our example let’s do the following:
vi ~/Documents/viTest.txt(on OSes other than OS X use vi ~/viTest.txt instead)
When the file opens we are in command mode.
If we were editing a pre-existing file instead of creating a new one, we would be able to move the cursor around, but anything we type would be treated as a command by vi, not as input for the file.
Let’s start by switching from command mode into insert mode. To do this, hit the i key (i for insert). Notice that at the bottom of the screen it now says INSERT in all caps — you’ll always see this when you are in insert mode.
Let’s be boring and insert the same text as before:
Hello World!To get back out of insert mode you use the esc key. You’ll see that when you hit escape the INSERT at the bottom of the screen goes away and there is actually a prompt down there for you to enter commands into.
The most important commands to know are the following:
-
:w— write the current buffer to the file (i.e. save your changes) -
:q— quitvi
You can combine those commands into one, so to save and exit you would use the command :wq.
If you start hammering away on the keyboard in command mode, erroneously assuming you are in insert mode, it’s inevitable that you’ll accidentally invoke a command you REALLY didn’t want to invoke.
This is why the most important vi command to know after :wq is :q!, which is exit without saving (if you try :q without the ! when there are unsaved changes vi won’t let you exit).
So far this all sounds needlessly complex, so let’s step things up a gear, and start to make real use of the command mode in vi.
Let’s start by copying a line of text, or, in vi-speak, let’s yank a line of text.
While in command mode (hit esc to make double-sure), move the cursor (with the arrow keys) so it’s somewhere on the line that says ‘Hello World!’, then type yy.
You have now yanked the current line.
Now that we have a line yanked, we can paste a copy of it by hitting the p key (for put). You can keep hammering on the p key as often as you like to keep adding more copies of the line.
One of the things I like most about vi is that you can enter a number before many of the commands to repeat them that many times.
To put our yanked line 500 times the command is 500p.
Let’s say our aspirations have expanded, we’d like to greet the entire universes, not just the world!
We could make over 500 edits, or, we could ask vi to do a global find and replace for us with the command:
:%s/World/UNIVERSEYou can also use vi commands to navigate around a file.
E.g.
:n (where n is a number) will take you to the nth line.
So to get to the 25th line you would enter the command :25.
Similarly, $ jumps the cursor to the end of the current line, and 0 jumps the cursor to the start of the current line.
vi will of course also let you easily delete content.
To delete the current line just enter dd.
You can probably guess how to delete 400 lines in one go, it is of course 400dd.
To delete everything from the cursor to the end of the line enter D, and to delete one character use x.
One final thing to mention in this VERY brief overview is that there are multiple ways to enter into insert mode from command mode.
We already know that i will start you inserting at the cursor, but it’s often useful to start inserting one character after the cursor, which you do with a (for append).
You can also enter insert mode on a new blank line after the line containing the cursor with o (for open line).
Similarly, O opens a new line before the line with the cursor on it.
This is just the tip of the vi-iceberg, it can do much much more.
There are literally books written about it.
However, in my opinion once you understand the modal nature of vi, all you really need is a good cheat sheet to help you find the commands you need until they become second nature.
(I have a printout of the first diagram on this page hanging on my wall at work).
Final Thoughts
It’s very important to be able to read the content of text files from the command line, and also to be able to do at least basic edits from there.
Every command-line user needs to at least remember less and tail -f.
Every command-line user also needs to familiarise themselves with pico/nano at the very least.
If you spend a lot of time on the command line, I think it’s definitely worth investing the time to learn vi or Emacs.
TTT Part 12 of n — the Environment
Given the times we live in, the word ‘environment’ probably invokes images of polar bears and melting ice, but the Al Gore definition of the word ‘environment’ is a relatively recent narrow definition of a much broader word. The first definition of the word in the OS X dictionary is:
The surroundings or conditions in which a person, animal, or plant lives or operates.
In this instalment, we’ll introduce a digital extension of this concept — the digital conditions within which a process exists, and specifically, in which a Bash command shell exists. Although this might sound like a simple topic, there’s actually a lot to cover, so we’ll be spreading it out over a few instalments.
Listen Along: Taming the Terminal Podcast Episode 12
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
The Basic Environment
Although we’ve not used the word ‘environment’ before, we have already discussed some elements that make up a process’s environment. Specifically, we know that every process has a user ID associated with it (we say that every process runs as a user), and we have come across the concept of the present working directory. Both of these elements make up part of the basic environment that every process on your computer executes within, not just command shells. The third major pillar in the basic environment is environment variables. These are name-value pairs that can be accessed by running processes.
When one process starts another process, the child process inherits a copy of the parent process’s environment. The child process runs as the same user the parent process was running as, it starts with the same present working directory, and it gets a copy of all the environment variables that existed in the parent’s environment at the moment the child was spawned. The important thing to note is that child processes do not share a single environment with their parents, they get a duplicate that they are then free to alter without affecting the parent process’s environment. When a child process changes its present working directory, that has no effect on the parent process’s present working directory, and similarly, when a child process changes the value stored in a given environment variable, that has no effect on the value stored in the same environment variable within the parent process’s environment.
While all processes have access to a basic environment, command shells extend this basic foundation to provide a much richer environment for their users. Until now very little that we have looked at has been shell-specific, but that changes with this instalment. Each command shell gets to create its own environment and to define its own mechanisms for interacting with it. What works in Bash will not necessarily work in Ksh, Zsh, etc. In this series we’ll only be dealing with the default command shell on most modern Unix and Linux OSes (including OS X): Bash. Note that Bash is an extended version of SH, so what works in SH works in Bash, and much, though not all, of what works in Bash also works in SH.
Environment Variables
In this instalment, we’ll be focusing on Environment Variables, and specifically, how Bash interacts with them.
The command to list the names and values of all currently set environment variables is simply env (or printenv on some systems).
E.g.:
bart-imac2013:~ bart$ env
TERM_PROGRAM=Apple_Terminal
SHELL=/bin/bash
TERM=xterm-256color
TMPDIR=/var/folders/_8/s3xv9qg94dl9cbrqq9x3ztwm0000gn/T/Apple_PubSub_Socket_Render=/tmp/launch-MLs1hi/Render
TERM_PROGRAM_VERSION=326
TERM_SESSION_ID=7661AF3B-0D62-435F-B880-C5428000E9D8
USER=bart
SSH_AUTH_SOCK=/tmp/launch-hwTXSO/Listeners
__CF_USER_TEXT_ENCODING=0x1F5:0:2
PATH=/opt/local/bin:/opt/local/sbin:/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin
__CHECKFIX1436934=1
PWD=/Users/bart
LANG=en_IE.UTF-8
SHLVL=1
HOME=/Users/bart
LOGNAME=bart
_=/usr/bin/env
bart-imac2013:~ bart$env lists the environment variables one per line.
On each line, the name of the variable is the text before the first =, and the value is everything after it.
Some of these variables are purely informational, while others are used to effect how a process behaves.
Environment Variables & Bash Shell Variables
Bash, like every other process, has access to all the variables set within its environment.
However, Bash extends the concept and of variables into shell variables, of which the environment variables are just a subset.
Bash shell variables can be local to the shell, or can exist within the shell and the environment.
We already know that env lets us see all the environment variables which exist in our shell but there is another command to let us see all the variables in our shell, both those in the environment and the local ones, and that command is set.
To see all the shell variables that exist, call set with no arguments.
E.g.
bart-imac2013:~ bart$ set
Apple_PubSub_Socket_Render=/tmp/launch-MLs1hi/Render
BASH=/bin/bash
BASH_ARGC=()
BASH_ARGV=()
BASH_LINENO=()
BASH_SOURCE=()
BASH_VERSINFO=([0]="3" [1]="2" [2]="51" [3]="1" [4]="release" [5]="x86_64-apple-darwin13")
BASH_VERSION='3.2.51(1)-release'
CCATP=rocks
COLUMNS=80
DIRSTACK=()
EUID=501
GROUPS=()
HISTFILE=/Users/bart/.bash_history
HISTFILESIZE=500
HISTSIZE=500
HOME=/Users/bart
HOSTNAME=bart-imac2013.localdomain
HOSTTYPE=x86_64
IFS=$' \t\n'
LANG=en_IE.UTF-8
LINES=24
LOGNAME=bart
MACHTYPE=x86_64-apple-darwin13
MAILCHECK=60
OPTERR=1
OPTIND=1
OSTYPE=darwin13
PATH=/opt/local/bin:/opt/local/sbin:/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin
PIPESTATUS=([0]="0")
PPID=17153
PROMPT_COMMAND='update_terminal_cwd; '
PS1='\h:\W \u\$ '
PS2='> '
PS4='+ '
PWD=/Users/bart
SHELL=/bin/bash
SHELLOPTS=braceexpand:emacs:hashall:histexpand:history:interactive-comments:monitor
SHLVL=1
SSH_AUTH_SOCK=/tmp/launch-hwTXSO/Listeners
TERM=xterm-256color
TERM_PROGRAM=Apple_Terminal
TERM_PROGRAM_VERSION=326
TERM_SESSION_ID=41E9B4E3-BC9B-4FC0-B934-E2607FF6DC35
TMPDIR=/var/folders/_8/s3xv9qg94dl9cbrqq9x3ztwm0000gn/T/
UID=501
USER=bart
_=PATH
__CF_USER_TEXT_ENCODING=0x1F5:0:2
__CHECKFIX1436934=1
update_terminal_cwd ()
{
local SEARCH=' ';
local REPLACE='%20';
local PWD_URL="file://$HOSTNAME${PWD//$SEARCH/$REPLACE}";
printf '\e]7;%s\a' "$PWD_URL"
}
bart-imac2013:~ bart$If you compare the output of env and set you’ll see that every environment variable is a shell variable, but, there are many more shell variables than there are environment variables.
Remember, when a child process is created only the environment variables get copied into the child process’s environment, even if the child process is another Bash process.
Shell variables are local to a single command shell, hence they are often called local variables.
Shell variables can be used when invoking shell commands.
To access the content of a variable you use the $ operator.
When you enter $VARIABLE_NAME in the shell it will be replaced with the value of the variable named VARIABLE_NAME.
E.g.
to change to the Desktop directory in your home folder you could use:
cd $HOME/Desktopor (if you have a Mac configured in the default way)
cd /Users/$LOGNAME/DesktopWay back in the second instalment we discussed quoting strings in the shell, and we mentioned that there was a very important difference between using double and single quotes and that it would become important later. Well, this is where that difference becomes important.
If you use the $ operator within a string enclosed by double quotes the variable name will get replaced by the variable’s value, if you use it within a string contained within single quotes it will not!
This is why the following do work (this is an OS X-specific example):
cd $HOME/Library/Application\ Support
cd "$HOME/Library/Application Support"But the following does not:
cd '$HOME/Library/Application Support'Note that you can also inhibit the $ operator by escaping it with a \ character.
Hence, the following has exactly the same effect as the previous command:
cd \$HOME/Library/Application\ SupportSometimes when we type the $ symbol we mean the $ operator, and sometimes we just mean the character $.
If we mean the character, we have to inhibit the operator either by escaping it or by using single quotes around the string containing it.
Whenever you find yourself typing the $ character, pause and think which you mean before hitting Enter, and be sure you have it escaped or not as appropriate.
While we can list the values stored in all variables with set, it’s also helpful to know how to show the value stored in a single variable.
The easiest way to do this is to make use of the initially useless-seeming command echo.
All echo does is print out the argument you pass to it, so, a simple example would be:
echo 'Hello World!'This seems pretty dull, but, when you combine echo with the $ operator it becomes much more useful:
echo $LOGNAMEWe can even get a little more creative:
echo "I am logged in as the user $LOGNAME with the home directory $HOME"Now that we can use variables, let’s look at how we create them and alter their values.
You create variables simply by assigning them a value, and you alter their value by assigning them a new value.
The = operator assigns a value to a variable.
In our examples, we won’t use a variable set by the system, but we’ll create our own one called MY_FIRST_VAR.
Before we start, we can verify that our variable does not exist yet:
echo $MY_FIRST_VARNow let’s create our variable by giving it a value:
MY_FIRST_VAR='Hello World!'Now let’s verify that we did indeed initialise our new variable with the value we specified:
echo $MY_FIRST_VARNow let’s get a little more creative and change the value stored in our variable using values stored in two variables inherited from the environment:
MY_FIRST_VAR="Hi, my name is $LOGNAME and my home directory is $HOME"Because we used double quotes, it is the value stored in the variables LOGNAME and HOME that have been stored in MY_FIRST_VAR, not the strings $LOGNAME and $HOME.
At this stage our new variable exists only as a local shell variable, it is not stored in our process’s environment:
envThe export command can be used to 'promote' a variable into the environment.
Simply call the command with the name of the variable to be promoted as an argument, e.g.
to push our variable to the environment use:
export MY_FIRST_VARWe can now verify that we really have pushed our new variable to the environment:
envEnvironment Variables and subshells — OPTIONAL
As mentioned, when one process starts another, the child process inherits a copy of the parent’s environment. If a child makes a change to an environment variable, that change is not seen by the parent. We can illustrate this easily using what are called subshells.
When one Bash process starts another Bash process, that child process is called a subshell. The most common way to create a subshell is by executing a shell script. A shell script is simply a text file that contains a list of shell commands. While we won’t be looking at shell scripting in detail until much later in this series, we’ll use some very simple shell scripts here to illustrate how child processes inherit their parent’s environment.
Let’s start by creating a very simple shell script that will print the value of an environment variable:
nano ~/Documents/ttt12script1.shAdd the following into the file and then save and exit:
#!/bin/bash
echo "TTT_VAR=$TTT_VAR"|
The first line of this script is called the “shebang line”, and it tells Bash what interpreter it should use to run the file. If we were writing a Perl script instead of a Bash script we would start our file with the line:
|
Before we can run our new script we need to make it executable:
chmod 755 ~/Documents/ttt12script1.shThe environment variable TTT_VAR does not exist yet, so running our shell script:
~/Documents/ttt12script1.shwill return:
TTT_VAR=We can now give our variable a value:
TTT_VAR='Hello World!'And if we run our script again, we can see that it still does not print out the value because we have only created a local shell variable, not an environment variable:
TTT_VAR=Now let’s push our variable to the environment and run our script again:
export TTT_VAR
~/Documents/ttt12script1.shwill now return
TTT_VAR=Hello World!To prove that the subshell is working on a copy of the environment variable, let’s copy our first script and create a new script that alters the value of the variable:
cp ~/Documents/ttt12script1.sh ~/Documents/ttt12script2.sh
nano ~/Documents/ttt12script2.shUpdate the new script so it contains the following code, then save and exit:
1
2
3
4
5
6
#!/bin/bash
echo "Initially: TTT_VAR=$TTT_VAR"
echo "Altering TTT_VAR in script"
TTT_VAR='new value!'
echo "Now: TTT_VAR=$TTT_VAR"
Now run the following:
echo $TTT_VAR
~/Documents/ttt12script2.sh
echo $TTT_VARYou should get output that looks something like:
bart-imac2013:~ bart$ echo $TTT_VAR
Hello World!
bart-imac2013:~ bart$ ~/Documents/ttt12script2.sh
Initially: TTT_VAR=Hello World!
Altering TTT_VAR in script
Now: TTT_VAR=new value!
bart-imac2013:~ bart$ echo $TTT_VAR
Hello World!
bart-imac2013:~ bart$As you can see, the subshell inherited the value of the environment variable TTT_VAR, but changing it in the subshell had no effect on the value seen in the parent shell, even though it was exported to the child shell’s environment.
You might expect that this means that you can’t use scripts to build or alter your environment, but, actually, you can.
You just can’t do it by accident, you must be explicit about it and use the source command.
To see this in action run the following:
echo $TTT_VAR
source ~/Documents/ttt12script2.sh
echo $TTT_VARThis should give you output something like:
bart-imac2013:~ bart$ echo $TTT_VAR
Hello World!
bart-imac2013:~ bart$ source ~/Documents/ttt12script2.sh
Initially: TTT_VAR=Hello World!
Altering TTT_VAR in script
Now: TTT_VAR=new value!
bart-imac2013:~ bart$ echo $TTT_VAR
new value!
bart-imac2013:~ bart$What the source command does is to run each command in the shell script within the current shell’s environment, hence, all changes made within the script are made within the shell that executes the script.
As we’ll see in a future instalment, the source command plays a pivotal role in the initialisation of every Bash shell.
Conclusions
In this introductory instalment, we focused mainly on how processes inherit their environment, and on the concept of shell and environment variables, in particular how they are inherited, and how they can be accessed and altered.
In the next instalment, we’ll start by focusing on one of the most important environment variables of all — PATH.
We’ll also go on to look at how a new Bash shell assembles its environment, and how to make permanent customisations to that environment, including things like customising your shell prompt and creating command shortcuts called aliases.
TTT Part 13 of n — PATH
In the previous instalment, we introduced the concept of the command shell environment, and we looked in detail at how shell and environment variables work.
In this instalment, we’ll focus on probably the single most important environment variable, PATH.
We’ll look at what it does, how it’s initialised, and, in the process, we’ll learn how to make persistent customisations to our shell environment.
Listen Along: Taming the Terminal Podcast Episode 13
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
|
This instalment assumes you’re using Bash, if you’re on macOS Catalina or later you’re probably using Zsh, see the Introduction for more information on using Bash on newer Macs. |
Paths
So far in this series I have been a little loose with the term command, I’ve avoided putting too fine a point on exactly what a terminal command is, but we’ll remedy that today. If you remember right back to the second instalment, we said that when entering commands on the command line, the first word is the command, and the other words (separated by spaces) formed the arguments to that command. We spent a lot of time discussing the vagaries of quoting the arguments, but we didn’t discuss the command itself in any detail.
In Bash, when you enter a command, that command can actually be one of two things, a builtin Bash command, or, an executable file which Bash will execute for you.
You can see the list of builtin commands on BSD-style Unixes (including OS X) with man builtin.
On Linux, you need to navigate to the SHELL BUILTIN COMMANDS section of the VERY long Bash man page for the same information.
When you enter a command in Bash, the first thing it does is figure out whether or not the command is a builtin. If it is a builtin then Bash just does whatever it is you asked. Where things get interesting is when you enter a command that is not a builtin. What Bash does then is interpret the command as a request to run an executable file with that name. If Bash finds such a file it runs it, and if not, it gives an error like:
bart-imac2013:~ bart$ donky
-bash: donky: command not found
bart-imac2013:~ bart$The obvious question is, how does Bash find the executable files to run?
This is where PATH comes in.
Before we continue, let’s print out the current value of PATH with the echo command and $ operator we learned about in the previous instalment:
echo $PATHYou should see a value that looks something like the following (though yours may well be shorter, mine is extra long because I use MacPorts to install Linux command-line tools onto my Mac):
/opt/local/bin:/opt/local/sbin:/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/binThe value of PATH is a : delimited ordered list of folders.
Each time you enter a command that is not a builtin, what Bash does is search each of the folders listed in PATH in order until it finds an executable file with the name you entered.
The order is important, if two folders in your path contain files with the same names, it’s the files in the folders nearest the front of the list that will get executed.
|
Notice that the folder You can of course still run executable files in the present working directory on Unix/Linux, but you need to be explicit about it by prefixing the command with |
The which command can be used to show you which file will be executed when you use a given command, e.g.
which bash|
The location of common commands on the file system may seem random at first, but there is a logic to it. Firstly, commands regular users can run are usually in folders ending in Secondly, there is a hierarchy of importance:
|
Something people often find confusing is that many of the builtin commands are actually executable files, as can be demonstrated with which (which is itself a builtin):
which cd
which pwdWhat makes these commands special is that Bash does not use PATH to figure out where they are, it maps to them directly, so, even if you delete your PATH, the builtins will continue to work.
In fact, let’s do just that (in a safe way that won’t do any harm to your computer)!
export PATH=''We have now blanked the PATH environment variable in our command shell — note that we have ONLY altered the copy of PATH stored in this one command shell — all other command shells, including any new ones opened in the future, are totally unaffected by this change.
cd ~/Desktop
pwdBut we can’t do things like:
ls -alh
nano testFile.txtIt’s not that the executable files have gone, or no longer work, it’s that our instance of Bash has lost the ability to find them because its PATH is blank.
We can still run the executables by using their full paths, e.g.:
/bin/ls -alh
/usr/bin/nano testFile.txtBefore we continue, let’s restore our PATH to its normal value by closing this command shell and opening a new one.
When you get to the stage of writing your own scripts (or downloading other people’s scripts), you’ll probably want your scripts to run without needing to give the full paths to the scripts each time. As an example let’s create a new folder in our home directory and create a simple script within it:
mkdir ~/myScripts
nano ~/myScripts/whereAmIEnter the following content into the file whereAmI and save:
#!/usr/bin/perl
print "Hi $ENV{USER}, you are currently in $ENV{PWD}\n";| In the last instalment we used a Bash shell script for our example, this time, for some variety, I’m using a Perl script. The language used has no bearing on how all this works. |
Then make the script executable, and test it:
chmod 755 ~/myScripts/whereAmI
~/myScripts/whereAmIAt the moment we have to enter the full path to whereAmI each time we want to use it. Let’s remedy that by adding our new myScripts folder to the end of our PATH:
export PATH="$PATH:$HOME/myScripts"Note that we have to include the current value of PATH in the new value we set for PATH or we would be replacing the PATH rather than adding to it. This is a very common pitfall, and the effect would be that all non-builtin commands apart from those in the one new folder would break.
Note also that we used $HOME instead of ~ because you can’t use ~ in PATH.
Verify that PATH has been updated:
echo $PATH
which whereAmIWe can now use our script as a command without having to specify the full path:
whereAmINow, close your command shell, and open a new one, and try to use your script as a command again:
bart-imac2013:~ bart$ whereAmI
-bash: whereAmI: command not found
bart-imac2013:~ bart$Why was the command not found?
The answer is simply that the change we made to PATH in our previous shell’s environment vanished the moment we closed that shell.
What we need to do is make a permanent change, and to do that we need to understand how Bash initialises its environment.
When SH or Bash are initialising they start the environment building process by sourcing the file /etc/profile.
The out-of-the-box content of this file will be determined by your choice of OS.
On my Ubuntu server /etc/profile contains the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# /etc/profile: system-wide .profile file for the Bourne shell (sh(1))
# and Bourne compatible shells (bash(1), ksh(1), ash(1), ...).
if [ "$PS1" ]; then
if [ "$BASH" ] && [ "$BASH" != "/bin/sh" ]; then
# The file bash.bashrc already sets the default PS1.
# PS1='\h:\w\$ '
if [ -f /etc/bash.bashrc ]; then
. /etc/bash.bashrc
fi
else
if [ "`id -u`" -eq 0 ]; then
PS1='# '
else
PS1='$ '
fi
fi
fi
# The default umask is now handled by pam_umask.
# See pam_umask(8) and /etc/login.defs.
if [ -d /etc/profile.d ]; then
for i in /etc/profile.d/*.sh; do
if [ -r $i ]; then
. $i
fi
done
unset i
fi
While OS X comes with a much shorter and easier to understand /etc/profile:
1
2
3
4
5
6
7
8
9
# System-wide .profile for sh(1)
if [ -x /usr/libexec/path_helper ]; then
eval `/usr/libexec/path_helper -s`
fi
if [ "${BASH-no}" != "no" ]; then
[ -r /etc/bashrc ] && . /etc/bashrc
fi
In this series we are focusing on OS X, so we’ll only look at how OS X initialises its Environment in detail.
What the above OS X /etc/profile does is two things:
-
assuming it exists and is executable, it loads the output of
/usr/libexec/path_helperinto its environment -
if the process starting up is a Bash process (rather than an SH process), it executes
/etc/bashrc
As you might guess from the name, path_helper is a utility for constructing the default path.
You can run it yourself to see what it produces:
/usr/libexec/path_helperIf you’re curious, you can learn how it builds the path by reading the relevant man page with man path_helper.
The skinny version is that it reads the system-wide default path from /etc/paths, and then adds any extra paths defined in files contained in the folder /etc/paths.d.
To have a look at the default paths you can use:
cat /etc/paths
cat /etc/paths.d/*(On a default OS X install the last command will fail because there are no files present in /etc/paths.d by default)
If we wanted to add our new scripts folder to the default path for all users on the system we could edit /etc/paths, or add a new file with the path of our scripts folder in /etc/paths.d, but don’t do that!
These system-level paths should only be used for system-level things, as we’ll see shortly, there is a better way to make user-specific customisations.
For completeness, let’s have a look at /etc/bashrc.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# System-wide .bashrc file for interactive bash(1) shells.
if [ -z "$PS1" ]; then
return
fi
PS1='\h:\W \u\$ '
# Make bash check its window size after a process completes
shopt -s checkwinsize
# Tell the terminal about the working directory at each prompt.
if [ "$TERM_PROGRAM" == "Apple_Terminal" ] && [ -z "$INSIDE_EMACS" ]; then
update_terminal_cwd() {
# Identify the directory using a "file:" scheme URL,
# including the host name to disambiguate local vs.
# remote connections. Percent-escape spaces.
local SEARCH=' '
local REPLACE='%20'
local PWD_URL="file://$HOSTNAME${PWD//$SEARCH/$REPLACE}"
printf '\e]7;%s\a' "$PWD_URL"
}
PROMPT_COMMAND="update_terminal_cwd; $PROMPT_COMMAND"
fi
What’s going on here is mostly OS X-specific customisations to Bash.
The Ubuntu equivalent to this file is /etc/bash.bashrc, and just like with /etc/profile, the contents of the file is completely different to what you get on OS X.
There is really only one line in this file that I want to draw your attention to, and then, only as a preview of the next instalment. The line in questions is:
PS1='\h:\W \u\$ 'It looks like gobbledegook, but, it’s actually the line that sets the format of the command prompt.
\h is the hostname, \W is the current folder, and \u the current user.
You should recognise that as the format of the command prompt in your OS X Terminal windows.
We’ll look at this in more detail next time.
So far there are two files doing the customisation of Bash for us, /etc/profile and /etc/bashrc.
These are both system files, and if you try to edit them as a regular user you’ll find you don’t have permission:
bart-imac2013:~ bart$ ls -l /etc/profile /etc/bashrc
-r--r--r-- 1 root wheel 745 10 Nov 18:55 /etc/bashrc
-r--r--r-- 1 root wheel 189 10 Nov 18:55 /etc/profile
bart-imac2013:~ bart$It’s with good reason that you don’t have editing rights to these files — you could do serious damage to your system if you make a mistake in these files. Unless you really know what you are doing, never edit either of them!
The system-level configuration files are only the first half of Bash’s startup procedure. When a new Bash process has finished running those files, it moves on to a new phase where it checks the user’s home directory for certain specially-named files.
For reasons we won’t go into now, if you’re a Linux user the user-level file to create/edit is ~/.bashrc, while Mac users should create/edit ~/.bash_profile. (If you really care about why there is a difference, you can have a read of this short article).
So, any customisations we wish to make to Bash on our Macs should be made in ~/.bash_profile.
Let’s go ahead and set a custom PATH that includes the folder we created earlier:
nano ~/.bash_profileEnter the following and save the file (BE CAREFUL TO GET IT RIGHT):
# print warning message (leave out the echo lines if you prefer)
echo "NOTE - applying customisations in ~/.bash_profile"
echo " If you make a mistake and need to remove the customisations"
echo " execute the following then restart your Terminal:"
echo " /bin/mv ~/.bash_profile ~/bash_profile.disabled"
# update the path
export PATH="$PATH:$HOME/myScripts"|
Note that any line in a shell script starting with a When you’re happy you’ve fixed the problem you can move it back into place with: |
To test your newly customised environment simply open a new Terminal.
If you’ve done everything right you should see the warning message telling you ~/.bash_profile has been executed, and, your path should have been updated to include ~/myScripts.
You can verify this by running:
echo $PATH
whereAmIYou should use ~/.bash_profile to make all your Bash customisations, not just customisations to your PATH.
In the next instalment, we’ll have a look at some of the other customisations you might like to configure in your ~/.bash_profile file.
TTT Part 14 of n — Aliases & Prompts
In the previous instalment, we looked at how to make permanent changes to our environment.
We made a permanent change to the PATH environment variable to demonstrate how it’s done
(by editing ~/.bash_profile on a Mac,
or ~/.bashrc on Linux).
In this instalment we’ll look at two other kinds of environment changes you may wish to make by editing these files — specifically, aliases, and custom prompts.
Listen Along: Taming the Terminal Podcast Episode 14
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
|
This instalment assumes you’re using Bash, if you’re on macOS Catalina or later you’re probably using Zsh, see the Introduction for more information on using Bash on newer Macs. |
Aliases
Aliases are basically command shortcuts. When used as a command, the alias gets expanded to a longer string by Bash before execution. Aliases can contain arguments as well as commands. Aliases can be used to create short mnemonics for long complex commands or to add default arguments to existing commands.
Let’s start with an example of the first kind.
The command ls -l often results in very long output, so it would be nice to be able to automatically run this output through a pager so we can see it one page at a time instead of having to scroll back up to find the start of the output.
As we’ll learn in the next instalment, you can do this using the | (pronounced ‘pipe’) operator.
To run the output of ls -l through less the command is:
ls -l | lessLet’s create a short alias for this command, ll:
alias ll='ls -l | less'As you can see, you create an alias using the alias command.
The bit before the = is the shortcut, and the bit after the = is what it will expand into.
If the expansion contains spaces or other special characters then either the entire replacement needs to be quoted, or each special character needs to be escaped.
The vast majority of aliases you create will contain spaces and/or at least one special character, so it’s best to get into the habit of always quoting your aliases.
In the above example, both the spaces and the | would need to be escaped, so the un-quoted version of the above alias would be the following difficult to read mess:
alias ll=ls\ -l\ \|\ lessAnother common use of aliases is to add default arguments to existing commands. Let’s look at two common examples of this.
By default, the ls command does not clearly distinguish the types of the items it lists.
ls -F makes things quite a bit clearer by adding a trailing / to all folders in the listing, and -G makes things even clearer still by using colours to distinguish different types of files (remember that on Linux it’s --color rather than -G).
To have ls always show trailing slashes and use colours we can alias ls to ls -FG (or ls -F --color on Linux):
alias ls='ls -FG'Secondly, we can use aliases to make commands that might unintentionally remove or override files behave in a safer manner by automatically adding the -i flag to rm, cp & mv:
alias rm='rm -i' cp='cp -i' mv='mv -i'Note that you can use the alias command to add multiple aliases at once.
If you set these aliases then rm, cp, and mv will ask for your permission before deleting or overriding a file.
If you’re manipulating many files at once this will get tedious, so remember that even if you do this, you can over-ride the -i by adding a -f (for force) to the commands.
This means you have to be explicit about deleting or overriding files, instead of the commands implicitly assuming you are happy to have the files destroyed.
To see a list of all currently defined aliases, simply run the alias command without any arguments:
1
2
3
4
5
6
7
bart-imac2013:~ bart$ alias
alias cp='cp -i'
alias ll='ls -l | less'
alias ls='ls -FG'
alias mv='mv -i'
alias rm='rm -i'
bart-imac2013:~ bart$
To remove an alias, use the unalias command with the shortcut to be removed as an argument.
E.g.
to remove our ll alias, run:
unalias llAliases are part of the Bash environment and are not persistent.
If you create an alias and then close your command shell it will be gone.
To make aliases permanent we need to add them into our Bash startup scripts.
As we learned in the previous instalment, for Mac users that means adding our aliases to ~/.bash_profile, while Linux users should add their aliases to ~/.bashrc.
If we include the examples from the previous instalment an updated ~/.bash_profile file to include the ll alias would look something like:
1
2
3
4
5
6
7
8
9
10
11
12
13
# print warning message (leave out the echo lines if you prefer)
echo "NOTE – applying customisations in ~/.bash_profile"
echo " If you make a mistake and need to remove the customisations"
echo " execute the following then restart your Terminal:"
echo " /bin/mv ~/.bash_profile ~/bash_profile.disabled"
# update the path
export PATH="$PATH:$HOME/myScripts"
# create our aliases
alias ll='ls -l | less'
alias ls='ls -FG'
alias rm='rm -i' cp='cp -i' mv='mv -i'
Customising the Bash Prompt
As we discussed right back in the first instalment, the format of your command prompt varies from system to system. This variation is not just between command shells, but also within command shells, because many allow customisations to the format of the prompt. Bash is one of the command shells that support command prompt customisation.
In BASH, the format of the prompt is defined in the shell variable PS1.
You can see the current format used with the command:
echo $PS1On OS X the default value of PS1 is \h:\W \u\$, giving prompts that look like:
bart-imac2013:~ bart$On the RedHat and CentOS variants of Linux the default is [\u@\h \W]\$, which give prompts that look like:
[bart@www ~]$From the above, you should be able to deduce that any letter in the code prefixed with a \ is replaced with a value.
Below is a list of some of the variables at your disposal:
-
\h— your computer’s hostname (e.g.bart-imac2013) -
\H— your computer’s FQDN, or fully qualified domain name (e.g.bart-imac2013.localdomain) -
\d— the current date -
\t— the current time in 24 hour HH:MM:SS format -
\T— the current time in 12 hour HH:MM:SS format -
\@— the current time in 12 hour am/pm format -
\A— the current time in 24-hour HH:MM format -
\u— the username of the current user -
\w— the complete path of the present working directory ($HOMEabbreviated to~) -
\W— the current folder, i.e. the last part of the print working directory ($HOMEabbreviated to~) -
\$— if running as root a#symbol, otherwise, a$symbol -
\n— a new line (yes, your prompt can span multiple lines if you like)
As an example, let’s create a very descriptive Bash prompt:
PS1='\d \t - \u@\H:\w\n\$ 'Like with any shell variable, any changes we made to PS1 are confined to our current command shell.
Opening a new Terminal window will restore PS1 to its default value.
If we want to make the change permanent, we need to add it to our bash startup file (~/.bash_profile on OS X or ~/.bashrc on Linux).
A ~/.bash_profile file setting all the customisations we’ve discussed in this instalment and the previous instalment would look like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# print warning message (leave out the echo lines if you prefer)
echo "NOTE – applying customisations in ~/.bash_profile"
echo " If you make a mistake and need to remove the customisations"
echo " execute the following then restart your Terminal:"
echo " /bin/mv ~/.bash_profile ~/bash_profile.disabled"
# update the path
export PATH="$PATH:$HOME/myScripts"
# create our aliases
alias ll='ls -l | less'
alias ls='ls -FG'
alias rm='rm -i' cp='cp -i' mv='mv -i'
# set a custom prompt
PS1='\d \t – \u@\H:\w\n\$ ';
Personally, I like to keep my prompts set to their default values — it helps me recognise the OS I’m on at a glance.
Conclusions
Over the past few instalments, we have looked at what the shell environment is, how we can manipulate shell and environment variables and aliases.
We looked at two variables in particular, PATH and PS1.
We also discussed Bash aliases, and how to make permanent changes to your Bash environment, allowing you to customise your PATH and prompt and define aliases.
This is where we’ll leave the concept of the environment for now. In the next instalment, we’ll move on to look at what I jokingly call ‘plumbing’ — how commands can be chained together, and how files can be used for input to and output from commands.
TTT Part 15 of n — 'Plumbing'
Right back in the very first instalment, we described the Unix philosophy as being Lego-like, that is, having lots of simple commands that do one thing well, and then assembling them together to do something really powerful.
So far, we’ve only been working with a single command at a time, but that changes with this instalment. We’ll be introducing the concept of streams, which can be used to connect commands and files together.
Listen Along: Taming the Terminal Podcast Episode 15
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Streams
Before we can get into the nitty-gritty of chaining commands together, we need to introduce a new concept, that of a stream of data. Quite simply, a stream is a sequential flow of data — everything that goes in one end comes out the other, and it always comes out in the same order it went in.
In a Unix/Linux environment there are three standard streams:
-
STDOUT(Standard Out): when working on the command line this stream is usually connected to the terminal — anything written to that stream is printed in the terminal window. Within applications, this stream is usually connected to a log file. -
STDERR(Standard Error): this is another output stream, but one reserved for error messages. When working at the command line, this stream is usually also connected to the terminal in the same way thatSTDOUTis. Within applications, this stream is usually connected to a log file, though often a different log file toSTDOUT. -
STDIN(Standard In): this stream is used for input rather than output. When working at the command line, it is usually connected to the keyboard. Within applications, this stream could be attached to anything really. E.g. within a web server it is connected to the HTTP request data sent to the server by the browser.
Many Unix/Linux commands can take their input from STDIN, and just about every command will write its output to STDOUT and/or STDERR.
This allows commands to be strung together by the simple act of redirecting these streams — if you redirect the output of one command to the input of another, you have chained them together!
Remember that every process has its own environment, and therefore, its own version of the three standard streams.
The redirection operators alter the copies of these three variables within individual processes, so, from the command’s point of view, it always reads from STDIN, and always writes to STDOUT and/or STDERR, but where those streams flow to is determined by their environment.
Stream Redirection
Bash provides a number of stream redirection operators:
-
|(the ‘pipe’ operator) — this operator connectsSTDOUTin the environment of the command to its left toSTDINin the environment of the command to its right. -
>and>>— these operators connectSTDOUTin the environment of the command to their left to a file at the path specified to their right -
<— this operator connects the contents of the file at the path specified to its right toSTDINin the environment of the command to its left
The | operator is probably the most used of the three, as it allows straight-forward command chaining.
It’s also the simplest.
For that reason we’re going to focus solely on the | operator in this instalment, leaving the file-related operators until the next instalment.
The | Operator in Action
To facilitate an example, let’s introduce a simple command for counting words, characters, or lines — wc (word count).
A quick look at the man page for wc shows that it counts lines when used with the -l flag.
Something else you might notice is that the command OPTIONALLY takes an argument of one or more file paths as input.
This means we can count the number of lines in the standard Unix/Linux hosts file with the command:
wc -l /etc/hostsBut why is the list of file paths optional? What could the command possibly count if you don’t point it at a file? The answer can be found further down in the man page:
In other words, wc will read its input from STDIN if no file is specified, and, no matter what the input source, it will write its results to STDOUT.
Now that you know about the three standard streams, you’ll start to see them in man pages all over the place.
E.g., you’ll find the following in the man page for ls:
Let’s combine our knowledge of ls, wc, streams, and stream redirection to build a command to determine how many files or folders there are on our Desktop:
ls -l ~/Desktop | wc -lNOTE — the | operator ONLY redirects STDOUT to STDIN, it has no effect on STDERR, so if there is an error generated by the ls command that error message will go to the screen, and not to the wc command.
To illustrate this point, let’s try to count the number of files in a folder that does not exist:
ls -l ~/DesktopDONKEY | wc -lWe see the error message generated by ls on the screen, and it is one line long, but, wc never saw that line because it was printed to STDERR, so instead of saying there is 1 file in this fictitious folder, it tells us, correctly, that there are no files in that folder.
Special Stream Files
You’ll often hear Unix nerds tell you that in Unix, everything is a stream.
This is because deep down, Unix (and Linux) treat files as streams.
This is especially true of some special files which really are streams of data rather than pointers to data on a hard disk.
Special files of this type have a c (for character special file, i.e.
a character stream) as the first letter in their permission mask in the output of ls -l.
E.g.:
ls -l /dev/nullThere are many such files in /dev/ on a Unix/Linux machine, but it is a VERY bad idea to write to or read from any you don’t understand.
These files are generally connected directly to some piece of hardware in your system, including low-level access to your hard drives, so you could destroy important data very easily. (Thankfully you need to be root to write to the hard drive connected ‘files’).
There are a few safe special files that I want to mention though:
-
/dev/null: this is effectively a black hole — you use this file to redirect the output into oblivion. (More on this in the next instalment.) -
/dev/randomor/dev/urandom: both of these streams output random data 8 bytes at a time. The difference between the two is that/dev/randomdoes not care how much entropy the OS has built up (i.e. how good the randomness is), it will output what it has, while/dev/urandomwill pause output when the level of entropy gets too low, and only resume when the entropy pool has built up again. In other words,/dev/randompromises speed, but not quality, while/dev/urandompromises quality but not speed. -
/dev/zero: this stream outputs a constant flow of zeros.
As an example, let’s use /dev/urandom to generate 10 random characters.
Before we can begin there are two complications that we need to understand.
Firstly, these special streams have no beginning or end, so we have to be sure to always read from them in a controlled way — if you ask a command like cat to print out the contents of such a file it will never stop, because cat continues until it reaches the end of file marker, and these special ‘files’ have no end!
Also, /dev/urandom does not output text characters, it outputs binary data, and while some combinations of binary data map to characters on our keyboards, most don’t, so we will need to convert this stream of binary data into a stream of text characters.
We can overcome the first of these limitations by using the head command we met in part 11 of this series.
Previously we’ve used head to show us the first n lines of a file, but we can use the -c flag to request a specific number of characters rather than lines.
The second problem can be overcome with the base64 command, which converts binary data to text characters using the Base64 encoding algorithm.
A quick look at the man page for base64 shows that it can use streams as well as files:
putting all this together we can assemble the following command:
head -c 10 /dev/random | base64This is nearly perfect, but, you’ll notice that the output always ends with ==, this is the Base64 code for ‘end of input’.
We can chop that off by piping our output through head one more time to return only the first 10 characters:
head -c 10 /dev/random | base64 | head -c 10This will print only the 10 random characters, and nothing more.
Since this command does not print a newline character, it leaves the text stuck to the front of your prompt which is messy.
To get around this you can run echo with no arguments straight after the above command:
head -c 10 /dev/random | base64 | head -c 10; echoNote we are NOT piping the output to echo, the symbol used is ;, which is the command separator, it denotes the end of the previous command and the start of the next one, allowing multiple separate commands to be written on one line.
The commands will be executed in order, one after the other.
Finally, because we need to use the same number of characters in both head commands, we could use command-line variables to make this command more generic and to make it easier to customise the number of characters:
N=10; head -c $N /dev/random | base64 | head -c $N; echoConclusions
In this instalment, we have introduced the concept of streams, particularly the three standard streams provided by the environment, STDOUT, STDERR, and STDIN.
We’ve seen that these streams can be redirected using a set of operators and that this redirection provides a mechanism for chaining commands together to form more complex and powerful commands.
We’ve been introduced to the concept of using files as input and output, but have not looked at that in detail yet.
We’ve also not yet looked at merging streams together, or independently redirecting STDOUT and STDERR to separate destinations — this is what’s on the agenda for the next instalment.
TTT Part 16 of n — Crossing the Streams
In the previous instalment, we introduced the concepts of streams and looked at how every process has references to three streams as part of their environment — STDIN, STDOUT & STDERR.
We went on to introduce the concept of operators that manipulate these streams, and we focused on the so-called ‘pipe’ operator which connects STDOUT in one process to STDIN in another, allowing commands to be chained together to perform more complex tasks.
We mentioned the existence of operators for connecting streams to files, and the possibility of streams being merged together, but didn’t go into any detail.
Well, that’s what we’ll be doing in this instalment.
Listen Along: Taming the Terminal Podcast Episode 16
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Turning Files into Streams
So far we’ve been redirecting the output of one command to the input of another, but we can also use files as the source of our streams using the < operator.
The operator works by connecting the content of the file to the right of the operator to STDIN in the command to the left of the operator.
As an example, let’s use the wc command we learned about in the previous instalment to count the number of lines in the standard Unix/Linux hosts file again, but this time, we’ll use the < operator:
wc -l < /etc/hostsBecause the wc command can take its input either from STDIN or from one or more files passed as arguments, the above command achieves the same things as the command we saw in the previous instalment:
wc -l /etc/hostsThe wc command is not in any way unusual in this, the vast majority of Unix/Linux commands which operate on text or binary data can accept that data either from STDIN or from a file path passed as an argument.
For example, all the following commands we have met before can take their input from STDIN rather than by specifying a file path as an argument.
less < /etc/hosts
cat < /etc/hosts
head -3 < /etc/hostsIt’s easier to just pass paths as arguments through, hence the < operator is probably the least-used of the stream redirection operators.
However, just because it’s the least-used, doesn’t mean it’s never needed!
There are some commands that will only accept input via STDIN, and for such commands, it’s vital to have an understanding of the < operator in your command-line toolkit.
In my professional life, the one example I meet regularly is the mysql command, which does not take a file path as an argument (Note that MySQL is not installed by default on OS X).
To load an SQL file into a MySQL database from the command line you have to do something like:
mysql -h db_server -u db_username -p db_name < sql_file.sqlSending Streams to a File
While you’re not likely to find yourself using files as input streams very often, you are quite likely to find yourself using files as output streams. There are two operators which perform this task, and the difference between them is subtle but very important.
The first of these operators is >.
This operator directs the output from the command to its left to a NEW file at the path specified to its right.
If a file already exists at the specified path, it will be REPLACED.
This means that after the command finishes the file will only contain the output from that one command execution.
Because of this overwriting behaviour, always use the > operator with great care!
The second of the file output operators is >>.
This operates in a very similar way to >, directing the output of the command to its left to the file specified to its right, but with one very important difference — if a file already exists at the specified path it will not be replaced, instead, the new output will be appended to the end of the file.
This makes the >> operator much safer, but, it means you cannot easily see which content in the file came from the latest execution of the command.
As a practical example, let’s revisit our command for generating random characters from the previous instalment, but this time, rather than outputting the random characters to the terminal, we’ll send them to a file:
N=256
head -c $N /dev/random | base64 | head -c $N > random.txtWe can verify that we have generated 256 random characters by using the wc command with the -c flag to get it to count characters:
wc -c random.txtIf we re-run the command we can verify that the file still only contains 256 characters because the original version of the file was simply replaced by a new version because we used the > operator:
head -c $N /dev/random | base64 | head -c $N > random.txt
wc -c random.txt
head -c $N /dev/random | base64 | head -c $N > random.txt
wc -c random.txtNow let’s change things up and generate 8 random characters at a time, but append them to a file with the >> operator:
N=8
head -c $N /dev/random | base64 | head -c $N >> randomAccumulator.txtAs before we can verify the amount of characters in the file using:
wc -c randomAccumulator.txtNow, each time we repeat the command we will add 8 more characters to the file rather than replacing its contents each time:
head -c $N /dev/random | base64 | head -c $N >> randomAccumulator.txt
wc -c randomAccumulator.txt
head -c $N /dev/random | base64 | head -c $N >> randomAccumulator.txt
wc -c randomAccumulator.txtRedirecting Streams Other Than STDIN & STDOUT
So far we have always operated on STDIN and STDOUT.
This is true for our use of all four of the operators we’ve met so far (|, <, > & >>).
However, there is often a need to control other streams, particularly STDERR.
Unfortunately, we now have no choice but to take a look at some rather deep Unix/Linux internals.
We’ve already learned that each process has a reference to three streams within its environment which we’ve been calling by their Englishy names STDIN, STDOUT & STDERR.
We now need to remove this abstraction.
What the process’s environment actually contains is something called a “File Descriptor Table”, which contains a numbered table of streams.
Three of these streams are created by default, and always present, but processes can add as many more streams as they wish.
Within the file descriptor table, all streams are referenced by number, rather than with nice Englishy names, and the numbers start counting from zero.
To make use of the file descriptor table, we need to know the following mappings:
| File Descriptor | Maps to |
|---|---|
|
|
|
|
|
|
If we were to define our own streams, the first stream we defined would get the file descriptor 3, the next one 4 and so on.
We are not going to be defining our own streams in this series, so all we have to remember is the contents of the small table above.
We can use the numbers in the file descriptor table in conjunction with the <, > & >> operators to specify which streams the files should be connected to.
For example, we could re-write the examples from today as follows:
wc -l 0< /etc/hosts
head -c $N /dev/random | base64 | head -c $N 1> random.txt
head -c $N /dev/random | base64 | head -c $N 1>> randomAccumulator.txtSince these operators use 0 and 1 by default, you’d never write the above commands with the 0s and 1s included, but, you have to use the file descriptor table to redirect STDERR.
Let’s revisit the command we used to intentionally trigger output to STDERR in the previous instalment:
ls -l ~/DesktopDONKEY | wc -lThis command tries to count the files in a non-existent folder.
Because the folder does not exist, the ls command writes nothing to STDOUT.
Because the | only operates on STDOUT the wc command counts zero lines, and the error message which was written to STDERR is printed to the screen.
We could now redirect the error message to a file as follows:
ls -l ~/DesktopDONKEY 2> error.txt | wc -l
cat error.txtNote that we have to redirect STDERR before the | operator, otherwise we would be redirecting STDERR from the wc command rather than the ls command.
Multiple Redirects
You can use multiple redirects in one command. For example, you could use one redirect to send data from a file to a command, and another redirect to send the output to a different file. This is not something you’ll see very often, but again, it’s something MySQL command-line users will know well, where this is a common construct:
mysql -h db_server -u db_username -p db_name < query.sql > query_result.tabYou might also want to send STDOUT to one file, and STDERR to a different file:
ls -l ~/DesktopDONKEY 2> error.txt | wc -l > fileCount.txtCrossing the Streams
Unlike in the Ghostbusters universe, in the Unix/Linux universe, it’s often desirable to cross the streams — i.e.
to merge two streams together.
The most common reason to do this is to gather all output, regular and error, into a single stream for writing to a file.
The way this is usually done is to divert STDERR to STDOUT and then redirect STDOUT to a file.
In order to construct a meaningful example, let’s preview a command we’re going to be returning to in great detail in a future instalment, the find command.
This command often writes to both STDOUT and STDERR during normal operation.
As its name suggests, the find command can be used to search for files that meet certain criteria.
If you run the command as a regular user and ask it to search your entire hard drive or a system folder, it will run into a lot of permission errors interspersed with the regular output as the OS prevents it from searching some protected system folders.
As a simple example, let’s use find to search for .pkg files in the system library folder:
find /Library -name *.pkgAlmost straight away you’ll see a mix of permission errors and files with the .pkg extension.
The key point is that there is a mix of errors and results.
If we try to capture all the output with the command below we’ll see that the error messages are not sent to the file, instead, they are sent to our screen (as expected):
find /Library -name *.pkg > findOutput.txt
cat findOutput.txtAs we’ve just learned, we could send the errors to one file and the files to another with:
find /Library -name *.pkg > findOutput.txt 2> findErrors.txt
cat findOutput.txt
cat findErrors.txtBut how could we capture all the output together?
To do this we need to introduce one more operator, the & operator.
This operator allows a file descriptor table entry to be used in place of a file path by the <, > & >> operator.
Hence, we can redirect STDERR (2) to STDOUT (1) as follows:
find /Library -name *.pkg 2>&1This has no noticeable effect until you send STDOUT to a file, then you can see that we have indeed diverted STDERR to STDOUT, and the combined stream to a file:
find /Library -name *.pkg > findCombinedOutput.txt 2>&1
cat findCombinedOutput.txtIMPORTANT: notice the counter-intuitive ordering of the above command, although the redirect happens first, it MUST be specified at the end of the command or it will not work.
There is much much more than can be done with streams, but, this is all most people are likely to need in their day-to-day life on the command line, so we’ll stop here before we confuse everyone too much 🙂
Conclusions
We have now seen how streams, and a process’s file descriptor table, can be manipulated using the stream redirection commands to chain commands together and funnel input and output to and from files in a very flexible way. This ability to manipulate streams opens up a whole new world to us, allowing us to build up complex commands from simple commands. This ability to chain commands is a pre-requisite for our next topic — searching at the command line.
TTT Part 17 of n — Regular Expressions
This instalment is the start of a series of instalments relating to searching from the command line. Searching is all about patterns, and that means getting to grips with Regular Expressions (also called RegExps, RegExes or REs for short). Regular Expressions are languages for representing patterns and are used throughout Information Technology, not just on the command line. While this series focuses on the Terminal, an understanding of regular expressions will be helpful in many other places, from programming languages to GUI apps like programming editors, search utilities or file renamers.
It’s going to take us two instalments to properly describe regular expressions, but when we’re done we’ll have gained a very useful skill.
Listen Along: Taming the Terminal Podcast Episode 17
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
What Are Regular Expressions?
If you want to get scientific about it, regular expressions are languages for describing regular grammars, which are the simplest type of grammar in the Chomsky Hierarchy.
You could easily dedicate an entire university-level course to explaining the meaning and importance of that last sentence, and in fact, if you take a degree in Computer Science, you will!
However, that’s not much use to us for the purpose of this series.
In effect, what it means is that regular expressions provide a means for representing patterns that can be described as a series of elements following one after the other.
That means regular expressions can do a lot. They can find all currency amounts in a document (a currency symbol followed by either an integer or a decimal number), they can find percentages (an integer or decimal number followed by a percentage symbol), they can find temperatures (an integer or decimal number followed by a C, F, or K), and so on.
That includes quite complex things like recognising URLs, which could be described something like:
That description is actually incomplete because you would need to describe what some of those parts mean in more detail before you could write a regular expression for them, but that’s no problem because those parts too can be described as a series of elements following each other. For example, you’d have to further break down the domain name part into something like:
The key point is that if you can describe a pattern as a series of elements that follow one after the other, then you should be able to write a regular expression to represent that pattern.
So, regular expressions are without a doubt powerful, but, they are not all-powerful — there are entire classes of problems regular expressions are powerless to help with. In fact, to get scientific again for a moment, there are three entire grammar classes in the Chomsky Hierarchy that REs are powerless to help with. In practical terms that means that REs can’t help when some kind of memory is needed to know what has gone before, or when the elements in the pattern can be arbitrarily ordered and/or nested. For example, it would be impossible to write a regular expression to test if an arbitrary piece of text contained a matched set of arbitrarily nested brackets, because, to know if a given closing bracket is or is not valid, you need to know how many opening brackets have proceeded it. Also, REs can’t be used to validate something like XML (or HTML for that matter), because tags can come in any order, and be validly nested in all sorts of different ways.
Not understanding the limits of REs leads to a lot of frustration, and a lot of very unreliable code. If you can’t describe it as a series of elements that follow each other in a given order, a regular expression is not the answer!
The fact that many programmers don’t understand the limitations of regular expressions has led to the incorrect maxim that if you have a problem and try to solve it with regular expressions you then have two problems, your original problem and a regular expression.
Don’t Be Intimidated!
Regular expressions can look very intimidating, but, once you know the language they are written in, they are actually very simplistic things. Think of it as a mathematical equation, until you know what all the symbols mean, it’s a big pile of intimidating gobbledegook, but, once you understand the meanings of the symbols, you can work your way through an equation logically.
The following apparent gibberish is a regular expression describing the domain name pattern described above:
[a-zA-Z0-9][-a-zA-Z0-9]*([.][a-zA-Z0-9][-a-zA-Z0-9]*)*For now, that looks horrific, but, when we’ve finished this instalment and the one after, I promise it’ll make sense!
Also, I promise the following is a really funny joke — when you get it, you’ll know you get REs! (I have this on a T-shirt, and it works as a great nerd ––test.)
(bb)|[^b]{2}Which RE Language?
Just like there is no one programming language, there is no one language for regular expressions. So, that leads to an obvious question, which type of RE should we learn? Because this series is all about the Terminal, the answer is actually very easy, there’s really only one choice that makes sense, but, it happens to be a choice that conveniently gives us a very solid base to build from for other uses of REs.
Let’s start with some context. Firstly, when it comes to regular expressions you can’t ignore my favourite scripting language, Perl. Perl was developed for the purpose of processing text, which means pattern matching is at the very core of its DNA. The official backronym for Perl is the Practical Extracting and Reporting Language, and the joke backronym is the Pathologically Eclectic Rubbish Lister. Either way, Perl is all about extracting information from textual data, so it’s all about pattern matching.
Because Perl has pattern matching so deeply embedded within its being, it should come as no surprise that the gold standard for regular expressions are so-called Perl-Style Regular Expressions, which you’ll often find referenced in man pages and other documentation as PCRE, which stands for Perl Compatible Regular Expression. What we’re going to learn is not exactly PCRE, but, a sub-set of PCRE called POSIX ERE. The fact that POSIX ERE is a subset of PCRE means that everything we learn will be useful to us in any application that uses PCRE, which means we can transfer what we learn here to a LOT of other contexts, including the two common web programming languages PHP and JavaScript (which both use PCRE for their regular expression implementations).
POSIX ERE
Why POSIX ERE? In fact, more fundamentally, what is POSIX?
POSIX stands for Portable Operating System Interface, and it’s the reason that the things we learn in this series are so surprisingly portable. POSIX is the standard that unites most of the flavours of Unix and Linux and gives us a common foundation to work off of. Not all our *nix operating systems are POSIX certified, but they are all, to a very very high degree, POSIX compliant. OS X is actually POSIX certified, but Linux is not, it just implements pretty much the entire POSIX standard. POSIX covers many things, from how file systems should be presented, to a core set of terminal commands that are the same across all POSIX OSes, to a large set of programming APIs that can be used to create apps that run on all POSIX systems, to a portable regular expression syntax.
Actually, POSIX specifies two regular expression languages, POSIX Basic Regular Expressions (BRE), and POSIX Extended Regular Expressions (ERE). The reason there are two is that POSIX is literally decades old, and regular expressions have come a long way since the BRE syntax was defined. When it comes to the simple stuff, BRE and ERE are the same, but, when it comes to more complex stuff, specifically cardinalities and grouping, they are not compatible. For these advanced features, BRE is not PCRE compatible, but ERE is, making it the best kind of RE for those exploring the terminal.
For all the examples in this series, we are going to use ERE, and we are only going to use command line tools that understand ERE. However, it’s important to know that BRE exists, because you’ll see both BRE and ERE mentioned in many man pages, and, some terminal commands default to BRE for legacy reasons, but can accept ERE if a certain flag is passed.
Getting Practical
The only way to really learn regular expressions is through practical examples, so, for this instalment and the next, we’ll be using the egrep command to search the standard Unix words file for words that match a given pattern.
We’ll be looking at the egrep command in more detail later in the series, but for now, all we need to know is that egrep can be used with two arguments, the first, a regular expression in POSIX ERE format, and the second the path to a file to search.
egrep will print each line that contains text that matches the given pattern. It will not print just the text that matches the pattern, it will print the entire line that contains the match.
The standard Unix words file is a text file containing a list of valid English words, one word per line.
On OS X and Ubuntu Linux, the file is located at /usr/share/dict/words, though on some Unix/Linux variants you’ll find it at /usr/dict/words instead.
Getting Started with POSIX ERE
In this instalment we’re going to start with the simpler parts of the ERE language, and, in fact, everything we learn today will be valid ERE, BRE, and PCRE, so it will apply very very widely indeed.
Ordinary characters represent themselves in a pattern, so the POSIX ERE to represent the letter a is simply:
aSimilarly, the RE to represent the character t followed by the character h is simply:
thLet’s start with a simple example — finding all words that contain a double e in the words file.
Remember, the egrep command prints any line from the input file that matches the specified pattern, so, to find all words with a double e you could use the following command:
egrep 'ee' /usr/share/dict/wordsLet’s take things up a notch, and include line boundaries in our pattern.
The special character ^ represents start of line when used at the start of a regular expression (it can have other meanings when used elsewhere as we’ll see later).
Its opposite number is the special character $, which represents end of line.
So, the following command will find all words starting with the character b:
egrep '^b' /usr/share/dict/wordsSimilarly, the following command will find all words ending in the three letters ing:
egrep 'ing$' /usr/share/dict/words*Note:* you may have noticed that I’ve been single-quoting the pattern in all the examples. This is often not necessary, because many patterns don’t contain Bash special characters, but, some do, including the one above, which contains the dollar symbol. If the string had not been single-quoted, we would have had to escape the dollar symbol which would be very messy. My advice would be to get into the habit of always single-quoting regular expressions, it’ll save you a lot of frustration over time!
Something else that’s very important is the ability to specify a wild-card character. We can do that using the period character, which you should read in an RE as any one character.
As an example, let’s say you’re stuck on a thorny crossword puzzle, and you need a word that fits into something e something something f something.
You could use the following terminal command to find a list of possible answers:
egrep '^.e..f.$' /usr/share/dict/wordsSomething to notice in the above command is that the specific pattern we are looking for is bounded by a
^ and a $,
this is to ensure we don’t get longer words that contain the pattern returned.
If you run the command again but leave those symbols out you’ll see that you get a lot of unwanted results (over 900 on OS X).
The last thing we’re going to look at in this instalment is character classes, these are used to match a single character against multiple options. You can think of everything inside a character class as being a big list of "ors". Character classes are enclosed inside square brackets, so, you should read the character class below as a or b or c or d or e or f:
[abcdef]As an example, let’s search for all four-letter words starting with a vowel:
egrep '^[aeiou]...$' /usr/share/dict/wordsYou can also use the minus sign within character classes to specify ranges of characters. Some commonly used ranges include:
[0-9]
|
Any digit |
[a-z]
|
Any lowercase letter |
[A-Z]
|
Any uppercase letter |
You don’t have to stick to those common ranges though, you can use subsets of them, and you can use multiple ranges within a single character class.
As an example, the regular expression below matches valid MAC addresses in OS X (and Linux) format. On POSIX OSes like OS X and Linux, MAC addresses are represented as a series of six two-character lower-case hexadecimal numbers separated by colon symbols, so, they could be matched with the following regular expression:
[0-9a-f][0-9a-f]:[0-9a-f][0-9a-f]:[0-9a-f][0-9a-f]:[0-9a-f][0-9a-f]:[0-9a-f][0-9a-f]:[0-9a-f][0-9a-f]The above RE will work, but it’s quite unwieldy and full of repetition, you might imagine there’d be a simpler, more efficient way of representing this pattern, and you’d be right! I’ll stop here and leave the following as a teaser for the next instalment, the above ungainly 102-character RE can be reduced to just 29 characters using two important new concepts, cardinality and grouping.
TTT Part 18 of n — More REs
In the previous instalment, we introduced the concept of Regular Expressions and started to learn the POSIX ERE regular expression language, noting that POSIX ERE is a sub-set of the very commonly used Perl Compatible Regular Expression (PCRE) language.
In this instalment, we’ll learn more POSIX ERE syntax, and have a look at some examples of REs in GUI apps.
Listen Along: Taming the Terminal Podcast Episodes 18a & 18b
| Episode 18a | Episode 18b |
|---|---|
Scan the QR code to listen on a different device |
|

|

|
You can also play/download the MP3 in your browser (a) |
You can also play/download the MP3 in your browser (b) |
Inverted Character Classes
As we have already seen, character classes can be used to specify a list of allowed characters.
We’ve seen that you can simply list the characters that are allowed one after the other, and, that you can use the - operator to specify a range of characters.
Something else you can do with a character class is invert it, in other words, have it match every character except the ones you list.
To do this, you must start the character class with the ^ symbol.
For example, the following command will find all five-letter words that don’t start with a vowel:
egrep '^[^aeiou]....$' /usr/share/dict/wordsNotice that the meaning of the ^ symbol changes depending on where it is used, outside character classes it means start of line, and inside character classes, it means not any of the following.
This Or That
When we’re describing patterns in English, we’ll often find ourselves using the word or, so it’s not surprising that there is a POSIX ERE operator to allow us to search for one pattern, or another (or another, or another …).
The pipe symbol (|) means or in POSIX ERE.
This symbol has a different meaning in Bash (it’s one of the stream redirection operators), so it’s vital you quote any RE containing the | symbol.
As an example, the following command will search the standard Unix words file for all five-letter words starting in th or ending in ing:
egrep '^th...$|^..ing$' /usr/share/dict/wordsGrouping
It’s often very helpful to be able to group together a part of a pattern, effectively defining a sub-pattern. To do this, surround the sub-pattern in round brackets (aka parentheses). We can do this to limit the scope of an or operator, or, as we’ll see shortly, to define which parts of a pattern can and cannot be repeated.
As a simple example, the following command will find all seven letter words starting with th or ab:
egrep '^(th|ab).....$' /usr/share/dict/wordsCardinalities
Many patterns contain some form of repetition, hence, regular expression languages generally contain a number of operators for expressing different ways in which a pattern, or a part of a pattern, can be repeated. There are four POSIX ERE operators that allow you to specify different amounts of repetition.
The first and most common is the * operator which you should read as zero or more occurrences of.
The operator applies to just the single character or group directly to its left.
For example, the command below will find all words of any length starting with th and ending with ing, including the word thing which has no letters between the th and the ing:
egrep '^th.*ing$' /usr/share/dict/wordsThe next operator we’ll look at is the ` operator, which you should read as _one or more occurrences of_.
Like the `\*`, this operator also only operates on the single character or group directly to its left.
If we repeat the above example but with a ` rather than a *, then we are searching for all words starting in th and ending in ing with at least one letter between the th and the ing.
In other words, the same results as before, but without the word thing, which has zero letters between the th and the ing:
egrep '^th.+ing$' /usr/share/dict/wordsThe last of the simple cardinality operators is the ? operator which you should read as either zero or one occurrence of or, more succinctly optionally.
Again, like the * and + operators, this operator also only operates on the single character or group directly to its left.
As an example, the following command finds all words that end in ing or ings:
egrep 'ings?$' /usr/share/dict/wordsThe above returns both winning, and winnings.
The first three cardinality operators will usually give you what you need, but, sometimes you need to specify an arbitrary range of times a pattern may be repeated, in which case, you’ll need the final cardinality operator, {}.
This operator can be used in a number of ways:
|
exactly |
|
at least |
|
at least |
Like the other three cardinality operators, this operator also only acts on the one character or group directly to its left.
As a first example, the following command lists all 10 letter words:
egrep '^.{10}$' /usr/share/dict/wordsAs another example, the following command lists all words between 10 and 12 characters long (inclusive):
egrep '^.{10,12}$' /usr/share/dict/wordsFinally, the following command list all words at least 15 letters long:
egrep '^.{15,}$' /usr/share/dict/wordsSpecial Characters
We’ve now seen all the symbols that have a meaning within a POSIX ERE (except for one which we’ll see in a moment), so, we know that all the following characters have a special meaning:
|
Starts with (outside a character class), or not any of (at the start of a character class) |
|
Ends with |
|
Any one character |
|
Start and end of a character class |
|
The range operator (only within a character class) |
|
specify groupings/sub-patterns |
|
Or |
|
Zero or more occurrences of |
|
One or more occurrences of |
|
Zero or one occurrence of |
|
The cardinality operator |
|
The escape character (more on this in a moment) |
If you want to include any of these characters in your patterns, you have to escape them if they occur somewhere in the pattern where they have a meaning.
The way you do this is by preceding them with the escape character, \.
If you wanted to match an actual full-stop (aka period) within your RE, you would need to escape it, so, an RE to match an optionally decimal temperature (in Celsius, Fahrenheit, or Kelvin) could be written like so:
[0-9]+(\.[0-9]+)?[CFK]Similarly, an RE to find all optionally decimal dollar amounts could be written as:
\$[0-9]+(\.[0-9]+)?However, we could write this more clearly by using the fact that very few characters have a special meaning within character classes, and hence don’t need to be escaped if they are used in that context:
[0-9]+([.][0-9]+)?[CFK]
[$][0-9]+([.][0-9]+)?As a general rule, this kind of notation is easier to read than using the escape character, so, it’s generally accepted best practice to use character classes where possible to avoid having to escape symbols. This is of course not always possible, but when it is, it’s worth doing in my opinion.
Escape Sequences
As well as being used to escape special characters, the \ operator can also be used to match some special characters or sets of characters, e.g.:
|
matches a |
|
matches a newline character |
|
matches a tab character |
|
matches any digit, i.e.
is equivalent to |
|
matches any non-digit, i.e.
is equivalent to |
|
matches any word character, i.e.
is equivalent to |
|
matches any non-word character, i.e.
is equivalent to |
|
matches any space character, i.e. a space or a tab |
|
matches any non-space character, i.e. not a space or a tab |
|
matches a word boundary (start or end of a word) |
|
matches the start of a word |
|
matches the end of a word |
Note that the above is not an exhaustive list, these are just the escape sequences you’re most likely to come across or need.
Given the above, we could re-write our regular expressions for temperatures and dollar amounts as follows:
\b\d+([.]\d+)?[CFK]\b
\b[$]\d+([.]\d+)?\bWe have also improved our regular expressions by surrounding them in word boundary markers, this means the RE will only match such amounts if they are not stuck into the middle of another word.
For our examples we have been using the standard Unix words file, which has one word per line, so, we have been able to use the start and end of line operators to specify the start and end of words.
However, this would not work if we were searching a file with multiple words on the same line.
To make our examples more generic, replace the ^ and $ dollar operators at the start and end of the patterns with \b (or the start with \< and the end with \>).
Putting it All Together
Given everything we now know, let’s revisit the example we ended with in the previous instalment, our big ungainly RE for matching MAC addresses:
[0-9a-f][0-9a-f]:[0-9a-f][0-9a-f]:[0-9a-f][0-9a-f]:[0-9a-f][0-9a-f]:[0-9a-f][0-9a-f]:[0-9a-f][0-9a-f]We can now re-write it as simply:
[0-9a-f]{2}(:[0-9a-f]{2}){5}The above will do everything our original RE did, but, actually, it’s not as good as it could be, because it really should specify that the entire MAC address should appear as a word, so we should surround it with \b escape sequences:
\b[0-9a-f]{2}(:[0-9a-f]{2}){5}\bTo really get practical, it’s time to stop using the standard Unix words file, and start using more complex input.
Specifically, we’re going to use the ifconfig command which prints the details for all the network devices on a computer.
We’ll be looking at this command in much more detail later in the series, but for now, we’ll just be using the command with no arguments.
To see what it is we’ll be pattern-matching against, run the command on its own first:
ifconfigSo far we have been using the egrep command in its two-argument form, but, it can also be used with only one argument, the pattern to be tested, if the input is passed via STDIN.
We’ll be using stream redirection to pipe the output of ifconfig to egrep.
Let’s use our new MAC address RE to find all the MAC addresses our computer has:
ifconfig | egrep '\b[0-9a-f]{2}(:[0-9a-f]{2}){5}\b'Having created an RE for MAC addresses, we can also create one for IP addresses (IPV4 to be specific):
\b\d{1,3}([.]\d{1,3}){3}\bWe can use ifconfig and egrep again to find all the IP addresses our computer has:
ifconfig | egrep '\b\d{1,3}([.]\d{1,3}){3}\b'So, let’s go right back to the examples we used at the very very start of all this. Firstly, to the RE for domain names:
[a-zA-Z0-9][-a-zA-Z0-9]*([.][a-zA-Z0-9][-a-zA-Z0-9]*)*Hopefully, you can now read this RE as follows:
And finally, to the RE that I promised was a funny joke:
(bb)|[^b]{2}You could read it as:
Or, you could read it as:
Given that Shakespeare’s 450th birthday was last month, it seemed appropriate to include this bit of nerd humour!
We’ve now covered most of the POSIX ERE spec, and probably more than most people will ever need to know, but if you’d like to learn more I can recommend this tutorial.
Some Examples of REs in GUI Applications
Regular expressions make sense when you want to search for things, so, it’s not surprising that you mostly find them in apps where searching is important.
You’ll very often find REs in advanced text editors (not in basic editors like TextEdit.app). Two examples are included below, the Advanced Find and Replace window in Smultron 6, and the Find dialogue in the Komodo Edit 8 cross-platform IDE (the two editors I do all my programming in):
Another place you’ll often find regular expressions is in apps for renaming files, for example, Name Mangler 3 or the bulk-renaming tool within Path Finder:
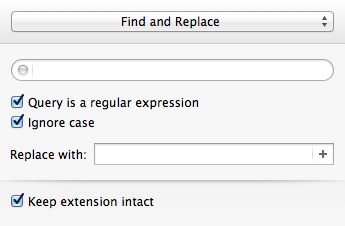
Update (19 Oct 2015) — A Nice Web Tool
Thanks to NosillaCast listener Caleb Fong for recommending a great online RE testing tool which you can find at regex101.com
Next Time …
We’ve now learned enough about REs to move on to looking at command-line tools for searching for text in files, and files in the filesystem. This is what we’ll be moving on to next in this series.
TTT Part 19 of n — Text Searches
In the previous two instalments (17 & 18) of this series, we learned how to represent patterns with regular expressions, or, to be more specific, with POSIX Extended Regular Expression (or EREs).
We used the egrep command to test our regular expressions, but we didn’t discuss the command itself in detail.
Now that we understand regular expressions, it’s time to take a closer look at both egrep, and its older brother grep, both commands for filtering and searching text.
Listen Along: Taming the Terminal Podcast Episode 19
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
To grep or to egrep — that is the question!
The grep command goes back a very long way and has been the staple text-searching command on POSIX operating systems like Unix and Linux for decades.
To this day it’s used millions of times each day for simple text searches.
But, it has a shortcoming — it’s stuck in the past when it comes to regular expressions — grep pre-dates the invention of POSIX ERE!
egrep is identical to grep except that it interprets patterns passed to it as POSIX EREs.
If you can, it’s probably best to get into the habit of always using egrep, and never using grep, but for those of us who’ve been around the block a few times, this could be asking for too much (old habits die hard!).
What I usually do is use grep when I don’t need regular expressions, and egrep when I do.
However, in this series, I’m going to follow my own advice and only use egrep.
egrep Basics
For egrep, lines of text are atomic.
In other words, egrep searches or filters text one line at a time, checking the entire line against the given pattern, and considering the whole line to match the pattern or not.
There are two basic ways in which egrep can be used — it can filter whatever is sent to via standard in (STDIN — see part 15) against a given pattern, or, it can search for lines matching a given pattern in one or more files.
Filtering STDIN
Let’s start with the first use-case, using egrep to filter STDIN.
When egrep is used in this mode it passes every line of text sent to STDIN that matches the given pattern to standard out (STDOUT) and ignores all others.
If you send 5,000 lines of text to egrep via STDIN, and only 5 of those lines match the specified pattern, then only 5 lines will be passed to STDOUT (which is the screen unless the output is redirected elsewhere).
When content is redirected to egrep's STDIN, egrep only needs one argument — the pattern to filter on.
On Unix/Linux/OS X computers configured to act as servers, there will be a lot of log files being written to continuously, and sysadmins will very often need to filter those logs while troubleshooting an issue, or tweaking the server’s configuration.
In my day-job as a Linux sysadmin, I do this all the time.
Regardless of the log file to be filtered, the approach is the same, use tail -f to stream the log file in question to tail's STDOUT in real-time, then redirect that stream to egrep's STDIN with the pipe operator.
For example, on a Linux server running a BIND DNS server process, DNS log entries are mixed with other entries in the central system messages log (/var/log/messages).
When debugging a problem with the DNS server, you don’t want to be distracted by all the other messages flowing into that log file.
The following command will filter that log so that you only see messages from the DNS server process, which all start with the prefix named::
tail -f /var/log/messages | egrep '^named:'The log files on our personal computers are much quieter places, so PC users will rarely find themselves needing to filter log files.
However, that doesn’t mean PC terminal users won’t find themselves wanting to use egrep to filter STDIN.
You can use egrep to filter the output from any command using the pipe operator.
To generate a meaningful example we need a command that will generate a lot of formatted output at will.
We’re going to use a command we’ll come back to in much more detail in future instalments, tcpdump.
As its name suggests, tcpdump prints the details of every TCP packet that enters or leaves your computer to STDOUT.
Every time your computer interacts with the network, tcpdump will generate output — in our modern connected world, that means tcpdump generates a LOT of output!
Firstly, let’s run tcpdump without filtering its output to see just how much network traffic there is on our computers:
sudo tcpdump -i any -nntcpdump will keep capturing traffic until it is interrupted, so when you’ve seen enough, you can exit it with Ctrl+c.
It probably won’t be long until you start seeing packets fly by, but if it’s a bit sluggish, try checking your email or visiting a web page and the packets will soon start to fly!
Now, let’s say we want to watch what DNS queries our computer is making.
Given that DNS queries are over port 53, and that your router is almost certainly your DNS server, we know that all DNS queries will be sent to your router on port 53.
Before we construct the pattern to pass to egrep, we need to find the IP address of our router.
We can do this by filtering the output from another command that we’ll be looking at in much more detail later, netstat.
With the appropriate flags, netstat prints out our computer’s routing table, and the default route in that table is to your router, so filtering the output of netstat for a line starting with the word default will show the IP of your router:
netstat -rn | egrep '^default'When I run this command I get the following output:
default 192.168.10.1 UGSc 32 0 en0This tells me that my router has the IP address 192.168.10.1 (yours will probably be different, very likely 10.0.0.1 or 192.168.0.1, my network is set up a little unusually).
Given this information I can now use egrep to filter the output of tcpdump to show me only my DNS queries with the following command:
sudo tcpdump -i any -nn | egrep '192.168.10.1.53:'You can construct a similar command for your computer by inserting your IP address into the above command.
E.g.
if your router’s IP address is 10.0.0.1 the command will be:
sudo tcpdump -i any -nn | egrep '10.0.0.1.53:'Notice that, rather confusingly, tcpdump adds the port number to the end of the IP as a fifth number.
Note that if we wanted to be really accurate with our regular expression, we would use something like the example below, which is more explicit, and hence much less prone to picking up the odd false positive:
sudo tcpdump -i any -nn | egrep '[ ]192[.]168[.]10[.]1[.]53:[ ]'When you execute your command, visit a few web pages, and watch as DNS queries are sent from your computer to your router. When I visit www.whitehouse.gov I get the following output:
bart-imac2013:~ bart$ sudo tcpdump -i any -nn | egrep '[ ]192[.]168[.]10[.]1[.]53:[ ]'
tcpdump: data link type PKTAP
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type PKTAP (Packet Tap), capture size 65535 bytes
16:07:33.855986 IP 192.168.10.42.62854 > 192.168.10.1.53: 14228+ A? www.whitehouse.gov. (36)
16:07:34.032251 IP 192.168.10.42.63205 > 192.168.10.1.53: 18279+ A? s7.addthis.com. (32)
16:07:34.247111 IP 192.168.10.42.61908 > 192.168.10.1.53: 61513+ A? ct1.addthis.com. (33)
16:07:34.324604 IP 192.168.10.42.49410 > 192.168.10.1.53: 19744+ A? wwws.whitehouse.gov. (37)
16:07:34.374799 IP 192.168.10.42.51554 > 192.168.10.1.53: 27443+ A? www.youtube-nocookie.com. (42)
16:07:34.664967 IP 192.168.10.42.54293 > 192.168.10.1.53: 17308+ A? search.usa.gov. (32)
16:07:35.968991 IP 192.168.10.42.55988 > 192.168.10.1.53: 34309+ A? www.letsmove.gov. (34)
16:07:35.969510 IP 192.168.10.42.63332 > 192.168.10.1.53: 32194+ A? apply.whitehouse.gov. (38)
16:07:35.969644 IP 192.168.10.42.54380 > 192.168.10.1.53: 11407+ A? t.co. (22)
16:07:35.969823 IP 192.168.10.42.54328 > 192.168.10.1.53: 32595+ A? plus.google.com. (33)
16:07:35.970295 IP 192.168.10.42.53706 > 192.168.10.1.53: 58317+ A? usa.gov. (25)
16:07:35.970528 IP 192.168.10.42.61971 > 192.168.10.1.53: 4237+ A? www.twitter.com. (33)
16:07:36.425466 IP 192.168.10.42.49283 > 192.168.10.1.53: 18130+ A? www-google-analytics.l.google.com. (51)
16:07:36.429381 IP 192.168.10.42.56459 > 192.168.10.1.53: 18915+ A? vimeo.com. (27)
16:07:36.429535 IP 192.168.10.42.55061 > 192.168.10.1.53: 4390+ A? petitions.whitehouse.gov. (42)
16:07:36.429677 IP 192.168.10.42.58086 > 192.168.10.1.53: 51451+ A? twitter.com. (29)
16:07:36.441638 IP 192.168.10.42.57427 > 192.168.10.1.53: 7567+ A? searchstats.usa.gov. (37)
16:07:36.442115 IP 192.168.10.42.59259 > 192.168.10.1.53: 62371+ A? s.ytimg.com. (29)
16:07:36.584244 IP 192.168.10.42.65060 > 192.168.10.1.53: 58436+ A? www.facebook.com. (34)
16:07:36.584542 IP 192.168.10.42.65022 > 192.168.10.1.53: 16848+ A? www.linkedin.com. (34)
16:07:36.585051 IP 192.168.10.42.58670 > 192.168.10.1.53: 10667+ A? www.flickr.com. (32)
16:07:36.585184 IP 192.168.10.42.49857 > 192.168.10.1.53: 14702+ A? foursquare.com. (32)
16:07:36.684281 IP 192.168.10.42.61667 > 192.168.10.1.53: 30012+ A? www.google.com. (32)
16:07:36.972650 IP 192.168.10.42.61971 > 192.168.10.1.53: 4237+ A? www.twitter.com. (33)
16:07:37.152113 IP 192.168.10.42.62562 > 192.168.10.1.53: 64882+ A? m.addthis.com. (31)
16:07:38.223524 IP 192.168.10.42.56628 > 192.168.10.1.53: 34626+ A? i1.ytimg.com. (30)
^C3125 packets captured
3125 packets received by filter
0 packets dropped by kernel
bart-imac2013:~ bart$This gives you some idea of just how many resources from disparate sources get pulled together to create a modern web page!
Searching Files
Let’s move on now to using egrep to search the contents of one or more files for a given pattern.
When using egrep to search file(s), it requires a minimum of two arguments, first the pattern to be searched for, and secondly at least one file to search.
If you want to search multiple files, you can keep adding more file paths as arguments.
In this mode, egrep will filter the lines in the file in the same way it did when filtering a stream, but if you ask it to filter more than one file it will prepend any output with the name of the file the matching line came from.
This is a very useful feature.
The vast majority of the examples we used in the previous two instalments used egrep to search the Unix words file.
As a quick reminder, the following command will find all lines in the words file that start with the letters th:
egrep '^th' /usr/share/dict/wordsA very common use-case for using egrep on a single file is to quickly check a setting in a configuration file.
For example, on a Linux web server with PHP installed, you could use the command below to check the maximum file upload size the server is configured to accept:
egrep '^upload_max_filesize' /etc/php.iniOn a server with a default PHP install that will return the following output:
upload_max_filesize = 2MMost of us are probably not running web server processes on our personal computers, so let’s look at a more practical example.
On any POSIX OS (Linux, Unix or OS X), you can see what DNS server(s) are configured by searching the file /etc/resolv.conf for lines beginning with the word nameserver.
The following command does just that:
egrep '^nameserver' /etc/resolv.confSo far we have only searched one file at a time, but you can point egrep at as many files as you like, either explicitly, or by using shell wild card expansion.
For example, the command below looks for lines containing apple.com in all the log files in the folder /var/log:
egrep 'apple[.]com' /var/log/*.logUseful egrep Flags
egrep is a very powerful command that supports a staggering array of flags.
We couldn’t possibly go through them all here.
Remember, you can use the man pages to see everything egrep can do:
man egrepHowever, there are a few flags that are so useful they bear special mention.
Firstly, to make egrep case-insensitive, you can use the -i flag.
If you’re not sure of the capitalisation of the text you’re looking for, use egrep -i.
If you want to see the line numbers within the files for all the matches found by egrep you can use the -n flag.
And finally, the biggie, you can use the -r flag to recursively search every single file in a given directory.
Be careful with this one — if you ask egrep to search too much, it will take a very long time indeed to finish!
Final Thoughts
In this instalment, we’ve seen how egrep can be used to filter a stream or to search one or more files for lines of text matching a specified pattern.
This is very useful, and something sysadmins do a lot in the real world.
In the next instalment we’ll be moving on to a different, but equally important, type of search — file searches.
We’ll use the aptly-named find command to find files that meet one or more criteria.
find supports a huge variety of different search criteria, including simple things like the name of the file, and more advanced things like the amount of time elapsed since the file was last edited.
All these criteria can be combined to create powerful searches that will show all MS Office files in your Documents folder that were edited within the last week and are bigger than 1MB in size.
TTT Part 20 of n — File Searches
In the previous instalment, we looked at using egrep to search for a particular piece of text in a stream or file.
egrep is often a great tool for finding a file you are looking for, but only if the file is a plain text file, and only if you are searching for that file based on its content.
What if you want to search for files based on other criteria, like the last time the file was edited, or the name of the file, or the size of the file, or the type of the file etc.?
For that, you need a different command, for that you need find.
Listen Along: Taming the Terminal Podcast Episode 20
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
The Basics of the find Command
Regardless of the criteria you wish to use, the basic form of the find command is always the same, you first need to tell it where to look, then you tell it what criteria to use when searching:
find path criteria 1 [criteria 2 ...]The path is searched recursively (by default), so if you give a path of ~/Documents, it will search your documents folder and all folders within your documents folder.
To search your entire computer, and all mounted drives, use a path of just /.
To use the current folder as the base of your search use a path of . (which always means ‘the current folder’ as we learned in instalment 4).
Defining Search Criteria
To see a full list of all possible search criteria, you can, of course, read the manual entry for find with the command man find, but we’ll look at some of the more common criteria you’ll be most likely to need here.
Search by File Name
You can do simple file-name searches with the -name flag followed by a simple pattern.
Note that these simple patterns are NOT regular expressions, they use the same syntax as wild card expansion in BASH, i.e.
* means any number of any characters, and ? means exactly one of any character.
A lot of the time you really don’t need the added power and complexity of regular expressions, because a lot of the time all you really want is the good old fashioned DOS pattern *.extension.
remember that * and ? have meanings in BASH, so you need to escape them in some way to get reliable results.
It’s ugly and hard to read * all over the place, so my suggestion is to get into the good habit of ALWAYS quoting your patterns when using -name.
|
Let’s start with a really simple example, you know the full name of the file you’re looking for, but, you have no idea where it is.
This is something you often come across when someone asks you to take a look at their server.
You know you need to edit, say, php.ini, but you have no idea where their version of PHP is installed (this is very common when using web server packages for OS X like MAMP or XAMPP). The command below will find all files called php.ini anywhere in your computer:
find / -name 'php.ini'
if you’re going to search your whole computer (like we did above), you’ll see a lot of ‘permission denied’ errors.
To avoid this, run the command with sudo, or, if you want to just ignore the errors, redirect STDERR to /dev/null with 2>/dev/null like we learned in instalment 16.
|
Something else you very often want to do is find all files of a given extension in a given location. For example, the command below will list all text files in your home directory:
find ~ -name '*.txt'You can get more creative by looking for all text files with names starting with a b:
find ~ -name 'b*.txt'Or all text files with a four-letter name with a as the second letter:
find ~ -name '?a??.txt'JPEG files are an interesting case, you’ll very often see them with two different extensions, .jpg or .jpeg, how can we search for those without using regular expressions?
The key is the -or flag.
So, to look for files ending in either .jpg or .jpeg in our home directory, we could use the following:
find ~ -name '*.jpg' -or -name '*.jpeg'It looks like we’ve cracked it, but actually, we haven’t fully.
Some cameras, for reasons I simply cannot fathom, use the extension .JPG instead of .jpg or .jpeg.
To get around this we could either add two sets of -or -name criteria, or, we could do a case-insensitive name-search by replacing -name with -iname.
This gives us a final JPEG-finding command of:
find ~ -iname '*.jpg' -or -iname '*.jpeg'Easily 90% of the time -name and -iname will be all you need to achieve your goals, but, sometimes, you really do need the power of full regular expressions.
When this is the case, you can use the -regex or -iregex flags (-iregex being the case-insensitive version of -regex).
There are two very important caveats when using regular expressions with find.
Firstly, unlike with -name, -regex and -iregex do not match against just the file name, they match against the entire file path.
It’s important that you remember this when constructing your patterns, or you’ll get unexpected results, either false positives or false negatives.
Secondly, by default -regex and -iregex use Basic POSIX Regular Expressions (BREs), rather than the newer Extended POSIX Regular Expressions (EREs) we learned about in instalments 17 and 18.
Don’t worry, you can make find use EREs, you just need to add a -E flag to the start of the command (before the path).
Given our knowledge of regular expressions, we could re-write our JPEG search as follows:
find -E ~ -iregex '.*[.]jpe?g'Again, like with egrep in the previous instalment, notice that we are quoting the RE to stop Bash wrongly interpreting any of the special characters we may need like * and ? in the above example.
Also notice the position of the -E flag, and that we don’t need to use ^ or $ because the ENTIRE path has to match for the result to validate.
This also means that without the .* at the start of the pattern no files will be returned.
Searching Based on Modified Time
Very often, we need to find something we were working on recently, and the key to finding such files is to search based on the time elapsed since a file was last modified.
We can do just that with the -ctime flag (for changed time).
By default -ctime works in units of days, however, we can explicitly specify the units of time we’d like to use by appending one of the following after the number:
|
seconds |
|
minutes |
|
hours |
|
days |
|
weeks |
Unless you specify a sign in front of the number, only files modified EXACTLY the specified amount of time in the past will be returned. That’s not usually useful. Instead, what you generally want are all files modified less than a certain amount of time ago, and to do that you add a minus sign before the number.
So, to find all files in your Documents folder that have been updated less than an hour ago you could use:
find ~/Documents -ctime -1hSearching Based on File Size
Another criteria we may want to search on is file size.
We can do this using the -size flag.
The default units used by -size are utterly unintuitive — 512k blocks!
Thankfully, like -ctime, -size allows you to specify different units by appending a letter to the number.
The following units are supported:
|
Characters (8-bit bytes) |
|
KiB = 1024 bytes |
|
MiB = 1024KiB (notice the case — must be upper!) |
|
GiB = 1024MiB (notice the case — must be upper!) |
|
TiB = 1024GiB (notice the case — must be upper!) |
|
PiB = 1024TiB (notice the case — must be upper!) |
Note that this command uses the old 1024-based sizes, not the 1,000 based SI units used by OS X and hard drive manufacturers (and scientists and engineers and anyone who understands what kilo and mega, etc. actually mean).
Also, like with -ctime, if you don’t prefix the number with a symbol, only files EXACTLY the size specified will be returned.
For example, the following command shows all files in your Downloads folder that are bigger than 200MiB in size:
find ~/Downloads -size +200MSimilarly, the following command shows all files in your Downloads folder smaller than 1MiB in size:
find ~/Downloads -size -1MFiltering on File ‘type’
When I say file type, I mean that in the POSIX sense of the word, not the file extension sense of the word. In other words, I mean whether something is a regular file, a folder, a link, or some kind of special file.
The type of a file can be filtered using the -type flag followed by a valid file type abbreviation.
The list below is not exhaustive, but it covers everything you’re likely to need:
|
a regular file |
|
a directory (AKA folder) |
|
a symbolic link |
This flag will almost always be used in conjunction with one or more other search flags.
For example, the following command finds all directories in your documents folder that contain the word temp in their name in any case:
find ~/Documents -type d -iname '*temp*'Inverting Search Parameters
In most situations, it’s easiest to express what it is you want to search for, but sometimes it’s easier to specify what you don’t want.
In situations like this, it can be very useful to be able to invert the effect of a single search parameter.
You can do this with the -not flag.
For example, you may have a folder where you keep your music, and it should only contain MP3 files and folders.
To be sure that’s true you could search for all regular files that do not end in .mp3 and are not hidden (like those ever-present .DS_Store files) with a command like:
find ~/Music/MyMP3s -type f -not -iname '*.mp3' -not -name '.*'Limiting Recursion
By default the find command will drill down into every folder contained in the specified path, but, you can limit the depth of the search with the -maxdepth flag.
To search only the specified folder and no deeper use -maxdepth 1.
Note that limiting the depth can really speed up searches of large folders if you know what you want is not deep down in the hierarchy. For example, if you have a lot of documents in your documents folder it can take ages to search it, but, if you are only interested in finding stuff at the top level you can really speed things up. Let’s say we are the kind of person who makes lots of temp folders at the top level of their Documents folder (guilty as charged), and you want to find them all so you can do a bit of housekeeping, you could search your entire Documents folder with:
find ~/Documents -type d -iname '*temp*'When I do this it takes literally minutes to return because I have over a TB of files in my Documents folder.
I can get that down to fractions of a second by telling find that I’m only interested in the top-level stuff with:
find ~/Documents -type d -iname '*temp*' -maxdepth 1Combining Search Criteria (Boolean Algebra)
We’ve already seen that we can use the -or and -not flags, but there is also a -and flag.
In fact, if you don’t separate your criteria with a -or flag, a -and flag is implied.
The following example from above:
find ~/Music/MyMP3s -type f -not -iname '*.mp3' -not -name '.*'Is actually interpreted as:
find ~/Music/MyMP3s -type f -and -not -iname '*.mp3' -and -not -name '.*'We can even take things a step further and add subexpressions using ( and ) to start and end each subexpression (they can even be nested).
Note that ( and ) have meaning in BASH, so they need to be either escaped or quoted.
Since I find escaping makes everything hard to read and understand, I recommend always quoting these operators.
As a final example, the following command will find large PowerPoint presentations in your Documents folder, i.e.
all files bigger than 100MiB in size that end in .ppt or .pptx.
find ~/Documents -size +100M '(' -iname '*.ppt' -or -iname '*.pptx' ')'Conclusions
In this instalment, we’ve seen that we can use the find command to search for files based on all sorts of criteria and that we can combine those criteria using boolean algebra to generate very powerful search queries.
In the next instalment, we’ll discover that you can use the find command not only to search for files but to apply an action to every file it finds.
The find command is common to all POSIX operating systems, so it works on Linux, Unix, and OS X.
OS X maintains an index of your files allowing quick searching in the Finder and via Spotlight.
Because this index is kept up to date by the OS, it makes searching with Spotlight much quicker than searching with find.
In the next instalment, we’ll also discover that OS X ships with a terminal command that allows you to use the power of Spotlight from the command line!
TTT Part 21 of n — More Searching
This is the third and final instalment on searching.
In the first instalment on find, we learned how to search for text within files and streams using egrep.
In the second, we learned to search for files based on all sorts of criteria with the find command.
In this final instalment, we’ll start by looking at one last feature of find, its ability to execute commands on the files it finds.
Then we’ll end by looking at an OS X-only alternative to find that makes use of the Spotlight search index to really speed up searches.
Listen Along: Taming the Terminal Podcast Episode 21
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Executing Commands with find
The final trick find has up its sleeves is that it can be used to execute a given command on all the files it finds.
Depending on the command you choose to execute, this could be VERY dangerous indeed, so tread carefully!
Definitely think twice before using the execute feature in `find`å to delete files!
To execute commands on the results of find you need to use the -exec flag in conjunction with the {} flag and either the ';' or '+' flags.
The reason there are two end flags is that there are two modes in which find can execute commands.
It can either execute the same command once on each file that was found or, it can execute the given command once only with all the found files as arguments.
Executing a Command on Each File/Folder Found
To execute a command repeatedly, once on each file or folder found, you use the following construct:
find search_path conditions -exec command args_or_flags {} ';'The -exec flag means we are about to start specifying a command to execute, and everything up to the ';' will be a part of that command.
{} is the point in the command where the found file should be inserted.
This sounds quite complicated, but hopefully, a practical example will help. A real-world problem you may encounter is that you need to make all Perl scripts in a given set of nested folders executable. As we learned in instalment 6, we can make a file executable with the command:
chmod 755 path_to_filePerl scripts have the extension .pl, so using what we learned in the previous instalment we can find all Perl scripts in a given path with the command:
find search_path -name '*.pl'If we assume all our Perl files will be in a folder called scripts in our Documents folder, we can put all this together to find and chmod all Perl files in a single command like so:
find ~/Documents/scripts -name '*.pl' -exec chmod 755 {} ';'Executing A Command Once with All Files/Folders Found as Arguments
Sometimes we may want to run a command once with all the found files and/or folders as arguments. You can do that with the following construct:
find search_path conditions -exec command args_or_flags {} '+'Like before, {} indicates where the found files and folders should be included in the command, and the '+' on the end indicates the end of the command, and that the command should be run once with all the results as arguments.
Again, a practical example might be helpful.
Let’s say you’re doing up a report on just how much work went into a coding project.
You want to know how many lines of code you wrote, and you know that all your code is in Perl scripts and Perl modules, i.e.
you know all relevant files have .pl and .pm file extensions.
We know from last time that we can find all relevant files with the command:
find search_path -name '*.pl' -or -name '*.pm'We also know from instalment 15 that we can use the wc command with the -l flag to count the number of lines in one or more files:
wc -l file 1..nAssuming our code is still in a folder called scripts in the Documents folder, the command to find the total number of lines in all the Perl files would be:
find ~/Documents/scripts '(' -name '*.pl' -or -name '*.pm' ')' -exec wc -l {} '+'Note that we have to group the two conditions in bracket operators so the scope of the -or is clear.
If you installed the XKPasswd 2 Perl module via the quick install instructions at https://github.com/bbusschots/xkpasswd.pm, you can use the example below to see how many lines of code and documentation went into that project:
find /usr/local/xkpasswd.pm '(' -name '*.pl' -or -name '*.pm' ')' -and -not -type d -exec wc -l {} '+'One final example that might depress you — the command below tells you how much disk space you are wasting with large files (>500MiB) in your downloads folder:
find ~/Downloads -size +500M -exec du -ch {} '+'If you are VERY careful you can use find -exec to do things like clean up cache folders by deleting anything older than a given amount of time, and other cool and powerful things.
But — ALWAYS be careful when using -exec to invoke a command that alters or destroys files or folders.
My approach is to run the command without the -exec first, to be sure ONLY the files and folders you expected to be found are being returned.
Finally — the nerd joke I think I promised during the last instalment:
find / -iname '*base*' -exec chown -R us {} ';'(If you don’t get it, this might help.)
OS X Only — Spotlight from the Terminal
On OSX the operating system indexes the files on your computer so you can quickly search them with Spotlight.
Rather than having to search through all the files, Spotlight just searches the index, which makes it much faster than find when searching through big chunks of the file system.
Apple has very kindly exposed the power of Spotlight to the command line with the very useful mdfind command.
If you can type it into the Spotlight text box in the top-left of a Finder window and get back a list of files, you can pass the same query to mdfind, and it will find the same results.
Note that I said Spotlight in the Finder, and not in the menubar — that was not by accident.
mdfind is only for finding files, not for all the other fancy stuff you can do with Spotlight in the menu bar like the calculator function or the ability to get dictionary definitions.
Another important caveat is that mdfind can only find files in folders indexed by Spotlight.
If you add a drive or a folder to Spotlight’s ignore list, mdfind can never find files on those drives or folders.
The mdfind command is very easy to use:
mdfind 'spotlight search string'For example, to find all PDFs on your computer you could use:
mdfind 'kind:pdf'To find all PDFs that contain the word ‘internet’ you could use:
mdfind 'kind:pdf internet'To find every PDF you have edited today you could use:
mdfind 'date:today kind:pdf'I haven’t been able to find a definitive list of all possible Spotlight search commands, but googling for ‘spotlight syntax’ will lead to useful articles like this one.
mdfind supports a number of arguments, and it can also search based on deep metadata, but I’m going to leave most of that as an exercise for the user — you can get the full documentation through the manual:
man mdfindHowever, there are two flags I do want to draw attention to.
By default mdfind will search the entire Spotlight index, but you can ask it to only return results contained within a given folder using the -onlyin flag, for example, to find all PDFs in your Documents folder you could use:
mdfind -onlyin ~/Documents 'kind:pdf'Note that the search is always recursive, even when using the -onlyin flag.
The other flag I want to mention is -count. If this flag is set the number of matching files will be returned rather than the files themselves.
So, to see how many music files you have in your Music folder you could use:
mdfind -onlyin ~/Music -count 'kind:music'Or, to answer the eternal question of just how many apps you have installed:
mdfind -onlyin /Applications -count 'kind:app'Final Thoughts
We have now seen how to filter streams and search files with egrep, and we’ve learned how to search for files with find and mdfind.
That brings us to the end of the searching topic, at least for now.
The next big topic will be networking, but before we start into such a big topic we’ll take a break for a fun little tips and tricks instalment.
TTT Part 22 of n — Tips & Tricks
This instalment is a little breather between the fairly heavy instalments on searching and the upcoming set of instalments on networking. We’ll start with a look at some tips and tricks for getting the most out of BASH, and then transition to some tips and tricks for getting the most out of the OS X Terminal app.
Listen Along: Taming the Terminal Podcast Episode 22
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Bash Tips & Tricks
Repeating Previous Commands
Bash provides a number of different ways to repeat commands you’ve executed in the past.
The simplest command of all of these is !!.
You can use this on its own:
cc-dsk-2ss:Desktop bart$ ls -l
total 96
-rw-r--r--@ 1 bart staff 21301 1 Oct 15:15 Screen Shot 2014-10-01 at 15.15.44.png
-rw-r--r--@ 1 bart staff 20982 1 Oct 15:15 Screen Shot 2014-10-01 at 15.15.55.png
cc-dsk-2ss:Desktop bart$ !!
ls -l
total 96
-rw-r--r--@ 1 bart staff 21301 1 Oct 15:15 Screen Shot 2014-10-01 at 15.15.44.png
-rw-r--r--@ 1 bart staff 20982 1 Oct 15:15 Screen Shot 2014-10-01 at 15.15.55.png
cc-dsk-2ss:Desktop bart$You’ll see that when you issue !! as a command, the first thing it does is print out what it is that is being executed, then it does it.
You don’t have to use !! on its own, you can use it to represent your previous command as part of a new, larger command. For example, you may want to try a command to be sure it does what you think, and then, when you know it does, pipe the output to a file, or to another command:
cc-dsk-2ss:Desktop bart$ find ~/Downloads -iname '*.iso'
/Users/bart/Downloads/CentOS-6.5-x86_64-bin-DVD1.iso
/Users/bart/Downloads/CentOS-6.5-x86_64-LiveDVD.iso
cc-dsk-2ss:Desktop bart$ !! | wc -l
find ~/Downloads -iname '*.iso' | wc -l
2
cc-dsk-2ss:Desktop bart$The !! command lets you go back just a single command, you can go back further using the up arrow key (and the down arrow key if you go past the command you wanted by mistake).
|
By default Bash on OS X (and RHEL/CentOS Linux) saves every command you execute into its history, so if you run the same command four times in a row, you will have to hit the up arrow four times to get past it in the history.
You can alter this behaviour by setting the environment variable Ubuntu does this by default, and I find it a much nicer way of working, so much so that I add the above command to my |
Scrolling through the Bash history is very useful, but sometimes you need to do a more powerful search of previously executed commands, this is where the reverse history search comes in. To enter into this search mode hit Ctrl+r, your prompt is now replaced with:
(reverse-i-search)':As you type, what you enter will appear before the :, and the most recent matching command will appear after the :.
To accept a match just hit enter and you’ll return to the regular prompt with that command entered and your cursor positioned at the end of the command.
To search for older matches to the same search string hit Ctrl+r again, and if you go past the one you wanted, hit Ctrl+Shift+r to go the other way.
This all sounds more complicated than it is, and with a little practice, you’ll soon get the hang of it.
Moving the Cursor to the Start of a Command
You can move the cursor within a command with the left and right arrow keys, but if you use the up and down arrows or Ctrl+r to search the history your cursor will always be placed at the end of the command, and you will often need to edit the start of the command. You can just use the left arrow key until you get there, but with long commands this can be a real pain. Ctrl+a will jump the cursor to the start of the command.
OS X Terminal Tips & Tricks
Dragging & Dropping
If you drop a file or folder onto the Terminal its path will be typed into the Terminal. This includes proxy icons at the top of document windows, the folder proxy icons at the top of Finder windows, and the folder proxy icon at the top of other Terminal windows.
Opening Files & Folders From the Terminal
You can use the open command to open files from the Terminal as if you had double-clicked them in the Finder.
The usage is very simple:
open PATH_TO_FILE [...]With this basic usage, OS X will open the file with the default app for the given file type.
If you use open on a folder then that folder will open in the Finder.
For example, you can open the current folder your Terminal is in with the command:
open .The open command is also very useful for accessing hidden folders in the Finder, e.g.:
open ~/LibraryIf you want to open a file or folder with an app that is not the default app, you can use the -a flag to tell open which app to open the file or folder with.
For example, the following command will open your ~/.bash_profile file in TextEdit:
open ~/.bash_profile -a /System/Applications/TextEdit.app/Because using a text editor is a common thing to want to do, open supports a shortcut especially for opening files in TextEdit.
Rather than using -a System/Applications/TextEdit.app/, you can just use -e instead, so we could re-write the previous command as:
open ~/.bash_profile -eFinally, you can also use open to reveal a given file in the Finder, you can do that with the -R flag.
E.g.:
open -R /etc/hostsNote that this will not work for hidden files.
Final Thoughts
Hopefully, you’ll find at least some of these tips and tricks useful, and find yourself being a little more efficient on the command line.
In the next instalment, we’ll make a start on what will be a quite long series on networking. We’ll start by laying a theoretical foundation, and then get stuck in with a selection of network-related terminal commands.
TTT Part 23 of n — Networking Intro
This instalment is the first in what will probably be quite a long mini-series on computer networking. Before we can look at the terminal commands that allow us to interact with the network, we need to gain an understanding of how computer networking works. This is a complex topic, ad there’s a lot to take in. The individual pieces don’t make sense without keeping the big-picture in mind, and yet the big picture doesn’t gel together until you start to understand the detail.
Bearing that in mind, this instalment starts the series with a big-picture overview. We’ll flesh this overview out over the instalments that follow, adding in the detail that will hopefully make the whole thing click for you. Ultimately, it’s actually a very elegant design, but that elegance may not be immediately obvious!
Listen Along: Taming the Terminal Podcast Episodes 23a & 23b
| Episode 23a | Episode 23b |
|---|---|
Scan the QR code to listen on a different device |
|

|

|
You can also play/download the MP3 in your browser (a) |
You can also play/download the MP3 in your browser (b) |
As complicated as computer networks are today, they’ve actually gotten a lot simpler than they used to be, for the simple reason that everyone has settled on a single protocol stack — the so-called TCP/IP stack. Because TCP/IP is the clear winner, it’s the only kind of networking we need to look at in this series. Had we been doing this 20 years ago, things would have been very different, with different companies each using their own suites of networking protocols. E.g. Apple used AppleTalk, DEC used DECnet, and Microsoft used NetBIOS/NetBEUI.
The TCP/IP Network Model
The internet, and our home and work networks, are all TCP/IP networks. What we now call TCP/IP started life as ARPANET, a project run by the US Advanced Research Projects Agency, or ARPA (today this same institution is called DARPA, the D standing for Defense). For home users, the internet is a 1990s phenomenon, but DARPANET became operational way back in 1969.
The age of TCP/IP is a mixed blessing. On the one hand, it’s been around more than long enough to have most of the bugs shaken out of it. But, on the other hand, it was designed before anyone understood what it would become, so problems like security simply weren’t considered in the design. Security has had to be retrofitted afterwards, and that’s not exactly been a smooth process!
Key Design Features
-
TCP/IP breaks data into small manageable chunks called packets, and each packet travels across the network independently. The techno-jargon for this is that TCP/IP networks are packet switched networks.
-
TCP/IP is a best-effort protocol suite — routers can drop packets if they need to.
-
TCP/IP is a strictly layered stack of protocols — interactions are only possible between adjacent protocols. Ethernet talks to IP, IP talks to TCP, TCP talks to TLS, TLS talks to HTTP, and vice-versa, but HTTP can never skip over TLS, TCP & IP, and talk directly to Ethernet.
-
There are many more than four protocols in the stack, but they are grouped into four categories called network abstraction layers:
-
The Link Layer
-
The Internet Layer
-
The Transport Layer
-
The Application Layer
-
-
Only protocols adjacent to each other in the stack can communicate with each other, and all communication is through well defined APIs (Application Programming Interfaces).
You can think of the protocols in the stack as having agreed contracts with adjacent protocols. Each protocol advertises the functionality it offers, and it specifies what information it needs to be given in order to deliver that functionality. Adjacent protocols only need to understand the contracts, not how those contracts are fulfilled. This is particularly powerful at the link layer, where it allows the practicalities of the physical media the data is travelling over to be abstracted away from the layers above.
The Four Network Abstraction Layers
1 — The Link Layer
The link layer allows a single packet of data to be sent within a network. Assuming you have only one home network, then the link layer allows packets to get from any one device on your home to any other device on your home.
Within our home networks, the Ethernet protocol is used to transmit packets. Ethernet uses MAC (Media Access Control) addresses to specify the source and destination for each packet. We actually use two different implementations of Ethernet within our homes — we use network cards that send Ethernet packets other over twisted pairs of copper wire, officially called UTP Patch Cables, but almost universally (and technically incorrectly) known as Ethernet cables. We also use network cards that use radio waves to transmit Ethernet packets, and we call this WiFi.
Because of the layering of network protocols, nothing higher up the stack needs to take any account whatsoever of how the data got from one device to another. All the protocol above has to know is that Ethernet can send a packet from one MAC address to another. How that’s achieved is irrelevant to that protocol.
Ethernet doesn’t have the game all to itself within Layer 1. Sure, it gives us what we call wired and wireless networks, but there are other ways to get data from one end of a physical connection to another. For example, there is a protocol called FiberChannel that can send data through fiber optic cables, ISDN & ADSL can get data over a phone line, and there are more protocols for getting data through TV cables than you can shake a proverbial stick at!
The key point is that no matter what protocols are used in Layer 1, the protocols used in the layers above don’t care at all about the practicalities, all that matters is the contracts between protocols.
2 — The Internet Layer
The link layer can move a packet of data between any two devices within a single network. Layer two takes things a step further, allowing for the movement of a single a packet of data between any two devices located anywhere within a set of connected networks.
Networks are connected to each other by routers. A router is a device with at least two network interfaces, one in each connected network. Our home routers usually connect just two networks together, our home network and our ISP’s network. But, the routers within our ISPs and within the internet backbone usually connect many more than two networks to each other.
A set of interconnected networks is known as an internetwork or internet, and The Internet is just the biggest internetwork in the world. The Internet is to internets what the Moon is to moons. I could create three logical networks in my house, and connect them together with some routers, and I would have created my own internet. The Internet is only special in that it’s the internet we as a planet have decided to use for planet-wide computer-to-computer communication. This is why it’s grammatically correct to capitalise the Internet when you’re talking about that world-wide network we all love so much.
One of the most amazing things that the internet layer is responsible for is figuring out how packets can get from any one point on an internet to any other arbitrary point anywhere else on that internet, even when the shortest route between those two points often crosses tens of routers. This really complex task is known simply as ‘routing’, and that it works at all really has to be one of the seven wonders of the digital world!
There is only one Layer 2 protocol in use on the Internet and our home networks, and that’s the Internet Protocol, or simply the IP protocol. The IP protocol addresses devices with IP addresses. There are two IP addressing schemes in use today, IPv4, and IPv6.
Within our routers is where we first begin to see the power of protocol stacking. Routers are Layer 2 devices, but they have to use Layer 1 to move packets around. Our home routers all speak IP, but they also have to speak one or more Layer 1 protocols. Because all our home networks are Ethernet networks, our routers all speak Ethernet, but it’s the other protocols the routers speak that divide them into groups. ADSL modems speak ADSL and Ethernet, ISDN routers speak ISDN and Ethernet, cable modems speak at least one of the zoo of cable modem protocols, and Ethernet. As a packet moves from router to router, it moves up and down the stack from IP to Ethernet to get from your computer to your router, and then back up to IP so the router can figure out what to do with the packet. If it’s for the internet, then it goes down to, say, ADSL, then it arrives at your ISP’s router where it again gets handed up the stack to the IP. IP then decides which direction to send it in next, then it uses a Layer 1 protocol to send that packet to the next router, perhaps by fiber optic cable, perhaps by satellite link, it doesn’t matter, it will arrive at the other end, get brought up the stack to IP, and then the next router will send it along the next Layer 1 link. The key point is that the same IP packet can be sent over lots of different Layer 1 protocols as it moves across an internet from its source IP address to its destination IP address.
Finally, it should be noted that the IP protocol is a complex beast, and while it’s mostly used to send packets of data, known as datagrams, from one IP address to another, it can do more. The key to this is that the IP protocol contains a bunch of subprotocols. For example, IGMP allows for so-called multi-cast traffic where a single packet gets delivered to many recipients instead of one. Another subprotocol we’ll be seeing again is ICMP, which is used for network troubleshooting.
3 — The Transport Layer
Layers one and two deal with single packets of data. We usually want to send or receive a lot more than a single packet, so we need to layer some protocols on top of IP to deal with that reality.
Remember, each packet is treated as being entirely independent by layers one and two, and each packet is delivered on a best effort basis. So if we send 100 packets, it’s likely one or more of them will go missing, and it’s also very likely that the ones that do arrive will arrive out of order. Because the Internet is very heavily interconnected, unless your source and destination are directly connected by a single router, there are almost always many different possible paths through the Internet between any two IP addresses. ISPs will usually have many interconnections with other ISPs, and they will load balance packets across these different interconnections. The algorithm could be as simple as “send 10 packets this way, then 5 that way, then 20 that other way, repeat”. Even if our 100 packets all get to that router one after the other, they’ll get separated into little groups spread over those three different routes. Then they’ll meet another router which may separate the groups of packets into even smaller groups and so on. By the time the surviving packets all get to the destination IP address, they really could be in any order, and of course, every router along the way has the choice to drop a packet if it gets overloaded.
Layer 3 protocols organise data flows into streams of related packets known as connections. Layer 3 also introduces the concept of port numbers. A Layer 3 connection has a source IP address and port, and a destination IP address and port.
There are two Layer 3 protocols in common use today, TCP, and UDP.
UDP (User Datagram Protocol) is the simplest of the two protocols. UDP is still a best-effort protocol, and there is still no concept of packets (known as datagrams) being related to one another. UDP does introduce the concept of source and destination port numbers though, allowing the datagrams to be routed to individual applications or services on the receiving device. There is no guarantee that a stream of UDP datagrams sent from the same source to the same destination will arrive in the order they were sent. It’s up to the receiving application or service to decide what to do about out of order data. It’s very common for out of order packets to be ignored by the recipient.
You might ask yourself, why would anyone want a protocol that’s happy to let data go missing? The answer is that it’s fast. By not waiting around for straggler packets you can get close to real-time streams of data, even if it is imperfect data. So, when speed matters more than perfection, UDP is the right choice. This is why UDP is often used for streaming media, and for internet voice chat services like Skype. As well as speed, UDP also has the advantage of being simple, so it’s CPU and RAM efficient, which is why it’s also used for very high-volume protocols like DNS and syslog (more on DNS in future instalments).
TCP (Transmission Control Protocol) takes things a step further and promises to transmit a stream of data from one IP address to another in such a way that all data that is sent arrives, and all data arrives in the order in which it was sent. It does this using buffers. The sender holds a copy of all sent packets in a buffer in case they go missing and have to be resent, and the receiver uses a buffer to reassemble the data back into the right order. Packets that come in are added to the buffer with gaps being left for their delayed friends. If a packet takes too long to arrive, it’s assumed to be missing and the recipient asks the sender to re-send it. The recipient also sends acknowledgements of what it has received so far back to the sender, so that the sender can remove safely transmitted data from its buffer. There’s a lot of complexity here. Compared to UDP, TCP is much less efficient in every way — the buffers take up RAM (though that may be dedicated RAM inside the network card), the more complex algorithm takes up CPU (that might also get off-loaded to the network card), the buffering adds latency, and all that signalling overhead takes up bandwidth.
However, all these inefficiencies are a small price to pay for the promise that the data received will be identical to the data sent!
4 — The Application Layer
The bottom three layers are in effect the infrastructure of the internet. The application layer is where the user-facing functionality starts. The vast majority of the protocols we interact with through the various apps we use are Layer 4 protocols. E.g. SMTP, IMAP & POP are the Layer 4 protocols we use to send and receive email. HTTP, HTTPS, and to a lesser extent FTP are the Layer 4 protocols we use to surf the net. The domain name system, or DNS, is the Layer 4 protocol we use to abstract away IP addresses. Online games sit in Layer 4, instant messaging sits in Layer 4, VoIP sits in Layer 4 — I could go on and on and on!
The majority of Layer 4 protocols sit on top of TCP, but a sizeable amount sit on top of UDP instead. Some applications make use of both — for example, when you log on to Skype you’re using a TCP connection. When you send instant messages via Skype you’re also almost certainly using TCP, and the under-the-hood signalling back-and-forth needed to initialise a call is also almost certainly done over TCP. All that happens before the app hands over to UDP for transmission of the actual sound and/or video streams.
Putting it All Together
From our point of view as a user trying to communicate across our home network or the internet, the process always starts at the application layer. We are sending an email, or we are viewing a web page, or we are downloading a file, or we are playing a game, or we are chatting with friends, or whatever.
As a worked example, let’s look at what happens when you use your web browser to try to visit http://www.so-4pt.net/~bart/ttt23/.
Before you can visit that URL, I have to have put some digital ducks in a row on my end.
Firstly, I have to have arranged for a DNS server to advertise to the world that my webserver has the IP address 46.22.130.125, and, I have to have the server with that IP address configured to act as a webserver.
On my server, a piece of software has to be running which speaks the HTTP protocol. We’ll call this piece of software the webserver process. This process has to have asked the OS to ‘listen’ on TCP port 80 (the standard HTTP port). That means that when any computer initiates a TCP connection to port 80 on my server, my server’s OS will hand that connection to my webserver process.
Assuming I have everything properly configured on my end, you open your favourite browser, and type http://www.so-4pt.net/~bart/ttt23/ into the address bar, and hit enter.
Your browser speaks HTTP, so it starts by formulating an HTTP request which will look something like:
GET /~bart/ttt23/ HTTP/1.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: en-gb
Host: www.so-4pt.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10) AppleWebKit/600.1.25 (KHTML, like Gecko) Version/8.0 Safari/600.1.25It then has to figure out, based on the URL you typed, what IP address it should strike up a TCP conversation with!
To do that it asks your OS to do a DNS lookup on its behalf.
For simplicity, let’s assume your OS had the answer in its cache, so it just gives the browser the answer that www.so-4pt.net maps to the IP address to 46.22.130.125.
We’ll be looking at the DNS protocol in much more detail in a future instalment!
Your browser then asks your OS to open a TCP connection to port 80 on 46.22.130.125 on its behalf.
Once your OS has done that, a TCP connection will exist between your browser and the webserver process on my server.
As far as either end of that connection is concerned, any data written into the connection on their end will pop out on the other end exactly as it was written.
This is a two-way connection, so the browser can send data to the webserver process, and the webserver process can send data back to the browser.
Your browser then sends the HTTP request it formulated to the webserver process on my server through the TCP connection your OS negotiated with my OS on your browser’s behalf. The webserver process receives the request, understands it because it speaks HTTP, and formulates a response in the form of an HTTP response that will look something like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
HTTP/1.1 200 OK
Date: Fri, 24 Oct 2014 22:40:07 GMT
Server: Apache/2.2.15 (CentOS)
Last-Modified: Fri, 24 Oct 2014 22:33:02 GMT
ETag: "1e40df-be-50632c385a380"
Accept-Ranges: bytes
Content-Length: 190
Connection: close
Content-Type: text/html; charset=UTF-8
<html>
<head>
<title>Hello Termninal Tamer!</title>
</head>
<body>
<h1>Hello Terminal Tamer!</h1>
<p>I hope you're enjoying the series thus far!</p>
<p><em>-- Bart</em></p>
</body>
</html>
You might notice that this response includes the HTML that makes up the content of the page as well as some metadata in the form of an HTTP response code and some HTTP headers.
Once my webserver process has formulated this response somehow (in this case by reading a file from the hard disk on my server and copying its contents into the data part of the HTTP response) it sends the response to your browser through the TCP connection.
Your browser then interprets the response and acts accordingly.
The 200 OK response code tells your browser the request was successful, and that the HTML it got back is not an error message or a redirect or anything like that, and is the HTML for the web page you requested.
It then interprets that HTML and draws the resulting web page on your screen.
The key point is that your browser and my webserver app communicated using HTTP, and they were oblivious to how the data got from one to the other. All either side knew about the network was that TCP was at their service. How TCP made it possible for the data to go from your browser to my webserver is irrelevant to them both. Notice how neither the HTTP request nor the HTTP response contained either an IP address or a MAC address. Those things happen below HTTP in the stack, so they are irrelevant to HTTP.
The takeaway from this example is that at a logical level, both sides talked HTTP to each other. Logically, communication is always directly across the stack.
Of course, TCP isn’t magic, and the TCP implementations inside the operating systems on your computer and my server sent a whole load of IP packets over and back between each other to make that TCP connection happen.
The two TCP implementations were totally oblivious to how the data got between the two computers though. All our TCP implementations knew is that they could pass a packet down to the IP implementations within our operating systems and that our IP implementations would send the packet on their behalf.
So far, nothing has actually left our computers yet! All of this chatter between the network layers has been in software. It’s not until the IP implementations in our OS finally hand those packets down to the Ethernet implementation within our OSes that anything physical actually happens!
To understand how the packets actually move from one physical computer to another, let’s focus on what happens to just one single IP packet and let’s chose a packet that’s being sent from your computer to my server. Let’s assume your computer is using WiFi to connect to the internet and that you have an ADSL router.
We join our packet in the IP implementation of your computer’s OS. The first thing your computer’s IP implementation does is look at the IP address on the packet and compare it to the IP address range of your network. My server is not in your network, so the IP implementation concludes that the packet is not local and so must be routed. Because your network is properly configured, your OS knows the IP and MAC addresses of your router’s internal network interface. Your IP implementation takes the IP packet and hands it to the Ethernet implementation with your OS along with the MAC address it should be sent to, that of your router. Your OS’s Ethernet implementation then wraps some metadata around the IP packet to turn it into an Ethernet packet. Finally, using the driver software for your WiFi card, your OS’s Ethernet implementation transmits the Ethernet packet which contains the IP packet we are following as modulated radio waves.
Your router’s wireless card receives the radio waves, interprets them and hands the Ethernet packet up to the Ethernet implementation in your router’s firmware. Your router’s Ethernet firmware unwraps the packet and hands it up to your router’s IP firmware. Your router’s IP firmware looks at the destination address on the IP packet and sees that it’s destined for the Internet, so it hands the packet down to your router’s ADSL firmware which wraps the packet again and converts it into electrical impulses which run through the phone network to your ISP’s router.
Your ISP’s router strips off the ADSL wrapper and passes the packet up to its IP firmware. The router’s IP firmware looks at the destination IP and then decides which of your ISP’s many interconnections to other routers is best suited to this packet. It then wraps the packet in the appropriate Layer 1 wrapper for the connection it chooses and send it on its way. The next router along again strips off the Layer 1 wrapper, looks at the IP address, decides which way to route it, wraps it as appropriate and sends it on to the next router. This continues for as long as it takes for the packet to arrive at the router in the data centre where my webserver lives. I’m in Ireland and so is my server, and for me, it still takes 8 ‘hops’ for the packet to get from my router to the router in the data centre hosting my server. For people farther away it will be even more.
|
You can use the terminal command Each line of output is a router your packet passed through. Some routers refuse to return the metadata traceroute requests, so they show up as a row of stars. The first router you see will be your home router (because I have a complex configuration, the first two routers in my trace are actually within my house), the last line will be my webserver, and the second-to-last line will be the router in the data centre that hosts my webserver. Subtracting those four IPs out, there are eight routers between my home router and the router in my data centre. Note that we’ll be looking at (If you’re not running as an admin you may find that traceroute is not in your path.) |
The router in my data centre will get the packet, unwrap whatever Layer 1 wrapper is around it, pass it up to its IP firmware, and look at the destination IP. Because my data centre and server are correctly configured, the router’s IP firmware will recognise that this packet is destined for a device on its local network, and know the MAC address of my server. It will pass the packet down to its Ethernet firmware one last time, asking it to send the packet to my server’s MAC address. The router’s Ethernet firmware will convert the packet to electrical signals, and send them down the UTP patch cable connected to my server.
My server’s network card will receive the Ethernet packet, unwrap it, and pass it up to my server’s OS’s IP implementation, which will remove the IP wrapper and pass the packet to TCP which will finally know what to do with the data inside the last wrapper, and eventually, those 1s and 0s will get to the webserver process as a part of the HTTP request.
The key point is how the layers interact. As we saw initially, logically the browser and the server talked HTTP to each other, but physically, the packet started in the application layer and moved down the layers to the link layer, then up and down between the link and internet layers many times as it moved across before finally being handed all the way up the layers back to the application layer when it arrived at my server. The diagram below illustrates this idea:

So, we followed the path of a single IP packet, how many IP packets were actually needed for this very simple HTTP transaction? The answer is 12 (see below). Only a subset of those 12 packets contained the actual data transmitted. The rest were IP packets sent by TCP in order to negotiate and un-negotiate the TCP connection, and to signal back and forth what packets had and had not been received safely.
|
You can see the packets needed to fetch my website by opening two terminal windows and issuing two commands. In the first window, we’ll use the This will print some metadata and then sit there and do nothing until matching packets are sent or received. In the other terminal window we will use the Note that every line starting with a Once we enter the above command in our second terminal window we should see some lines whiz by in our first terminal window. Click on this window and end the capture by hitting Ctrl+c. You should now have something that looks like: Above and below the captured packets you’ll see some header and footer information, but each line starting with a time code in the form of We’ll be looking at |
Final Thoughts
This is a confusing and dense topic. I’d be very surprised if it all sank in on the first reading. For now, if just the following key points have sunk in, you’re golden:
-
Networking is complicated!
-
Our computer networks use a stack of protocols known as TCP/IP
-
We think of the stack of protocols as being broken into four layers:
-
The Link Layer — lets computers that are on the same network send single packets of data to each other
-
The Internet Layer — lets computers on different networks send single packets of data to each other
-
The Transport Layer — lets computers send meaningful streams of data between each other
-
The Application Layer — where all the networked apps we use live
-
-
Logically, data travels across the layers — HTTP to HTTP, TCP to TCP, IP to IP, Ethernet to Ethernet, but physically, data travels up and down the stack, one layer to another, only moving from one device to another when it gets to the Link Layer at the very bottom of the stack.
In the following instalments, we’ll start to make our way up the stack, looking at each layer in more detail, and learning about terminal commands that interact with some of the protocols that make up each layer.
TTT Part 24 of n — Ethernet & ARP
In the previous instalment, we took a big-picture look at how TCP/IP networking works. As a quick reminder, the most important points were:
-
Networking is complicated!
-
Our computer networks use a stack of protocols known as TCP/IP
-
We think of the stack of protocols as being broken into four layers:
-
The Link Layer — lets computers that are on the same network send single packets of data to each other
-
The Internet Layer — lets computers on different networks send single packets of data to each other
-
The Transport Layer — lets computers send meaningful streams of data between each other
-
The Application Layer — where all the networked apps we use live
-
-
Logically, data travels across the layers — HTTP to HTTP, TCP to TCP, IP to IP, Ethernet to Ethernet, but physically, data travels up and down the stack, one layer to another, only moving from one device to another when it gets to the Link Layer at the very bottom of the stack.
In this instalment, we’ll take a quick look at the lowest of these four layers — the Link Layer. Specifically, we’ll look at MAC addresses, the difference between hubs, switches, and routers, and the ARP protocol.
Listen Along: Taming the Terminal Podcast Episode 24
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Before we Start …
Later in the instalment, we’re going to refer back to results of the following command and explain it, but it takes time for the packets to be collected, so before we start, please open a Terminal window and leave the following command running for at least 5 or 10 minutes:
sudo tcpdump -nneq arpEthernet — A Quick Overview
As we discussed in the previous instalment, the bottom of the four layers in the TCP/IP model is the Link Layer. Its function is to move a single packet of data from one device connected to a network to another device connected to the same network. Within our homes, we use Ethernet to provide our Layer 1 connectivity. We use two different implementations of Ethernet — we use Ethernet over copper wire (usually called Ethernet cables), and we use Ethernet over radio waves, commonly known as WiFi.
The Ethernet protocol addresses hosts on the network by their Media Access Control address, or MAC address. Every network card on your computer has a MAC address, regardless of whether it’s a wired or wireless Ethernet card. An Ethernet packet travelling through your network has a source and a destination MAC address.
Ethernet was designed to work on a shared medium — i.e., all network cards see all Ethernet packets travelling across the network. In normal use, a network card ignores all Ethernet packets that are not addressed to it, but a card can be instructed to pass all packets that reach it up to the OS, even those addressed to different MAC addresses. This is known as promiscuous mode.
The special MAC address ff:ff:ff:ff:ff:ff is used to broadcast an Ethernet packet to every device on the network.
All network cards consider packets addressed to this special MAC address to be addressed to them, and pass that packet up to the OS, even when not in promiscuous mode.
You can see the MAC addresses associated with your Mac/Linux/Unix computer with the command:
ifconfig -a(the -a stands for ‘all’ and is needed in many flavours of Linux to see network devices that are not currently active — OS X defaults to showing all devices, so the -a is optional on OS X.)
This command will list every network interface defined on your computer, both physical and virtual.
The output is broken into sections with the content of the section tabbed in.
Each section belongs to a different network interface, and the associated MAC address is labelled ether.
The naming conventions for the network interfaces vary massively between different OSes, but one thing is always the same, they are confusing as all heck, and figuring out which name matches which physical network interface is non-trivial.
Things are always confusing, but if you have a VPN installed they get even more confusing because VPNs are implemented using virtual network interfaces.
On the whole, the simplest way to figure out which MAC address matches which device is to use your OS’s control panel GUI.
On OS X that means the Network System Preference pane.
To see which MAC address matches which interface, select a network interface in the left sidebar, then click Advanced… and navigate to the Hardware tab:
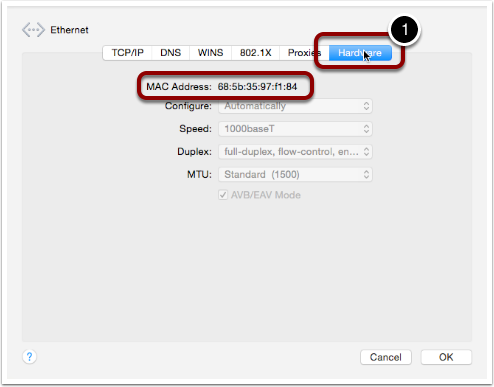
While the naming of network devices on Linux/Unix/OS X is confusing, there are some general rules that may help you figure out which device is which:
- lo0
-
This is the so-called loop-back address, it’s a virtual network interface that can be used to communicate internally within a computer using the TCP/IP stack.
lo0will usually have the IP address127.0.0.1and map to the hostnamelocalhost. (This is also the genesis of the two popular nerd T-shirts "There’s no place like 127.0.0.1" and "127.0.0.1 sweet 127.0.0.1") - gif0
-
This is an OS X-specific virtual network interface called the Software Network Interface. It’s used by the OS in some way but is of no relevance to users, so it can be ignored.
- stf0
-
This is another OS X-specific virtual network interface which is used by the OS to bridge IPV4 and IPV6 traffic — again, this is not relevant to users, so it can be ignored.
- fw0, fw1 …
-
OS X addresses firewire interfaces as
fw0and up because a FireWire connection between two computers can be used as a network connection between those computers. - en0, en1 …
-
OS X addresses Ethernet cards, be they wired or wireless, as
en0and up. - eth0, eth1 …
-
Most Linux and Unix variants address Ethernet cards, be they wired or wireless, as
eth0and up. - em1, em2 …
-
These names are used by the Consistent Network Device Naming convention which aims to map the labels on the back of computers to the device names within the OS. At the moment you’ll only see these on Dell servers running a RedHat variant (e.g. RHEL, CentOR and Fedora). I really hope this idea takes off and more manufacturers start implementing this!
- br0, br1 … or bridge0, bridge1 …
-
These virtual network devices are known as bridged networks and are often created by virtualisation software to allow VMs to access the network with their own dedicated MAC addresses.
- vmnetX
-
VMWare uses its own convention for allowing virtual machines to access the network. it created virtual network devices with names consisting of
vmnetfollowed by a number. - p2p0, p2p1 …
-
These virtual network devices are known as point to point networks and are used by things like VPNs to send traffic through some kind of tunnel to a server located somewhere else on the internet.
Realistically, if you’re running Linux or Unix the network interfaces you care about are probably the ones starting with eth, and for Mac users, it’s probably the ones starting with en.
To see all MAC addresses associated with your computer, regardless of which network card they belong to, you can use:
ifconfig -a | egrep '^\s*ether'Hubs, Switches & Routers — What’s the Difference?
Because Ethernet uses a shared medium, it’s susceptible to congestion — if two network cards try to transmit a packet at the same time, they interfere with each other and both messages become garbled. This is known as a collision. When an Ethernet card detects a collision, it stops transmitting and waits a random amount of milliseconds before trying again. This simple approach has been proven to be very effective, but it’s Achilles heel is that it’s very prone to congestion. When an Ethernet network gets busy the ratio of successful transitions to collisions can collapse to the point where almost no packets actually get through.
With WiFi this shortcoming is unavoidable — a radio frequency is a broadcast medium, so collisions are always going to be a problem, and this is why it’s very important to choose a WiFi channel that’s not also being used by too many of your neighbours!
A copper cable is not the same as a radio frequency though! In order to create a copper-based Ethernet network, we need some kind of box to connect all the cables coming from all our devices together.
Originally these boxes had no intelligence at all — they simply created an electrical connection between all the cables plugged into them — creating a broadcast medium very much like a radio frequency. This kind of simplistic device is known as an Ethernet hub. An Ethernet network held together by one or more hubs is prone to congestion.
A way to alleviate this problem is to add some intelligence into the box that connects the Ethernet cables together. Rather than blindly retransmitting every packet, the device can interpret the Ethernet packet, read the destination MAC address, and then only repeat it down the cable connected to the destination MAC address. Intelligent devices like this are called Ethernet switches. In order to function, an Ethernet switch maintains a lookup table of all MAC addresses reachable via each cable plugged into it. Connections to hubs/switches are often referred to as legs or ports. These lookup tables take into account the fact that you can connect switches together, so they allow the mapping of multiple MAC addresses to each leg/port. If you have an eight-port switch with seven devices connected to it, and you then connect that switch to another switch, that second switch sees seven MAC addresses at the end of one of its legs.
Because switches intelligently repeat Ethernet packets, they are much more efficient than hubs, but congestion can still become a problem because broadcast packets have to be repeated out of every port/leg.
10 years ago you had to be careful when buying an Ethernet ‘switch’ to be sure you weren’t buying a hub by mistake. Thankfully, switches are ubiquitous today, and it’s almost impossible to find a hub.
There is a third kind of network device that we should also mention in this conversation — the router. A router is a device that has a Layer 1 connection to two or more different networks. It uses the Layer 2 IP protocol to intelligently move packets between those networks.
Our home routers cause a lot of confusion because they are actually hybrid devices happen to contain a router. The best way to think of a home router is as a box containing two or three component devices — a router to pass packets between your home network and the internet, an Ethernet switch that forms the heart of your home network, and, optionally, a wireless access point, which is the WiFi-equivalent of an Ethernet hub. Importantly, if it’s present, the wireless access point is connected to the Ethernet switch, ensuring that a single Ethernet network exists on both the copper and the airwaves. This means that an Ethernet packet can be sent from a wired network card to a wireless network card in a single Layer 1 hop — i.e. Layer 2 is not needed to get a single packet from a phone on your WiFi to a desktop computer on your wired Ethernet. Confusingly, while this single packet will pass through a device you call a router, it will not be routed — it will go nowhere near the router inside your home router, it will stay on the switch and the wireless access point inside your home router. The diagram below illustrates the typical setup:
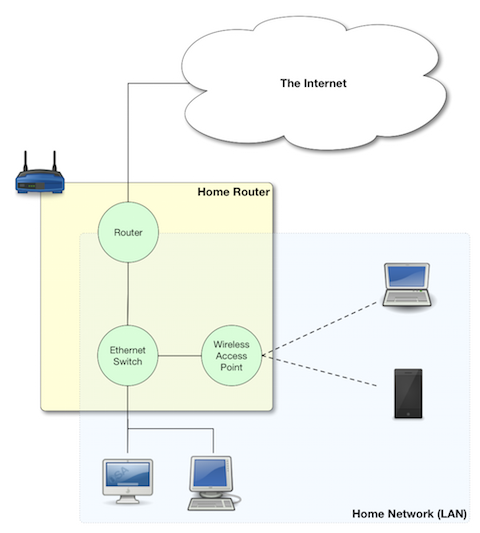
The Address Resolution Protocol (ARP)
The protocol that sits on top of Ethernet is the IP Protocol. The IP protocol moves a packet from one IP address to another, and it does so by repeatedly dropping the packet down to the link layer below to move the packet one hop at a time from a directly-connected device to another directly-connected device until it arrives at its destination. As a quick reminder, see the diagram below from the previous instalment:
Within our LAN, the Layer 1 protocol IP used to move a packet from one device on our LAN to another device on our LAN is Ethernet. Ethernet can only move a packet from one MAC address to another, and IP moves packets from one IP address to another, so how does the IP protocol figure out what MAC address matches to what IP address so it knows where to ask Ethernet to send the packet?
The Address Resolution Protocol, or ARP, is an Ethernet protocol that maps IP addresses to MAC addresses.
It’s a supremely simplistic protocol.
Whenever a computer needs to figure out what MAC address matches a given IP address, it sends an ARP request to the broadcast MAC address (ff:ff:ff:ff:ff:ff), and whatever computer has the requested IP answers back to the MAC address asking the question with an ARP reply saying that their MAC address matches the requested IP.
The command you’ve had running in the background since the start of this instalment has been listening for ARP packets and printing every one your computer sees. You should see output something like:
bart-iMac2013:~ bart$ sudo tcpdump -nneq arp
Password:
tcpdump: data link type PKTAP
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on pktap, link-type PKTAP (Packet Tap), capture size 65535 bytes
15:06:04.868430 40:6c:8f:4d:0b:9b > ff:ff:ff:ff:ff:ff, ARP, length 60: Request who-has 192.168.10.206 tell 192.168.10.100, length 46
15:06:05.706152 40:6c:8f:4d:0b:9b > ff:ff:ff:ff:ff:ff, ARP, length 60: Request who-has 192.168.10.206 tell 192.168.10.100, length 46
15:06:06.868324 40:6c:8f:4d:0b:9b > ff:ff:ff:ff:ff:ff, ARP, length 60: Request who-has 192.168.10.206 tell 192.168.10.100, length 46
15:06:10.623603 40:6c:8f:4d:0b:9b > ff:ff:ff:ff:ff:ff, ARP, length 60: Request who-has 192.168.10.206 tell 192.168.10.100, length 46
15:06:11.705482 40:6c:8f:4d:0b:9b > ff:ff:ff:ff:ff:ff, ARP, length 60: Request who-has 192.168.10.206 tell 192.168.10.100, length 46
15:06:12.868490 40:6c:8f:4d:0b:9b > ff:ff:ff:ff:ff:ff, ARP, length 60: Request who-has 192.168.10.206 tell 192.168.10.100, length 46
15:09:11.698813 40:6c:8f:4d:0b:9b > ff:ff:ff:ff:ff:ff, ARP, length 60: Request who-has 192.168.10.1 tell 192.168.10.100, length 46
15:10:11.696476 40:6c:8f:4d:0b:9b > ff:ff:ff:ff:ff:ff, ARP, length 60: Request who-has 192.168.10.1 tell 192.168.10.100, length 46
15:10:38.977585 dc:86:d8:09:97:09 > ff:ff:ff:ff:ff:ff, ARP, length 60: Request who-has 192.168.10.1 tell 192.168.10.215, length 46
15:10:40.588396 dc:86:d8:09:97:09 > ff:ff:ff:ff:ff:ff, ARP, length 60: Request who-has 192.168.10.1 tell 192.168.10.215, length 46
15:11:07.962791 68:5b:35:97:f1:84 > ff:ff:ff:ff:ff:ff, ARP, length 42: Request who-has 192.168.10.5 tell 192.168.10.42, length 28
15:11:07.963048 50:46:5d:74:ce:66 > 68:5b:35:97:f1:84, ARP, length 60: Reply 192.168.10.5 is-at 50:46:5d:74:ce:66, length 46
15:11:40.716850 40:6c:8f:4d:0b:9b > ff:ff:ff:ff:ff:ff, ARP, length 60: Request who-has 192.168.10.42 tell 192.168.10.100, length 46
15:11:40.716859 68:5b:35:97:f1:84 > 40:6c:8f:4d:0b:9b, ARP, length 42: Reply 192.168.10.42 is-at 68:5b:35:97:f1:84, length 28
15:12:04.557253 68:5b:35:97:f1:84 > 00:13:3b:0e:3f:30, ARP, length 42: Request who-has 192.168.10.1 (00:13:3b:0e:3f:30) tell 192.168.10.42, length 28
15:12:04.557500 00:13:3b:0e:3f:30 > 68:5b:35:97:f1:84, ARP, length 60: Reply 192.168.10.1 is-at 00:13:3b:0e:3f:30, length 46
What you can see is a whole bunch of ARP requests asking the network who has various IP addresses, and, a few replies. If your entire home network uses WiFi you’ll probably see an approximately even number of requests and responses, but, if your network includes devices connected via wired Ethernet you should notice a distinct asymmetry between requests and responses, especially if your computer is connected to the network via Ethernet. This is not because requests are going un-answered, but rather because there is a switch in the mix, and that switch is only passing on Ethernet packets that are relevant to you. Requests are broadcast, so Ethernet switches send those packets to everyone, but responses are directed at a single MAC address, so those are only passed out the relevant port on the switch. In effect, what you are seeing is the efficiency of an Ethernet switch in action!
While we’re on the subject of efficiency, computers don’t send an ARP request each and every time they want to transmit an IP packet, ARP responses are cached by the OS, so new ARP requests are only sent when a mapping is not found in the cache.
You can see the MAC to IP mappings currently cached by your OS with the command arp -an.
You’ll get output something like:
bart-iMac2013:~ bart$ arp -an
? (192.168.10.1) at 0:13:3b:e:3f:30 on en0 ifscope [Ethernet]
? (192.168.10.2) at 90:84:d:d1:f0:be on en0 ifscope [Ethernet]
? (192.168.10.5) at 50:46:5d:74:ce:66 on en0 ifscope [Ethernet]
? (192.168.10.42) at 68:5b:35:97:f1:84 on en0 ifscope permanent [Ethernet]
? (192.168.10.100) at 40:6c:8f:4d:b:9b on en0 ifscope [Ethernet]
? (192.168.10.255) at ff:ff:ff:ff:ff:ff on en0 ifscope [Ethernet]
bart-iMac2013:~ bart$The more devices on your LAN you are interacting with, the more mappings you’ll see.
ARP Security (or the Utter Lack Thereof)
Something you may have noticed about ARP is that it assumes all computers are truthful, that is to say, that no computer will falsely assert their MAC address maps to any given IP. This assumption is why ALL untrusted Ethernet networks are dangerous — be they wired or wireless. This is why the Ethernet port in a hotel room is just as dangerous as public WiFi. To intercept other people’s network traffic, an attacker simply has to send out false ARP replies and erroneously advertise their MAC address as matching their victim’s IP address. The attacker can then read the packets before passing them on to the correct MAC address. Users will not lose connectivity because the packets all get where they are supposed to eventually go, but the attacker can read and alter every packet. This technique is known as ARP Spoofing or ARP Poison Routing (APR) and is staggeringly easy to execute.
ARP is just the first example we have met of the Internet’s total lack of built-in security. It illustrates the point that the designers of the IP stack simply never imagined there would be malicious actors on their networks. If it didn’t have such detrimental effects on all our security, the naive innocence of those early pioneers would be very endearing!
Conclusions
This is the last we’ll see of Layer 1 in this series. In the next instalment, we’ll be moving up the stack to Layer 2 and the IP protocol — the real work-horse of the internet. In particular, we’ll be tackling one of the single most confusing, and most critical, networking concepts — that of the IP subnet. It’s impossible to effectively design or troubleshoot home networks without understanding subnets, and yet they are a mystery to so many.
TTT Part 25 of n — IP Subnets
In part 23 of n, we took a big-picture look at how TCP/IP networking works. As a quick reminder, the most important points were:
-
Our computer networks use a stack of protocols known as TCP/IP
-
We think of the stack of protocols as being broken into four layers:
-
The Link Layer — lets computers that are on the same network send single packets of data to each other
-
The Internet Layer — lets computers on different networks send single packets of data to each other
-
The Transport Layer — lets computers send meaningful streams of data between each other
-
The Application Layer — where all the networked apps we use live
-
-
Logically, data travels across the layers — HTTP to HTTP, TCP to TCP, IP to IP, Ethernet to Ethernet, but physically, data travels up and down the stack, one layer to another, only moving from one device to another when it gets to the Link Layer at the very bottom of the stack.
In the previous instalment, we focused on the lowest of the four layers, the link layer, and looked at how Ethernet and ARP work. In this instalment, we’ll move one layer up the stack and take a closer look at the IP protocol. A concept absolutely central to IP’s operation is that of related groups of IP addresses known as IP Subnetworks or just subnets. This is the concept we’ll be focusing on in this instalment.
Listen Along: Taming the Terminal Podcast Episodes 25a & 25b
| Episode 25a | Episode 25b |
|---|---|
Scan the QR code to listen on a different device |
|

|

|
You can also play/download the MP3 in your browser (a) |
You can also play/download the MP3 in your browser (b) |
IP Addresses
At the IP level, packets are sent from one IP address to another.
Every computer connected to an IP network has one or more IP addresses.
For the purpose of this series we will be ignoring IPv6, so IP addresses are of the form n1.n2.n3.n4, where n1 to n4 are numbers between 0 and 255, E.g.
192.168.0.1.
Unlike MAC addresses, IP addresses are not hard-coded into our network interfaces. Instead, they have to be configured within the operating system. Historically this was always a manual process, but today it’s usually automated using the Dynamic Host Configuration Protocol, or DHCP. We’ll be looking at how DHCP works in detail later in the series. Also, a single network interface can have many IP addresses assigned to it, and a single computer can have many network interfaces, so it’s not uncommon for a computer to have multiple IP addresses.
The vast address-space of possible IP addresses is managed by the Internet Corporation for Assigned Names and Numbers (ICANN). ICANN assign blocks of IP addresses to organisations. There are also three special blocks of IP addresses that ICANN have reserved for use on private networks, and it’s these IPs that we use within our homes. These private IP addresses can never appear on the public internet, they must always be either completely disconnected from the internet, or isolated from the internet by a NAT router. We’ll look at NAT in more detail later, but for now, all we need to know is that just about every home router is a NAT router.
The private IP address ranges:
-
10.0.0.0to10.255.255.255(in common use) -
172.16.0.0to172.31.255.255(rarely seen) -
192.168.0.0to192.168.255.255(in very common use)
Additionally, there are two other special ranges of IPs you may encounter:
-
127.0.0.0to127.255.255.255— the range reserved for so-called loop-back traffic within a computer -
169.254.0.0to169.254.255.255— the range reserved for self-assigned IP addresses — if you see one of these on your computer, it almost always means something has gone wrong!
Routing Packets
Unlike Ethernet, the IP protocol can send packets across different networks. The act of moving a packet through different networks from source to destination is known as routing. The heavy-lifting in routing, figuring out a route through the maze of interconnected networks that make up the internet, is done by routers, and is beyond the scope of this series. However, each and every device that speaks IP needs to make some simple routing decisions. Fundamentally our computers have to answer one simple routing question "is the destination IP address for this packet on my local network, or is it on a different network?".
If your computer determines that the destination IP address is on the local network, then it looks up the MAC address for the destination IP using ARP (as described in the previous instalment) and sends the packet directly to its destination using Ethernet.
On the other hand, if your computer determines that the destination IP is not on your local network, then it must send the packet to your router for processing. To do this your computer must know the IP address of your router, and, it must find your router’s MAC address using ARP. Once your computer has that information it sends the packet to your router using Ethernet. Your router then sends the packet on to your ISP’s router which will send it on its way across the internet.
At this stage, we know that for your computer to work on an IP network it must have an IP address, and it must know the IP address of the router it should use to send remote packets on their way. But how does it know whether or not a packet is destined for the local network? The key to answering that question is IP subnets.
IP Subnets
When we say that a device must figure out whether or not a packet’s destination IP is local or not, what we really mean is that it must determine whether or not the destination IP is in the same subnet.
A subnet is a collection of similar IP addresses that share a single Ethernet network. In other words, every device on a subnet must be able to send Ethernet packets to every other device on the same subnet. There is not a one-to-one mapping between Ethernet networks and IP subnets though, so while a subnet can’t be spread over multiple Ethernet networks, one Ethernet network can host multiple IP subnets. Having said that, in reality, the mapping usually is one-to-one, especially within our homes.
Note that when people talk about a Local Area Network or LAN, they are often referring to an IP subnet. Do bear in mind though that many people use those terms very loosely, and often inaccurately.
In order to understand how a subnet is defined, we need a deeper understanding of IP addresses.
We are accustomed to seeing them as so-called dotted quads (like 192.168.0.1), but those dotted quads are just a human-friendly way of representing what an IP address really is — a 32-bit binary number.
The IP address 192.168.0.3 is really 11000000101010000000000000000011.
We create subnets of different sizes by choosing a dividing line somewhere inside this 32-bit block, and saying that everything before our dividing line will be kept constant for this subnet. In other words, all IP addresses on a given subnet share the same prefix when expressed in binary form. This means that to define a subnet we need two pieces of information — the first address in the subnet, and the location of the dividing line, or, to use the correct terms, we need a network address (or net address), and a netmask. The size of the subnet (the number of IP addresses it contains) is determined by where you choose to place the divider. The closer to the front of the 32 bits, the bigger the subnet, the closer to the back, the smaller.
Netmasks are represented using 32-bit binary numbers.
All the bits before the chosen divide are set to 1, and all the bits after the divide are set to 0.
When written in binary, a netmask MUST be 32 bits long and MUST consist of a series of 1s
followed by a series of 0s.
The chosen dividing line represented by the netmask is the point where the 1s change to 0s.
Because netmasks are 32-bit numbers, just like IP addresses, we can represent them in the same way, as dotted quads. (There are other ways to represent them too though — as we’ll see later)
Basic Routing Math
Remember, the problem to be solved is that our computers need to be able to determine if a given IP address is local or remote. Local IP packets should be sent directly to the destination, while remote packets should be sent to the router.
The key fact here is that you can use a binary AND operator to calculate your net address based on just your IP address and netmask.
In other words, when you take your own IP address and AND it with your netmask you get your net address.
You then take the destination IP address and AND it with your netmask, and compare the result to your net address.
If the result is the same as your net address, the IP is local, if not, it’s remote and needs to be routed.
Firstly, let’s define what we mean by an AND operation in a binary context:
| A | B | A AND B |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
This probably all sounds very abstract, so let’s work through an example. We are computer A, and the two computers we want to communicate with are Computers B and C. Subnet masks are not published, they are an internal OS setting, so we do not know the recipients’ netmasks, only our own. So, this is what we know:
-
Computer A: IP =
192.168.0.3, netmask =255.255.255.248 -
Computer B: IP =
192.168.0.5 -
Computer C: IP =
192.168.0.9
First, let’s do some conversions:
-
192.168.0.3=11000000101010000000000000000011 -
192.168.0.5=11000000101010000000000000000101 -
192.168.0.9=11000000101010000000000000001001 -
255.255.255.248=11111111111111111111111111111000
Using the simple truth table for AND shown above, we can AND each IP address with our netmask to get the results below.
Note that you need to apply the AND rule 32 times for each conversation, once for each bit.
This is known in computer science as a bitwise AND operation.
-
IP A AND netmask =
11000000101010000000000000000000(our net address) -
IP B AND netmask =
11000000101010000000000000000000 -
IP C AND netmask =
11000000101010000000000000001000
What we see here is that A and B are in the same subnet, but C is not.
You can play around with this, and see all the binary calculations using my free IP Subnet calculator at www.subnetcalc.it. You can use this link to load the IP and Netmask into the interface automatically and save yourself some copying and pasting. You can then paste IP B and IP C into the IP Test text box near the bottom of the page to see why one is local and the other is not.
If we write out all the IP addresses between 192.168.0.0 and 192.168.0.9, as well as our netmask (255.255.255.248) the pattern will hopefully become clear.
For extra clarity, I’ve also included the imaginary separator represented by the netmask by inserting a | character into the binary strings.
| IP in Binary (With Imaginary Separator) | IP quads |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The Structure of a Subnet
A subnet is, by definition, defined by its netmask and the first IP address within the subnet, known as the network address.
A netmask of 255.255.255.248 only allows 3 bits of freedom within a subnet, so that means it defines 8 IP addresses (see above), but only SIX can actually be used.
The first and last IP addresses of all subnets are reserved, and cannot be used by devices.
The first IP address is the network address, or net address, for the subnet, while the last is the so-called broadcast address.
The table below shows the subnet 192.168.0.0/255.255.255.248:
| IP in Binary | IP quads | Comment |
|---|---|---|
|
|
Network Address |
|
|
Usable IP Address |
|
|
Usable IP Address |
|
|
Usable IP Address |
|
|
Usable IP Address |
|
|
Usable IP Address |
|
|
Usable IP Address |
|
|
Broadcast Address |
|
|
Netmask |
Broadcast Addresses
Using your subnet’s broadcast address, you can send a single IP packet to every device on your local subnet. Like the network address, the broadcast address can be calculated given only a computer’s IP address and netmask. In this case, the maths is a little more complicated, but not much.
To calculate broadcast addresses we need to learn about two more binary operators — binary inversion, and the OR operator.
Inversion is as simple as it sounds, all 1s are turned to 0s, and all 0s to 1s.
The OR operator is defined by the truth table below:
| A | B | A OR B |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
To calculate the broadcast address, first, invert the netmask, then OR that inverted netmask with your IP address.
Representing Netmasks
We’ve already seen that you can represent a netmask as a dotted quad, just like an IP address, but unfortunately, this is not the only notation in common use. The list below shows all the commonly used representations:
-
Netmasks are 32-bit binary numbers just like IP addresses, so they can be represented using dotted quads just like IP addresses. This is the most intuitive representation of a netmask, and for our example network, it would be
255.255.255.248. This is the most commonly used representation and is used in the System Preferences app on OS X and the Windows Control Panel. -
Netmasks can also be written in hexadecimal. Every group of four bits gets converted to a symbol between
0andfin the following way:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
0000 = 0 0001 = 1 0010 = 2 0011 = 3 0100 = 4 0101 = 5 0110 = 6 0111 = 7 1000 = 8 1001 = 9 1010 = a 1011 = b 1100 = c 1101 = d 1110 = e 1111 = f
In computer science hexadecimal numbers are signified by prefixing them with
0x, so our example netmask can be written as0xfffffff8. This is by far the least human-friendly representation, but it is the one BSD Unix, and OS X, use in the output from theifconfigcommand. -
A netmask can also be represented in bits. That is to say, the number of the 32 possible bits that are set to 1. So, for our example network, it has a netmask of 29 bits.
Representing Subnets
The correct way to write down a subnet definition is as follows: IP_ADDRESS/NETMASK, where any of the above representations for netmasks are permissible
This means that our example subnet above can be written in all the following ways:
192.168.0.0/255.255.255.248
192.168.0.0/29
192.168.0.0/0xfffffff8Real-World Simplifications
While it is entirely permissible to have a subnet of any size between 0 and 32 bits, not all sizes are equally common. There are three very common sizes, and, not coincidentally, they have the advantage that you can visually interpret them when written as dotted quads, so no need to revert to binary! These three common sizes are:
| Netmask dotted quad | bits | Hex | #IP addresses | Common Name |
|---|---|---|---|---|
|
|
|
16,777,214 |
Class A network |
|
|
|
65,534 |
Class B network |
|
|
|
254 |
Class C network |
If our computer has a class C netmask, then our network address is the first three quads of our IP with the last quad set to 0. Also, all IPs that start with the same three quads as our IP are local.
Similarly, if our computer has a class B netmask, then our network address is the first two quads of our IP with the last two quads set to 0. Also, all IPs that start with the same two quads as our IP are local.
Finally, if our computer has a class A netmask, then our network address is the first quad of our IP with the last three quads set to 0. Also, all IPs that start with the same first quad as our IP are local.
Most home routers create class C networks by default, so understanding class C networks is enough to allow most home users to get by.
IP Network Configuration
In order for a device to properly use an IP network it needs to have three settings correctly configured:
-
IP Address
-
Netmask
-
Default gateway AKA default route (the IP address of the router). The router’s IP MUST fall within the subnet defined by the IP address combined with the netmask
You can see these three settings in the Networks system preference pane in OS X:
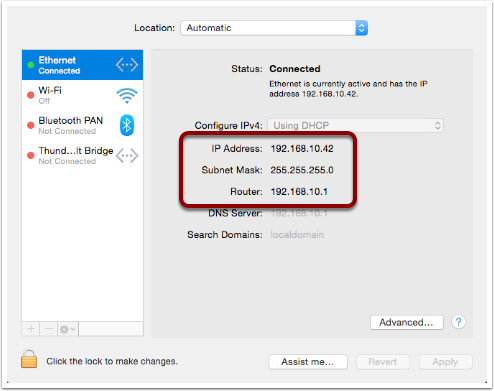
Or, you can access them via the command line with the following two commands:
ifconfig -a
netstat -rnBoth of these commands are VERY talkative, and while all the needed info is in there somewhere, we can use the power of egrep to filter those outputs down to just what we want:
ifconfig -a | egrep '\binet\b' | egrep -v '127[.]'
netstat -rn | egrep '^default'With these filtered versions of the commands, we can clearly see the three pieces of information we are looking for. Below is my output, with the desired information highlighted:
bart-iMac2013:~ bart$ ifconfig -a | egrep '\binet\b' | egrep -v '127[.]'
inet 192.168.10.42 netmask 0xffffff00 broadcast 192.168.10.255
bart-iMac2013:~ bart$ netstat -rn | egrep '^default'
default 192.168.10.1 UGSc 55 0 en0
bart-iMac2013:~ bart$If you copy and paste the IP and netmask values from the above commands into the calculator at www.subnetcalc.it you can see the structure of your subnet.
Routable -v- Un-Routable Protocols — A Home Networking Pitfall
The application layer protocols we use to actually do things on our networks or the internet use protocols which sit on top of IP (usually TCP or UDP). Because IP can send packets between subnets, you might assume that all Application layer protocols that use IP under the hood would also be able to work across different subnets, but you’d be mistaken. Many, even most, application layer protocols can indeed cross routers to move between subnets, but a subset of them can’t. Protocols that rely on IP broadcast packets are confined to the reach of those packets, i.e., to the local subnet. Because these protocols can’t cross routers, they are known as unroutable protocols.
The unroutable protocols you are likely to encounter on your home network are mostly designed around zero-config sharing of some sort. The idea is that computers that share a subnet can easily share data or some other resource without the user needing to do much, if any, configuration. Probably the most common such protocol is mDNS, better known as Bonjour. Apple is very fond of unroutable protocols for things like AirVideo, iTunes sharing and printer sharing. The fact that these protocols are confined within the local subnet is actually a security feature. Something which can’t possibly be accessed remotely needs a lot less security than something which could be accessed by anyone on the internet! If anyone anywhere on the planet could send their screen to your Apple TV you’d definitely need to set a password on it, and a long one at that, but because AirPlay is unroutable, you don’t need to bother, making the experience much more pleasant!
A very common problem is that people accidentally break their network into multiple subnets, and then find that sharing services have become mysteriously unreliable.
Imagine you have half of your devices on one subnet, and half on another — those sharing a subnet with an Apple TV can share their screens no problem, but the devices on the other subnet can’t. You think they are all on the same network because they are all in your home, and all eventually connect back to your internet router, so you have no idea why something that should just work is just refusing to work!
It’s actually very easy to accidentally break up your network. Imagine you start with the basic network setup we described last week: you have one home router which connects you to the internet, and provides you with an Ethernet switch and a wireless access point:
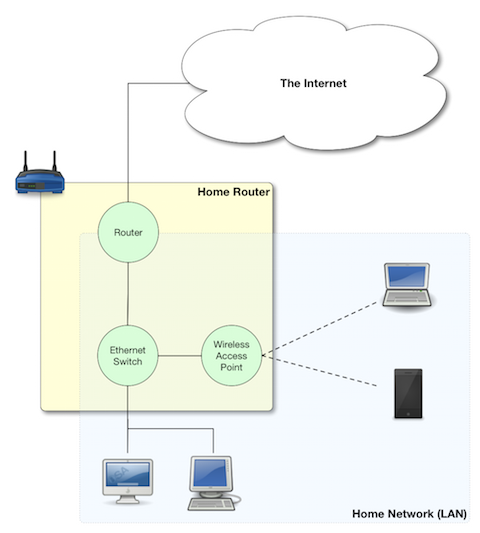
This is working quite well, but you have terrible WiFi reception in the back bedroom, so you buy another wireless router, and plug it in. That device, like your home router, is probably three devices in one, a router, an Ethernet switch, and a wireless access point, that means that depending on your configuration, you can end up with one big IP subnet in the house, or, with two separate IP subnets. The diagrams below show two possible configurations with two home routers — one with a single IP Subnet, the other with two separate subnets.
Good — A Single Subnet
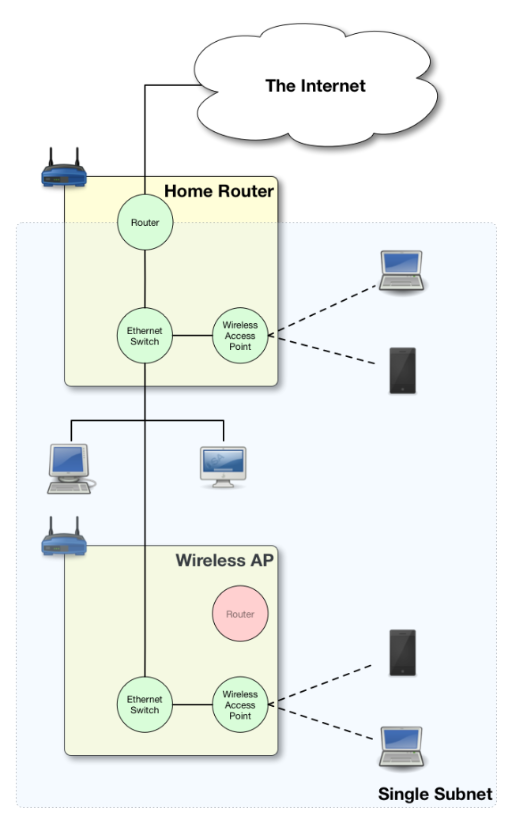
Bad — Two Subnets
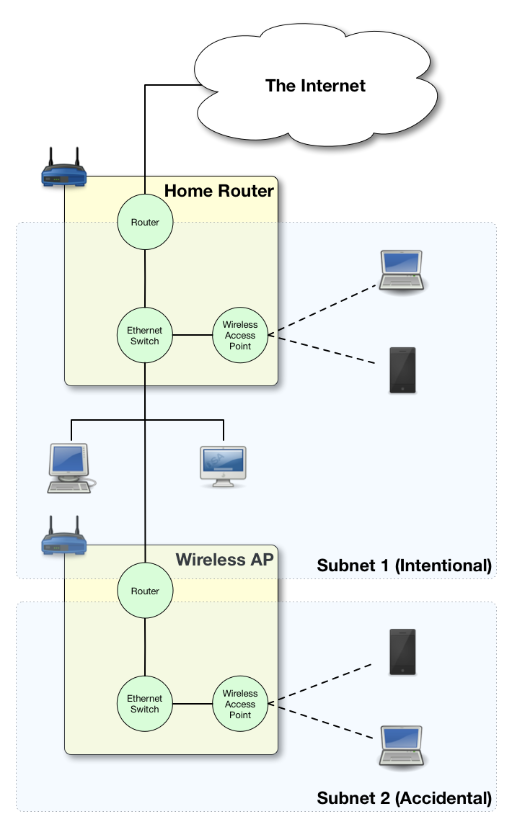
Unless you intentionally want to isolate off some users, you probably want a single subnet, and if you accidentally ended up with more you’re probably experiencing all sorts of sharing frustrations. Why can I send my screen to the Apple TV, but my husband can’t? Why can my daughter print, but I can’t? Why can the Apple TV not see my shared iTunes library while my son’s computer can? When you start experiencing strange symptoms like this, the first thing to check is that you haven’t accidentally divided your network into multiple subnets.
Are All the Devices On Your Home on the Same Network?
When the IP stack is trying to decide how to route a packet it only knows its own IP address and netmask, and the destination IP, but when you are trying to figure out if two devices on your home network share a subnet, you have access to more information because you can discover each computer’s IP AND netmask (by reading them from the UI to terminal).
If your intention was to create a single home network, and you want to verify that any two devices really are on the same subnet, you can use the following simple algorithm:
-
Are the netmasks on the two computers the same? Yes — continue to step 2, NO — the two computers are NOT on the same subnet
-
Figure out the network addresses for both IPs. If they are the same, the computers are on the same subnet.
The following flow chart will walk you through the process:
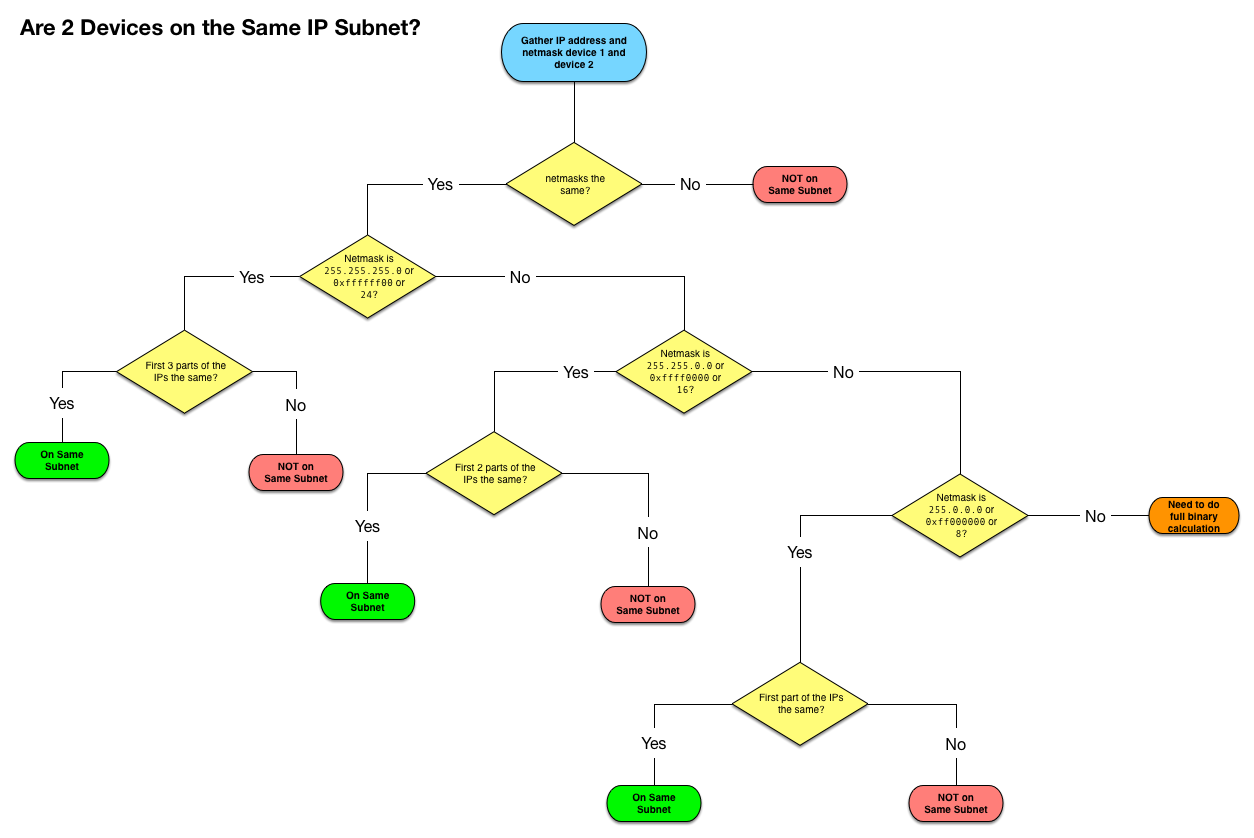
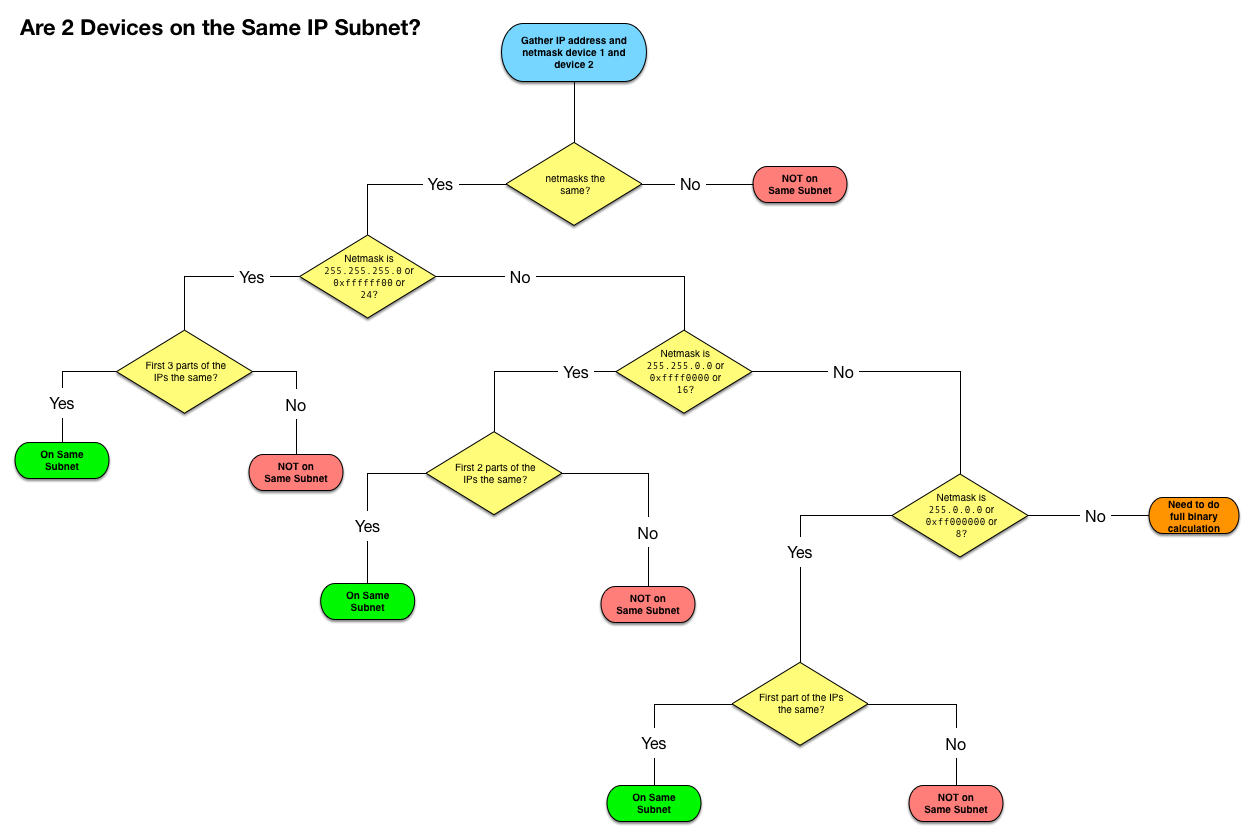{kind=link}
Since most of our home networks use Class C netmasks, you’ll probably only ever need a small section of the diagram.
With a little practice, determining whether or not two devices are on the same subnet will become second nature. Below is a quick little self-test to get some practice:
-
192.168.0.1/255.255.255.0&192.168.0.1/255.255.0.0NOT same subnet — this is, in fact, a misconfiguration, one of the two computers needs their netmask changed
-
192.168.0.23/255.255.255.0&192.168.1.24/255.255.255.0NOT same subnet — the network addresses are different (
192.168.0.0and192.168.1.0) -
192.168.5.214/255.255.0.0&196.168.45.169/255.255.0.0SAME subnet — both are in the class B network with network address
192.168.0.0 -
10.0.0.5/24&10.0.0.124/24SAME subnet — both are in the class C network with network address
10.0.0.0 -
10.10.10.54/0xffffff00&10.10.11.54/24NOT same subnet — both are in class C networks, but one has a network address of
10.10.10.0while the other has the network address10.10.11.0 -
10.245.6.11/16&10.245.7.11/0xffff0000SAME subnet — both are in the class B network with network address
10.245.0.0
Conclusions
For a computer to work correctly on an IP network, it must have the following three things properly configured:
-
An IP Address
-
A Netmask
-
A Default Router
When troubleshooting home network sharing problems, one of the first things to do is verify that all devices are on the same subnet. Usually, when they’re not, that was unintentional, and the cause of the problems. Learning to read and understand IP addresses and netmasks is a vital skill for just about any network troubleshooting.
In this instalment, we concentrated on understanding the network settings we see in our computers. In the next instalment we’ll take a look at the protocol that is almost certainly passing those settings to your computers, DHCP.
TTT Part 26 of n — DHCP
In part 23 of n, we took a big-picture look at how TCP/IP networking works. As a quick reminder, the most important points were:
-
Our computer networks use a stack of protocols known as TCP/IP
-
We think of the stack of protocols as being broken into four layers:
-
The Link Layer — lets computers that are on the same network send single packets of data to each other
-
The Internet Layer — lets computers on different networks send single packets of data to each other
-
The Transport Layer — lets computers send meaningful streams of data between each other
-
The Application Layer — where all the networked apps we use live
-
-
Logically, data travels across the layers — HTTP to HTTP, TCP to TCP, IP to IP, Ethernet to Ethernet, but physically, data travels up and down the stack, one layer to another, only moving from one device to another when it gets to the Link Layer at the very bottom of the stack.
In the previous instalment, we looked at how IP subnet works. The key takeaway was that a computer needs a minimum of three settings correctly configured to be able to participate in an IP network: an IP address, a subnet mask, and a default gateway (the IP address of the router providing access outside the subnet). We also looked at how to read those three settings from your Mac using the GUI (Graphical User Interface) and the Terminal. Finally, we noted that historically, those settings had to be manually configured, but that today, almost all computers acquire those settings automatically. In this instalment, we’ll look at the protocol that makes that possible, the Dynamic Host Configuration Protocol, or DHCP.
Listen Along: Taming the Terminal Podcast Episode 26
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
The Problem to be Solved
If we rewind the clock to the days before laptops (let alone tablets and smartphones), the only computers connecting to networks were stationary devices. A network admin would connect the computer to the network, configure the three vital settings, and that would be the computer set up on the network, probably for its entire life.
Even at this early stage, there was some friction with this process. Manually configured network settings make seamless network changes impossible. Once the network is changed in some way, a network engineer has to revisit each computer one by one to update the settings.
However, it was the invention of the portable networked computer that turned this friction into a major problem. We all expect to be able to get network access where ever we go with our laptops, iPhones, and iPads. If we were doing things the old way and manually configuring our devices, we would need to know the IP address, netmask, and gateway for every network we used, and we would have to manually change the settings each time we moved from one network to another. Obviously, manually configured network settings are just not practical in the modern world!
The solution was to develop a protocol that would allow computers to automatically discover their own settings.
The first attempt at developing such a protocol was RARP (the Reverse ARP Protocol), which was published in 1984. RARP was a link-layer protocol (Layer 1 in the TCP/IP model), which meant that the RARP server had to be on the same Ethernet network as the clients. This also meant that organisations with multiple subnets needed multiple RARP servers. RARP was a short-lived experiment, being superseded with the release of BOOTP (the Bootstrap Protocol) in 1985. BOOTP was a significant step forward, introducing the concept of a relay agent that could forward BOOTP requests from multiple subnets to a single centralised BOOTP server. BOOTP was still very much a product of its time though — it was designed around the concept of allocating IPs to computers permanently. BOOTP has no way to reclaim addresses, so it’s useless in environments were lots of computers come and go all the time.
In 1993 BOOTP was extended to create the protocol we use today, DHCP (the Dynamic Host Configuration Protocol). DHCP is built around the concept of computers temporarily leasing an IP address. As computers come and go, IP addresses are leased to those computers for a set amount of time, and then reclaimed for later reuse.
The Chicken & the Egg
As perverse as it sounds, DHCP is an Application Layer protocol (Layer 4 in the TCP/IP model) that’s used to configure a computer’s IP settings (Layer 2 in the TCP/IP model). DHCP uses UDP, which in turn uses IP. How can a protocol that relies on the IP protocol be used to configure the computer’s IP settings?
The reason DHCP can work is that even an un-configured IP stack can send and receive so-called broadcast packets.
ARP maps the IP address 255.255.255.255 to the MAC address FF:FF:FF:FF:FF:FF.
As we learned in Instalment 24, FF:FF:FF:FF:FF:FF is a special MAC address that’s used to send a packet to every device on an Ethernet network.
Devices with an un-configured IP stack can send and receive IP (and hence UDP) packets with a source address of 0.0.0.0 and a destination address of 255.255.255.255.
The DHCP protocol makes liberal use of these broadcast packets.
Prerequisites
For DHCP to work on a given Ethernet network, that network must contain one of two things — a DHCP server, or a DHCP relay agent. We’ve already mentioned that so-called home routers are not actually routers, but boxes containing many components. We already know that these devices contain a router component, an Ethernet switch component, and a wireless access point component but they actually contain more components than that. Another one of the components contained within the little boxes we refer to as home routers is a DHCP server. This means that on our home networks we have a DHCP server directly connected to our Ethernet network.
On larger networks, like those you’d find in corporations or educational institutions, you won’t find home routers powering the network. Instead, what you’ll find is that the managed switches and routers used by these organisations contain DHCP relay agents, which relay DHCP requests from all the different subnets on the network to a single central cluster of DHCP servers (usually with redundancy built-in in case a server crashes). This more complex environment is outside of the scope of this series. We’ll be ignoring DHCP relay agents for the remainder of this discussion.
How DHCP Works
DHCP is a simple request-response protocol. DHCP relies heavily on UDP broadcast packets, but whenever possible it uses regular UDP packets because they cause less congestion on a network.
When a computer configured to use DHCP is first connected to a network, a four-part conversation should follow, at the end of which the computer should have a fully configured TCP/IP stack. Assuming everything goes to plan, the following should be the sequence of events:
-
The client broadcasts a DHCP DISCOVER packet to
255.255.255.255. -
A DHCP server receives that packet and responds with A DHCP OFFER packet also broadcast to
255.255.255.255. -
The client receives the OFFER and broadcasts a DHCP REQUEST packet.
-
The server receives the REQUEST and broadcasts back a DHCP ACK packet.
What does that sequence of four packets really mean?
The initial DHCP DISCOVER is the client broadcasting its request for configuration settings to the entire network in the hope that a DHCP server will respond to it. That request contains a minimum of the MAC address of the requesting computer, a list of configuration settings it would like a value for, and a so-called magic cookie. The DISCOVER packet can also contain extra information like the client’s hostname, and the length of the lease the client would like.
The DHCP server will hear the broadcast and, assuming it’s configured to do so, respond by broadcasting a DHCP OFFER. The DHCP OFFER will contain the magic cookie, an IP, subnet, and gateway for the client’s use, a lease time, and values for as many of the requested settings as possible.
If the client is happy with the settings it was offered it will broadcast a DHCP REQUEST, formally asking that it be assigned the offered IP. The REQUEST contains the IP being requested, the client’s MAC address, the magic cookie again, and another copy of the list of desired settings.
Assuming the requested IP is still free, the server will broadcast back a DHCP ACK (acknowledgement) packet confirming to the client that it can use those details. The ACK contains the same information as the original OFFER.
Once that four-way transaction is complete, the DHCP server marks the IP as being in use for the duration of the lease, and the client uses the supplied details to configure its IP stack.
The presence of the magic cookie tells the server to return the DHCP protocol, not BOOTP.
When the lease comes to an end, the whole process does not have to be repeated. The client can simply send a new DHCP REQUEST, asking for the lease on its current IP to be extended. If the server is happy to extend the lease it will respond with a DHCP ACK. Because the client machine has an IP at this point, there is no need to use inefficient broadcast packets, so these REQUEST and ACK packets are sent directly using regular UDP packets.
Seeing DHCP Packets
We can use the tcpdump command to display all the DHCP packets reaching our computer:
sudo tcpdump -ennv port 67 or port 68This will create quite verbose output, showing the full content of every DHCP packet. The content of a packet is tabbed in, so each line starting at the left edge is the start of a new packet.
Below is a capture if the DHCP conversation between my laptop and my router, with the critical information highlighted, and a blank line inserted between each packet for extra clarity:
20:00:18.229408 60:c5:47:9b:e7:88 > ff:ff:ff:ff:ff:ff, ethertype IPv4 (0x0800), length 342: (tos 0x0, ttl 255, id 45669, offset 0, flags [none], proto UDP (17), length 328)
0.0.0.0.68 > 255.255.255.255.67: BOOTP/DHCP, Request from 60:c5:47:9b:e7:88, length 300, xid 0x6e151923, secs 2, Flags [none]
Client-Ethernet-Address 60:c5:47:9b:e7:88
Vendor-rfc1048 Extensions
Magic Cookie 0x63825363
DHCP-Message Option 53, length 1: Discover
Parameter-Request Option 55, length 9:
Subnet-Mask, Default-Gateway, Domain-Name-Server, Domain-Name
Option 119, LDAP, Option 252, Netbios-Name-Server
Netbios-Node
MSZ Option 57, length 2: 1500
Client-ID Option 61, length 7: ether 60:c5:47:9b:e7:88
Lease-Time Option 51, length 4: 7776000
Hostname Option 12, length 8: "BW-MBP-2"
20:00:18.234197 00:13:3b:0e:3f:30 > 60:c5:47:9b:e7:88, ethertype IPv4 (0x0800), length 342: (tos 0x10, ttl 128, id 0, offset 0, flags [none], proto UDP (17), length 328)
192.168.10.1.67 > 192.168.10.206.68: BOOTP/DHCP, Reply, length 300, xid 0x6e151923, Flags [none]
Your-IP 192.168.10.206
Client-Ethernet-Address 60:c5:47:9b:e7:88
Vendor-rfc1048 Extensions
Magic Cookie 0x63825363
DHCP-Message Option 53, length 1: Offer
Server-ID Option 54, length 4: 192.168.10.1
Lease-Time Option 51, length 4: 86400
Subnet-Mask Option 1, length 4: 255.255.255.0
Default-Gateway Option 3, length 4: 192.168.10.1
Domain-Name-Server Option 6, length 4: 192.168.10.1
Domain-Name Option 15, length 11: "local domain"
20:00:19.235167 60:c5:47:9b:e7:88 > ff:ff:ff:ff:ff:ff, ethertype IPv4 (0x0800), length 342: (tos 0x0, ttl 255, id 45670, offset 0, flags [none], proto UDP (17), length 328)
0.0.0.0.68 > 255.255.255.255.67: BOOTP/DHCP, Request from 60:c5:47:9b:e7:88, length 300, xid 0x6e151923, secs 3, Flags [none]
Client-Ethernet-Address 60:c5:47:9b:e7:88
Vendor-rfc1048 Extensions
Magic Cookie 0x63825363
DHCP-Message Option 53, length 1: Request
Parameter-Request Option 55, length 9:
Subnet-Mask, Default-Gateway, Domain-Name-Server, Domain-Name
Option 119, LDAP, Option 252, Netbios-Name-Server
Netbios-Node
MSZ Option 57, length 2: 1500
Client-ID Option 61, length 7: ether 60:c5:47:9b:e7:88
Requested-IP Option 50, length 4: 192.168.10.206
Server-ID Option 54, length 4: 192.168.10.1
Hostname Option 12, length 8: "BW-MBP-2"
20:00:19.239426 00:13:3b:0e:3f:30 > 60:c5:47:9b:e7:88, ethertype IPv4 (0x0800), length 342: (tos 0x10, ttl 128, id 0, offset 0, flags [none], proto UDP (17), length 328)
192.168.10.1.67 > 192.168.10.206.68: BOOTP/DHCP, Reply, length 300, xid 0x6e151923, secs 3, Flags [none]
Your-IP 192.168.10.206
Client-Ethernet-Address 60:c5:47:9b:e7:88
Vendor-rfc1048 Extensions
Magic Cookie 0x63825363
DHCP-Message Option 53, length 1: ACK
Server-ID Option 54, length 4: 192.168.10.1
Lease-Time Option 51, length 4: 7200
Subnet-Mask Option 1, length 4: 255.255.255.0
Default-Gateway Option 3, length 4: 192.168.10.1
Domain-Name-Server Option 6, length 4: 192.168.10.1
Domain-Name Option 15, length 11: "localdomain"
Beware of NACKs
We’ve already seen the four most common types of DHCP packet, DISCOVER, OFFER, REQUEST, and ACK. There are three more types you may see:
-
DHCP INFORM packets are used by clients to request more information from the server. If you configure your browser to use automatic proxy configuration, your computer can send a DHCP INFORM packet to ask the DHCP server if it knows what proxy settings should be used.
-
Polite DHCP clients can also use DHCP RELEASE packets to tell a DHCP server they are finished with an IP address. This allows the IP to be marked as free before the lease expires.
-
The final type of DHCP packet is the one you need to be wary of — the DHCP NACK.
As the name may suggest to you, NACK stands for NOT ACK, in other words, it’s a negative response to a DHCP REQUEST. It’s perfectly normal for a small percentage of the DHCP packets on a network to be NACKs as they can be produced in innocent ways. However, on a healthy network, you should see far fewer NACKs than ACKS.
When a client’s lease is coming to an end, it sends a DHCP REQUEST to ask that its lease be extended. If for any reason the server does not want to extend the lease, it will respond with a DHCP NACK. On receiving this NACK the client simply starts from zero again and sends a DHCP DISCOVER, at which point it will receive an OFFER of a different IP, which it can then REQUEST, and which the server should then ACK. This means that the pattern REQUEST, NACK, DISCOVER, OFFER, REQUEST, ACK is entirely innocent, and nothing to worry about.
DHCP NACKs can also be generated when an address that’s supposed to be managed by DHCP is hard-coded onto a device somewhere on the network. Before sending out an ACK for an IP that’s not supposed to be leased to anyone yet, the DHCP server will try ping the IP to make sure it really is free. If it gets a reply, it will respond to the REQUEST with a NACK.
Finally, some computers, when waking up from sleep or booting, like to request their old IP again, even if the lease time has expired. When this happens, it’s quite possible that the server has reused the IP, and hence it has to NACK that request. This will result in the innocent pattern REQUEST, NACK, DISCOVER, OFFER, REQUEST, ACK.
When you need to start worrying is when you see the same client get NACKed over and over again, and never get to an ACK, or, when you start to see as many or more NACKs as ACKs.
There are two common problems that can lead to excessive NACKs.
Firstly, if a network contains two DHCP servers (or more), they can end up fighting with each other. One can NACK every offer made by the other, and vice-versa. It’s possible for two dueling DHCP servers to make it impossible for anyone on the network to get an IP via DHCP. This is something I’ve witnessed a few times during my day job. This can be done accidentally, or maliciously.
Secondly, it is possible to configure your DHCP server to always assign the same IP address to a given MAC address. These so-called static leases allow you to have all the advantages of manually configured IP addresses without the disadvantages. Many home routers allow you to configure these kinds of static leases. Where things can go wrong is when there is a static lease defined for a given MAC address, and some other device on the network has been manually configured to use that IP address. The DHCP server will offer the same IP over and over again, and each time the client responds with a DHCP REQUEST it will receive a NACK because the IP is responding to PINGs. In this situation, the DHCP client will fail to connect to the network until the usurper is removed from the network.
The ipconfig Command (OS X Only)
We’ve already encountered the ifconfig command which is common to all POSIX OSes, but OS X also contains a separate command which provides command-line access to many of the functions exposed in the Network System Preference Pane.
I’m referring to the confusingly named ipconfig.
The reason I say this is a confusing name is that it’s very similar to ifconfig and identical to a completely different Windows command.
ipconfig can be used to turn a network interface off as follows (replacing enX with the actual interface you want to disable):
sudo ipconfig set enX NONEipconfig can be used to enable a network interface in DHCP mode as follows (again replacing enX with the actual interface you want to disable):
sudo ipconfig set enX DHCPFinally, ipconfig can be used to show the DHCP ACK packet that was used to configure a network interface (again replacing enX with the actual interface you want to get the packet for):
sudo ipconfig getpacket enXThe relevant information is in the options section near the bottom of the output, highlighted below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
BW-MBP-2:~ bart$ sudo ipconfig getpacket en1
Password:
op = BOOTREPLY
htype = 1
flags = 0
hlen = 6
hops = 0
xid = 1846876452
secs = 0
ciaddr = 192.168.10.206
yiaddr = 192.168.10.206
siaddr = 0.0.0.0
giaddr = 0.0.0.0
chaddr = 60:c5:47:9b:e7:88
sname =
file =
options:
Options count is 8
dhcp_message_type (uint8): ACK 0x5
server_identifier (ip): 192.168.10.1
lease_time (uint32): 0x15180
subnet_mask (ip): 255.255.255.0
router (ip_mult): {192.168.10.1}
domain_name_server (ip_mult): {192.168.10.1}
domain_name (string): localdomain
end (none):
BW-MBP-2:~ bart$
For a full description of everything ipconfig can do, see its man page:
man ipconfigThe Security Elephant in the Room (Again)
As we saw with ARP previously, there is no security built into the DHCP protocol. DHCP clients will blindly implement whatever settings a DHCP server hands them. This is usually fine, because most of the time, the only DHCP server on your network is one that is there to help, but not always. A DHCP server process is small and simple. Any computer can act as a DHCP server. An attacker could connect to an open wireless network and run their own DHCP server, advertising their IP as the gateway, and hence become a Man In The Middle. Similarly, a malicious DHCP server could advertise a malicious DNS server, also allowing them to redirect all internet traffic to malicious servers.
As a user, your only defence is to assume the worst on all networks you don’t control, and use technologies like VPNs and TLS/SSL to protect your data.
Network administrators can also protect their users by monitoring the source addresses of all DHCP OFFER, DHCP ACK, DHCP NACK, and DHCP INFORM packets and triggering an alarm if any unauthorised DHCP servers become active on the network.
Conclusions
The two critical pieces of information to take away from this instalment are that DHCP is used to automatically configure the IP stack on our computers and that a healthy DHCP transaction takes the following form: DISCOVER, OFFER, REQUEST, ACK.
In the previous two instalments, we learned how Ethernet and IP provide the basic networking functionality our computers need to communicate. In this instalment, we’ve seen how our home routers use the DHCP protocol to automatically configure the IP settings on our devices. In the next instalment, we’ll learn how DNS allows us as humans to ignore IP addresses while surfing the web, sending emails, playing games, and so much more.
Once we’ve added an understanding of DNS to our mental toolkit, we’ll be ready to apply everything we have learned in instalments 23 through 27 together in a single instalment dedicated to terminal commands for network troubleshooting.
TTT Part 27 of n — DNS
In part 23 of n, we took a big-picture look at how TCP/IP networking works. As a quick reminder, the most important points were:
-
Our computer networks use a stack of protocols known as TCP/IP
-
We think of the stack of protocols as being broken into four layers:
-
The Link Layer — lets computers that are on the same network send single packets of data to each other
-
The Internet Layer — lets computers on different networks send single packets of data to each other
-
The Transport Layer — lets computers send meaningful streams of data between each other
-
The Application Layer — where all the networked apps we use live
-
-
Logically, data travels across the layers — HTTP to HTTP, TCP to TCP, IP to IP, Ethernet to Ethernet, but physically, data travels up and down the stack, one layer to another, only moving from one device to another when it gets to the Link Layer at the very bottom of the stack.
We have now looked in detail at Layer 1 and Layer 2, and have looked at how DHCP allows our computers to automatically configure their TCP/IP network stack. In this instalment, we’re going to look at a Layer 4 protocol that is essential to our use of the internet — DNS.
At layers 2 and 3, all addressing is by IP address, yet just about every networked app we use totally insulates us from that fact. Our computers think in terms of IP addresses, but we think in terms of domain names. The Domain Name System (DNS) exists to bridge this gap, allowing domain names to be converted to IP addresses, and IP addresses to domain names.
Listen Along: Taming the Terminal Podcast Episodes 27a & 27b
| Episode 27a | Episode 27b |
|---|---|
Scan the QR code to listen on a different device |
|

|

|
You can also play/download the MP3 in your browser (a) |
You can also play/download the MP3 in your browser (b) |
The Hosts File
In the early days of the internet the conversion between human-readable hostnames for computers and IP addresses was stored within each computer in a single file — /etc/hosts.
This meant that names were not in any way authoritative.
I could give whatever name I wanted to an IP address and save that mapping into my /etc/hosts file, and you could give the same IP address a completely different name and save that mapping in your /etc/hosts file.
Organisations could choose to centrally manage /etc/hosts file by keeping an authoritative copy on a file server and having a script copy that file to every computer within the organisation overnight, but it really was up to each organisation to decide how they would manage hostname to IP address mappings.
While DNS superseded the hosts file, it did not replace it. The hosts file still exists in Linux, Unix, OS X, and even Windows! On a POSIX OS like OS X you can view the content of the file with the command:
cat /etc/hostsThis file is given a higher priority than DNS by your operating system, so any name to IP mappings you add to this file will override the official mappings from DNS.
This can be very useful.
It can be used as a crude form of website blocking. If you map a website you don’t want your kids to use to a non-existent IP address, or to the loopback address (127.0.0.1), then that site will be inaccessible.
Another great use for the hosts file is to test a new website before you make it live.
Finally, you can also use the hosts file to add memorable names to computers on your own home network.
It’s a much simpler approach than running your own private DNS infrastructure.
The hosts file is a plain text file with a very simplistic format. Each line must start with an IP address followed by one or more names separated by blank space. If I wanted to add two aliases to my home router, I could add a line like:
192.168.10.1 myrouter myrouter.localdomainI would now be able to access the web interface for my router at https://myrouter and https://myrouter.localdomain.
It’s also helpful to note that lines starting with a # are interpreted as comment lines, and ignored by the OS.
If you’re going to use the hosts file extensively, it’s a good idea to comment your changes so you know why you did what you did when you look back at the file a few months or years hence!
Finally, be aware that the file is owned by root, so you need to use sudo to gain root privileges to edit the file, e.g.:
sudo vi /etc/hosts
sudo pico /etc/hostsThe Domain Name System
The DNS spec was released in 1983, and the first Unix DNS server was written in 1984. Although the spec has been added to in the intervening years, the fundamental design remains unchanged.
The DNS Philosophy
Before DNS, computers had simple hostnames but DNS took things to the next level by introducing the concept of a hierarchy of names. In DNS speak, a group of related names are known as a zone but most people refer to them as domains.
The hierarchy of domain names is anchored at the top by the so-called root zone, which has the one-letter name . (almost universally omitted when domain names are written).
Below the root, you will find the so-called TLDs or Top Level Domains like .com, .net, .org, and so on.
As well as generic TLDs like those examples, there are also country-specific TLDs, like .ie for Ireland, .be for Belgium, .fr for France, and so forth.
Some countries have also chosen to break their TLDs up into multiple sub-TLDs, a practice that seems particularly common among former British colonies!
E.g.
in Australia commercial sites are .com.au while educational sites are .edu.au.
A particularly cryptic one is .ac.uk, which is the TLD for UK educational institutions (the ac stands for Academic Community).
Institutions and the general public can buy the rights to use domain names one level down from TLDs.
Allison Sheridan, for example, has the rights to podfeet.com, and I have the rights to bartb.ie.
Once you own a domain you can then break it down any way you like, adding as many or as few subdomains as desired.
www.podfeet.com is a subdomain of podfeet.com which is a subdomain of the generic TLD .com which is a subdomain of the root (.).
Technically, www.podfeet.com should be written as www.podfeet.com., but as a species, we’ve decided that the DNS root zone should be implied rather than explicitly added to domain names, and we’ve written our software with that implicit assumption.
You are entirely free to add the final dot back in though, it is part of the spec after all!
The best way to think of DNS names is as a tree, as illustrated in the diagram below. But, rather than reading the tree from root to leaf, we always read it backwards, from leaf to root.
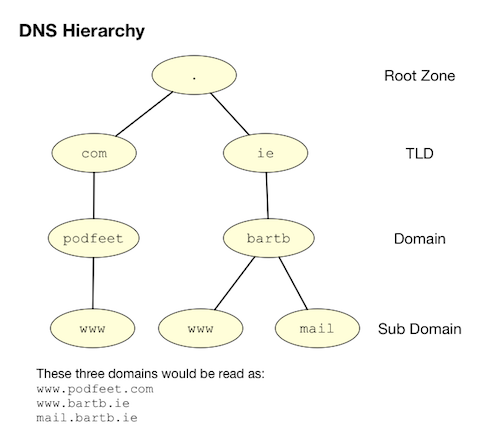
DNS Records
Many people describe DNS as being like the internet’s phone book, because like a phone book, it turns names into numbers. That’s not a bad analogy, but it’s overly simplistic. A phone book contains only one type of record, phone numbers, but the DNS system contains records of many different types. The list below is not exhaustive, but covers the records you’re most likely to encounter:
| Type | Description |
|---|---|
|
A DNS A record maps a domain name to an IPv4 IP address — the most common kind of DNS record |
|
Someday DNS AAAA records may replace A records as the most common — they map domain names to IPv6 addresses. |
|
A DNS CNAME (Canonical Name) record maps a domain name to another domain name.
Think of CNAME records as DNS aliases.
E.g.
If you outsource your email service to a third party but don’t want to give people a URL with another company’s domain name in it, you could set up a CNAME record to alias |
|
DNS MX records, or Mail eXchanger records specify the domain name of the mail server that accepts email for a given domain. |
|
DNS PTR records are used by the reverse-DNS system to map a domain name to an IP address (think of them as the inverse of A records). |
|
DNS NS records map a domain name to the domain name of the server that is authoritative for that domain (domains usually have 2 or 3 NS records) |
|
DNS TXT records, or text records, are used to map a domain name to an arbitrary piece of text. A common usage for TXT records is to prove domain ownership. Certificate authorities and cloud service providers often force people applying for a certificate or a service to prove they own a domain name by asking that they set a given TXT record on the domain. |
|
DNS SRV records, or service records, are used to map service to a given domain name, port number, and protocol. Microsoft Windows licensing and Microsoft Active Directory make extensive use of SRV records for service auto-discovery. E.g., a DNS SRV record is used by Windows desktop computers in large organisations with centrally managed multi-user licenses to figure out what server they should contact to license themselves. |
If this series was targeted at corporate sysadmins we’d focus heavily on A, AAAA, PRT & SRV records. If it was targeted at webmasters we’d focus on A, CNAME, NS and TXT records. But, as this series is targeted at home users, we’re only really interested in A, CNAME & MX records.
DNS Servers
An important subtlety in the operation of DNS is that there are two very distinct types of DNS servers that fulfil two entirely different roles. Hence, talking about a DNS Server without any more specificity is meaningless, and only likely to lead to confusion. To save everyone’s sanity you should never use the term DNS Server. Instead, always refer to either Authoritative DNS Servers or DNS Resolvers.
Authoritative DNS Servers
Authoritative DNS servers are responsible for hosting the DNS records for a domain.
Each domain has to be served by at least one authoritative server, and almost all domains have two or more authoritative servers.
Large organisations like corporations and universities often run their own authoritative servers, but the general public generally pays a domain registrar to provide authoritative DNS servers for their domains.
E.g.
I pay Register365 to host the DNS zone for bartb.ie on their cluster of authoritative DNS servers, and Allison pays GoDaddy to host the DNS zone for podfeet.com on their cluster of authoritative DNS servers.
Most of us rely on our domain registrars to perform two functions for us — register the domain, and host the DNS zone on their authoritative servers. It is entirely possible to separate those two functions. Sometimes it makes more sense to have the company that hosts your website also host your DNS zone on their authoritative DNS servers. The fact that these two roles are separable causes a lot of confusion.
What really happens is that your registrar manages the NS records for your domain, and you can then point those NS records at their authoritative DNS servers, or any other authoritative DNS servers of your choice, perhaps those belonging to your hosting company.
Unless you own your own domain, you probably don’t need to know about authoritative DNS servers.
If you do own your own domain, you are probably administering it through an online control panel with your domain registrar or hosting provider. You should be able to access an interface that looks something like the one in the screenshot below (from Hover.com) where you can see all the DNS records set on your domain, edit them, and add new ones.
What you can see in the screenshot above is that there are just three DNS records in the xkpasswd.net zone: two A records (one for xkpasswd.net, and one for www.xkpasswd.net), and an MX record.
You’ll notice that one of the A records and the MX record use the shortcut symbol @ to represent ‘this domain’.
In other words, in this example, where ever you see @, replace it with xkpasswd.net.
The @ symbol is used in this way in many DNS control panels, and indeed many many DNS configuration files.
DNS Resolvers
DNS Resolvers do the actual work of looking up the DNS records for a given domain name, whether it’s A records and CNAME records for turning domain names into IP addresses, or MX records for figuring out what mail server an email for a given domain should be sent to. DNS resolvers query the authoritative DNS servers to perform these lookups.
When DHCP pushes a name server setting to your computer, it is specifying which DNS Resolver your computer should use. When you look at the Name Server setting in the Network System Preference Pane, you will see what DNS Resolver your computer is configured to use.
On most Linux and Unix OSes, DNS resolution is controlled using the configuration file /etc/resolv.conf.
This file is present in OS X but is used as a way for the OS to expose the settings to scripts and command-line utilities rather than as a way of controlling DNS configuration.
The file on OS X is in the identical format to the ones on Linux and Unix.
You can have a look at this file with the command:
cat /etc/resolv.confTypes of DNS Resolver
A true DNS resolver works its way from the DNS root servers out to the requested domain name one step at a time.
For example, for a DNS resolver to convert www.bartb.ie to an IP address it must follow the following steps:
-
Query one of the root DNS servers for the A record for
www.bartb.ie.(the list of DNS root servers is hardcoded into the resolver’s configuration) -
The root DNS server will respond that it doesn’t know the answer to that query, but that it does know the authoritative name servers responsible for the
.ie.zone. In other words, the first query returns a list of NS records for the.iedomain. -
The resolver then asks one of the authoritative DNS servers for
.ieif it has an A record forwww.bartb.ie. -
The
.ieauthoritative server responds that it doesn’t, but that it does know the authoritative servers for thebartb.ie.zone. The server returns the list of NS records forbartb.ieto the resolver. -
The resolver then asks one of the authoritative servers for the
bartb.ie.zone if it has an A record forwww.bartb.ie. -
This is my authoritative DNS server, and I have properly configured it, so it does indeed know the answer, and returns the IP address for
www.bartb.ieto the resolver.
The second type of DNS resolver is called the stub resolver. Stub resolvers don’t do the hard work of resolution themselves, instead, they forward the request to another resolver and wait to be told the answer.
Our operating systems contain stub resolvers and our home routers contain stub resolvers. Our ISPs provide true resolvers, as do some third-party organisations like Google and OpenDNS.
If we imagine the typical home network, what happens when you type an address into the URL bar of your browser is that your browser asks your OS for the IP address that matches the URL you just entered. Your OS passes that request on to its internal stub resolver. The stub resolver in your OS passes the query on to the name server DHCP told it to use (almost certainly your home router). Your home router also contains a stub resolver, so it, in turn, passes the request on to the name server it was configured to use by the DHCP packet it received from your ISP. Finally, your ISP’s resolver does the actual resolving and replies to your router with the answer which replies to the stub resolver in your OS which replies to your browser.
When you take into account the redirections by the stub resolvers as well as the actual resolution, you find that six separate DNS requests were needed to convert www.bartb.ie to 46.22.130.125:
-
Browser to stub resolver in OS
-
Stub resolver in OS to stub resolver in router
-
Stub resolver in router to true resolver in ISP
-
True resolver in ISP to root DNS server
-
True resolver in ISP to
.ieAuthoritative DNS server -
True resolver in ISP to
bartb.ieAuthoritative DNS server in Register365
DNS Caching
If every DNS query generated this much activity the load on the root DNS servers would be astronomical, the load on the authoritative servers for the TLDs would be massive too, and even the load on authoritative servers for regular domains like bartb.ie would be large.
To make DNS practical, caching is built into the protocol’s design. DNS caching is not an afterthought, it was designed in from the start.
Every response to a DNS query by an authoritative server contains a piece of metadata called a TTL. This stands for Time to Live and is expressed as a number of seconds. The TTL tells resolvers how long the result may be cached for.
All DNS resolvers, including stub resolvers, can cache results.
This means that in reality, only a small percentage of the queries your ISP’s true resolver receives need to be resolved from first principles.
All the common sites like www.google.com will be in the cache, so the resolver can reply without doing any work.
Similarly, the stub resolver in your home router can also cache results, so if anyone in your house has been to podfeet.com recently, the stub resolver can answer directly from the cache without ever contacting your ISP’s resolver.
The stub resolvers within our OSes can also cache results, so if you visit the same domain in two different browsers, you only need to contact your home router once.
Finally, browsers can also cache responses, so as you browse from page to page within a given site, your browser doesn’t keep asking the stub resolver built into your OS the same question over and over again.
Between your browser’s cache, your OS’s cache, your router’s cache and your ISP’s cache, only a tiny percentage of queries result in work for the root DNS servers or the authoritative DNS servers.
Also — it’s not just positive results that get cached — if a domain name is found not to exist, that non-existence is also cached.
This multi-layered caching makes DNS very efficient, but it comes at a price, changes made on the authoritative servers do not propagate instantaneously. They only become visible when all the caches between the user and the authoritative server have expired and the data is refreshed.
The DNS Protocol
DNS is a Layer 4 protocol that sits on top of UDP. Each query consists of a single packet, as does each reply. This use of single packets makes DNS very efficient, but it limits the amount of data that can be contained in a reply, and, it means that requests and replies can get silently dropped because UDP does not guarantee delivery of every packet. Because of this, DNS resolvers sometimes have to retry their requests after a certain timeout value.
Authoritative servers and DNS resolvers listen on UDP port 53.
DNS Commands
Windows users must use the old nslookup command to resolve domain names:
nslookup domain.nameThis command is still present in most Unix and Linux variants, including OS X, but is marked as deprecated on some modern distributions.
POSIX users, including Mac users, should probably get out of the habit of using nslookup and start relying on the host command for simple queries, and the dig command for complex queries instead.
The host command is superbly simple, it accepts one argument, the domain name to resolve, and prints out the corresponding IP address.
If the domain has an MX record that value is printed out too, and if the answer had to be arrived at by following one or more CNAME aliases those intermediate steps are printed out as well.
E.g.
1
2
3
4
5
6
7
8
9
10
11
bart-iMac2013:~ bart$ host www.bartb.ie
www.bartb.ie has address 46.22.130.125
bart-iMac2013:~ bart$ host www.podfeet.com
www.podfeet.com is an alias for podfeet.com.
podfeet.com has address 173.254.94.93
podfeet.com mail is handled by 10 aspmx.l.google.com.
podfeet.com mail is handled by 20 alt1.aspmx.l.google.com.
podfeet.com mail is handled by 30 alt2.aspmx.l.google.com.
podfeet.com mail is handled by 40 aspmx2.googlemail.com.
podfeet.com mail is handled by 50 aspmx3.googlemail.com.
bart-iMac2013:~ bart$
The dig command is the swiss-army knife of DNS.
For a full list of its many features see:
man digThe basic structure of the command is as follows:
dig [options] domain.name [record_type] [@server]If you don’t specify a record type, an A record is assumed, and if you don’t specify a server, the OS’s specified resolver is used.
If you don’t specify any options you will see quite verbose output, showing both the DNS query sent and the reply, if any.
This can be quite confusing, which is why I suggest using the simpler host command for basic queries.
E.g.
the following shows the output when trying to resolve www.bartb.ie which exists, and wwww.bartb.ie which does not.
There is so much output that at first glance you might think both queries had succeeded.
bart-iMac2013:~ bart$ dig www.bartb.ie
; <<>> DiG 9.8.3-P1 <<>> www.bartb.ie
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 32641
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;www.bartb.ie. IN A
;; ANSWER SECTION:
www.bartb.ie. 18643 IN A 46.22.130.125
;; Query time: 0 msec
;; SERVER: 192.168.10.1#53(192.168.10.1)
;; WHEN: Tue Dec 30 19:08:41 2014
;; MSG SIZE rcvd: 46
bart-iMac2013:~ bart$ dig wwww.bartb.ie
; <<>> DiG 9.8.3-P1 <<>> wwww.bartb.ie
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 4581
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0
;; QUESTION SECTION:
;wwww.bartb.ie. IN A
;; AUTHORITY SECTION:
bartb.ie. 1799 IN SOA ns0.reg365.net. support.reg365.net. 2013011301 28800 3600 604800 86400
;; Query time: 32 msec
;; SERVER: 192.168.10.1#53(192.168.10.1)
;; WHEN: Tue Dec 30 19:08:47 2014
;; MSG SIZE rcvd: 89
bart-iMac2013:~ bart$What you will notice is that in the first output there is some metadata followed by a number of distinct sections, and finally some more metadata.
You can tell the second query failed for two reasons.
Firstly, in the metadata at the top of the output, the status of the query is shown as NXDOMAIN (non-existent domain) rather than NOERROR.
Secondly, there is no ANSWER section in the output.
Sometimes this detailed output is very useful, but oftentimes it just gets in the way.
You can suppress the extra information by using the +short option:
bart-iMac2013:~ bart$ dig +short www.bartb.ie
46.22.130.125
bart-iMac2013:~ bart$ dig +short wwww.bartb.ie
bart-iMac2013:~ bart$You can request records other than A records by specifying the type of record you want after the domain name, e.g.:
bart-iMac2013:~ bart$ dig +short podfeet.com NS
ns02.domaincontrol.com.
ns01.domaincontrol.com.
bart-iMac2013:~ bart$ dig +short podfeet.com MX
10 aspmx.l.google.com.
20 alt1.aspmx.l.google.com.
30 alt2.aspmx.l.google.com.
40 aspmx2.googlemail.com.
50 aspmx3.googlemail.com.
bart-iMac2013:~ bart$ dig +short podfeet.com TXT
"google-site-verification=T6-e-TwfJb8L7TAR8TpR_qQlyzfIafm_a7Lm9cN97kI"
bart-iMac2013:~ bart$You can also use dig to interrogate an authoritative server directly or to use a resolver other than the one configured in the OS by adding a final argument starting with an @ symbol.
The argument can be either the domain name for the server your want to query or the IP address of the server.
This can useful when trying to figure out whether or not a given DNS resolver is functioning, or, when testing changes made to authoritative servers without having to wait for all the caches to expire.
Below is an example of each use, first querying Google’s free public resolver for the name server for bartb.ie, and then querying the authoritative server for bartb.ie for the A record for www.bartb.ie (I’ve left off the +short so you can see which servers were queried in the metadata at the bottom of the output):
bart-iMac2013:~ bart$ dig bartb.ie NS @8.8.8.8
; <<>> DiG 9.8.3-P1 <<>> bartb.ie NS @8.8.8.8
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 55395
;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;bartb.ie. IN NS
;; ANSWER SECTION:
bartb.ie. 21185 IN NS ns1.reg365.net.
bartb.ie. 21185 IN NS ns0.reg365.net.
bartb.ie. 21185 IN NS ns2.reg365.net.
;; Query time: 12 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Tue Dec 30 19:23:38 2014
;; MSG SIZE rcvd: 90
bart-iMac2013:~ bart$ dig www.bartb.ie @ns1.reg365.net
; <<>> DiG 9.8.3-P1 <<>> www.bartb.ie @ns1.reg365.net
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 36163
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;www.bartb.ie. IN A
;; ANSWER SECTION:
www.bartb.ie. 86400 IN A 46.22.130.125
;; Query time: 24 msec
;; SERVER: 85.233.160.78#53(85.233.160.78)
;; WHEN: Tue Dec 30 19:24:03 2014
;; MSG SIZE rcvd: 46
bart-iMac2013:~ bart$Finally, the +trace command can be used to do a full top-down resolution of a given domain name in the same way that a resolver would if the result was not cached.
To see what question is being asked at each stage of the trace, I like to add the +question option as well.
bart-iMac2013:~ bart$ dig +trace +question www.bartb.ie
; <<>> DiG 9.8.3-P1 <<>> +trace +question www.bartb.ie
;; global options: +cmd
;. IN NS
. 18794 IN NS m.root-servers.net.
. 18794 IN NS a.root-servers.net.
. 18794 IN NS c.root-servers.net.
. 18794 IN NS h.root-servers.net.
. 18794 IN NS i.root-servers.net.
. 18794 IN NS d.root-servers.net.
. 18794 IN NS g.root-servers.net.
. 18794 IN NS k.root-servers.net.
. 18794 IN NS e.root-servers.net.
. 18794 IN NS l.root-servers.net.
. 18794 IN NS f.root-servers.net.
. 18794 IN NS j.root-servers.net.
. 18794 IN NS b.root-servers.net.
;; Received 228 bytes from 192.168.10.1#53(192.168.10.1) in 16 ms
;www.bartb.ie. IN A
ie. 172800 IN NS a.ns.ie.
ie. 172800 IN NS b.ns.ie.
ie. 172800 IN NS c.ns.ie.
ie. 172800 IN NS d.ns.ie.
ie. 172800 IN NS e.ns.ie.
ie. 172800 IN NS f.ns.ie.
ie. 172800 IN NS g.ns.ie.
ie. 172800 IN NS h.ns.ie.
;; Received 485 bytes from 192.203.230.10#53(192.203.230.10) in 36 ms
;www.bartb.ie. IN A
bartb.ie. 172800 IN NS ns0.reg365.net.
bartb.ie. 172800 IN NS ns1.reg365.net.
bartb.ie. 172800 IN NS ns2.reg365.net.
;; Received 94 bytes from 77.72.72.44#53(77.72.72.44) in 14 ms
;www.bartb.ie. IN A
www.bartb.ie. 86400 IN A 46.22.130.125
;; Received 46 bytes from 85.233.160.79#53(85.233.160.79) in 23 ms
bart-iMac2013:~ bart$The first thing dig does is ask my stub resolver for a list of the root name servers.
You see the output as a list of 13 NS records for the domain ..
Once dig knows the root name servers, it starts the actual resolution of www.bartb.ie, asking one of those 13 servers (192.203.230.10) if it has an A record for www.bartb.ie.
The root server doesn’t respond with a direct answer to the question, but with a list of eight authoritative name servers for the .ie zone.
dig then asks one of the .ie name servers (77.72.72.44) if it has an A record for www.bartb.ie.
It also doesn’t answer the question but responds with a list of three authoritative name servers for the bartb.ie zone.
Finally, dig asks one of the authoritative servers for bartb.ie (85.233.160.79) if it has an A record for www.bartb.ie.
This server does know the answer, so it replies with that A record, specifying that www.bartb.ie is at 46.22.130.125.
The Security Elephant in the Room
As with so many of the older protocols we’ve discussed in this series, DNS was created at a time when security simply wasn’t a consideration.
The source of the weakness is two-fold, firstly, DNS packets are not encrypted, and there is no tamper detection included in the protocol, so it’s trivially easy for any attackers who get themselves into a man-in-the-middle position to rewrite DNS responses to silently redirect people to malicious servers. If you were in a coffee shop and one of your fellow caffeine aficionados had used the lack of security in the ARP protocol to become a man-in-the-middle, they could alter the IP address your computer thinks any site, say paypal.com as an example, maps to. If they then set up their own server at the incorrect IP and make it look like PayPal’s site, they could easily trick people into revealing their usernames and passwords.
Because of how UDP works, it is possible to send a UDP packet with a forged source address. Attackers can use this fact to bombard victims with fake DNS responses in the hope that the fake response is received before the real one. This fake response can contain any length of TTL, so attackers can have their malicious response cached for a very long time. This is known as DNS Cache Poisoning.
Cache poisoning is not as easy as it used to be because the source ports for DNS queries are now randomised. This means that a remote attacker needs to correctly guess the random port number for their fake packet to have any chance of being accepted. Attackers can get around this by sending LOTS of false responses with different random port numbers but the protection is not perfect. An attacker with enough determination and bandwidth can still poison a DNS cache. Also, note that Man-in-the-middle (MITM) attackers see both the request and response packets, so they don’t need to guess the port number, they can simply alter the valid response packet to say what they want it to say, so port randomisation provides no protection from MITM attacks.
The good news though is that there is a solution in the making. An extension to DNS called DNSSEC provides a solution by cryptographically signing DNS responses. This does not prevent an attacker from altering the response or sending fake responses, but it does make it possible for the recipient to know the response is fake, and ignore it.
DNSSEC is quite slow to be rolled out, but it is starting to happen now.
Conclusions
We’ve seen how DNS converts human-readable domain names into computer-readable IP addresses. It is vital that our computers have access to a working DNS Resolver because if they don’t, the internet will be unusable.
From previous instalments, we already know that for a computer to function properly on a TCP/IP network it must have three settings properly configured, an IP address, a netmask, and a default gateway. We can now add a fourth required setting, a DNS resolver, or name server.
In the next instalment, we’ll focus on tools for troubleshooting network problems. We’ll have seen many of the commands before, but we’re looking at them in more detail and in context. The aim of the next instalment will be to build up a troubleshooting strategy that starts at the bottom of the network stack and works up through it methodically to locate the problem, allowing you to focus your efforts in the right place, and avoid wasting your time debugging things that are actually working just fine.
TTT Part 28 of n — Network Troubleshooting
In part 23 of n, we took a big-picture look at how TCP/IP networking works. As a quick reminder, the most important points were:
-
Our computer networks use a stack of protocols known as TCP/IP
-
We think of the stack of protocols as being broken into four layers:
-
The Link Layer — lets computers that are on the same network send single packets of data to each other
-
The Internet Layer — lets computers on different networks send single packets of data to each other
-
The Transport Layer — lets computers send meaningful streams of data between each other
-
The Application Layer — where all the networked apps we use live
-
-
Logically, data travels across the layers — HTTP to HTTP, TCP to TCP, IP to IP, Ethernet to Ethernet, but physically, data travels up and down the stack, one layer to another, only moving from one device to another when it gets to the Link Layer at the very bottom of the stack.
Since that big-picture introduction we’ve looked at the first three layers in detail, and we’ve also looked at two layer-4 protocols that function as part of the network infrastructure — DHCP for the automatic discovery of network settings, and DNS for mapping domain names to IP addresses. Later in the series, we will move on to look at some more Layer 4 protocols, but before we do I want to consolidate what we’ve learned so far into a strategy for debugging network problems. In short — how to get from a vague complaint like “the internet is broken” to a specific problem that can be addressed.
Listen Along: Taming the Terminal Podcast Episode 28
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
When troubleshooting network problems, the basic advice is to start at the bottom of the stack and work your way up until you find the problem. You can break the process down into four loose steps:
-
Basic Network Connectivity: make sure the computer has at least one active network connection.
-
IP Configuration: make sure the computer has the three required IP settings configured:
-
An IP address
-
A Netmask
-
A default gateway
-
-
IP Connectivity:
-
Test whether the computer can communicate with the default gateway (probably your home router)
-
Test whether the computer can communicate with a server on the internet
-
-
Domain Name Resolution: make sure the computer can use DNS to resolve domain names to IP addresses.
Let’s now look at these steps in more detail, and at the terminal commands we’ll need for each. At the end of each section, we’ll also describe what we should see if everything is working correctly at that level of the stack, and some things to consider if you find results that are not as expected.
Step 1 — Check Basic Network Connectivity
Starting at the very bottom of the network stack we need to make sure there is at least one network interface up and connected before we continue.
The terminal command for listing network interfaces is ifconfig.
We’ve seen this command in previous instalments but never looked at it in detail.
Note that there are some subtle differences between the versions of this command available on OS X and on Linux.
In our examples, we will be using the OS X version of the command.
ifconfig can be used to both show and alter the configuration of network interfaces.
Note that we will only be using the command to display the current settings, not to alter them.
On OS X you should use the Networks system preference pane to change network settings.
To get a list of the names of all network interfaces defined on a Mac run the following command (does not work in Linux):
ifconfig -lThe command will return the names on a single line separated by spaces.
Remember that lo0 is the so-called loop-back address used for purely internal network communication and that on Macs, ‘real’ network interfaces will be named en followed by a number, e.g.
en0 and en1.
Any other network interfaces you see are either non-traditional interfaces like firewire or virtual interfaces created by software like VPN clients.
When it comes to basic network troubleshooting it’s the en devices that we are interested in.
Once you know the names of your network devices you can see more information for any given device bypassing the device name as an argument.
E.g. the following is the description of my en0 interface:
bart-iMac2013:~ bart$ ifconfig en0
en0: flags=8863<UP,BROADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500
options=10b<RXCSUM,TXCSUM,VLAN_HWTAGGING,AV>
ether 68:5b:35:97:f1:84
inet6 fe80::6a5b:35ff:fe97:f184%en0 prefixlen 64 scopeid 0x4
inet 192.168.10.42 netmask 0xffffff00 broadcast 192.168.10.255
nd6 options=1<PERFORMNUD>
media: autoselect (1000baseT <full-duplex,flow-control,energy-efficient-Ethernet>)
status: active
bart-iMac2013:~ bart$You can also see the details for all network interfaces by replacing the interface name with the -a flag (this is what the OS X version of ifconfig does implicitly if called with no arguments):
ifconfig -aA more useful option is -u, which lists all interface marked by the OS as being in an up state.
Note that an interface can be up, but inactive.
By default, ifconfig returns quite a bit of information for each interface, but not enough to make it obvious which interface matches which physical network connection.
You can get more information by adding the -v flag (for verbose).
Putting it all together, the command to run when verifying that there is basic network connectivity is ifconfig -uv.
The following sample output shows one active Ethernet network connection, en0, and one inactive WiFi connection en1.
The important parts of the output have been highlighted for clarity:
bart-iMac2013:~ bart$ ifconfig -uv
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384 index 1
eflags=10000000<SENDLIST>
options=3<RXCSUM,TXCSUM>
inet6 ::1 prefixlen 128
inet 127.0.0.1 netmask 0xff000000
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x1
inet 127.94.0.1 netmask 0xff000000
inet 127.94.0.2 netmask 0xff000000
nd6 options=1<PERFORMNUD>
link quality: 100 (good)
en0: flags=8863<UP,BROADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500 index 4
eflags=980<TXSTART,RXPOLL,ARPLL>
options=10b<RXCSUM,TXCSUM,VLAN_HWTAGGING,AV>
ether 68:5b:35:97:f1:84
inet6 fe80::6a5b:35ff:fe97:f184%en0 prefixlen 64 scopeid 0x4
inet 192.168.10.42 netmask 0xffffff00 broadcast 192.168.10.255
nd6 options=1<PERFORMNUD>
media: autoselect (1000baseT <full-duplex,flow-control,energy-efficient-Ethernet>)
status: active
type: Ethernet
link quality: 100 (good)
scheduler: QFQ
link rate: 1.00 Gbps
en1: flags=8823<UP,BROADCAST,SMART,SIMPLEX,MULTICAST> mtu 1500 index 5
eflags=200080<TXSTART,NOACKPRI>
ether c8:e0:eb:48:02:7b
nd6 options=1<PERFORMNUD>
media: autoselect (<unknown type>)
status: inactive
type: Wi-Fi
scheduler: TCQ (driver managed)
bart-iMac2013:~ bart$Expected Results
If all is well, there should be two network interfaces active, the loopback interface (lo0), and an interface of either type Ethernet or WiFi.
Possible Problems/Solutions
-
No interface is active — turn one on in the Network System Preference Pane
-
If using Ethernet, the cable could be bad, or the router/switch it is plugged into could be bad — check for a link light on the router/switch
-
The network card could be broken (unlikely)
Step 2 — Check Basic IP Configuration
For a computer to have IP connectivity it needs three settings. It needs to know its IP address, it needs to know its Netmask, and it needs to know the IP address of the router it should use to communicate beyond the local network. This last setting is referred to by a number of different names, including default gateway, default route, and just router. A network is incorrectly configured if the IP address for the default gateway is outside the subnet defined by the combination of the IP address and netmask. If you’re not sure if the gateway address is contained within the defined subnet, you may find an online IP subnet calculator like subnetcalc.it helpful.
If an IP address has been configured for an interface there will be a line starting with inet in that interface’s description in the output from ifconfig.
This line will give you the IP address and netmask.
Below is an example of the output for my one active network interface, en0:
bart-iMac2013:~ bart$ ifconfig -v en0
en0: flags=8863<UP,BROADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500 index 4
eflags=980<TXSTART,RXPOLL,ARPLL>
options=10b<RXCSUM,TXCSUM,VLAN_HWTAGGING,AV>
ether 68:5b:35:97:f1:84
inet6 fe80::6a5b:35ff:fe97:f184%en0 prefixlen 64 scopeid 0x4
inet 192.168.10.42 netmask 0xffffff00 broadcast 192.168.10.255
nd6 options=1<PERFORMNUD>
media: autoselect (1000baseT <full-duplex,flow-control,energy-efficient-Ethernet>)
status: active
type: Ethernet
link quality: 100 (good)
scheduler: QFQ
link rate: 1.00 Gbps
bart-iMac2013:~ bart$While looking at this output it’s also worth checking that the link quality is being shown as good.
To read the default route you’ll need to use the netstat command.
We haven’t looked at this command in detail yet, and we won’t be until a future instalment.
For now, we just need to know that the following command will show us the IP address of the default router:
netstat -rn | egrep '^default'The following sample output shows that my default gateway is set to 192.168.10.1:
bart-iMac2013:~ bart$ netstat -rn | egrep '^default'
default 192.168.10.1 UGSc 28 0 en0
bart-iMac2013:~ bart$Expected Result
There will be an IP address, netmask, and default gateway configured, and the default gateway will be within the subnet defined by the IP address and netmask. Make a note of these three settings for future reference.
Possible Problems/Solutions
-
DHCP has been disabled on the interface — enable it using the Network System Preference Pane
-
DHCP is not working on the network — this will need to be addressed on the router
Step 3 — Test IP Connectivity
At this point, we can have some confidence that the settings on the computer itself are at least sane. It’s now time to start probing the network the computer is connected to.
The ping command allows us to test connectivity to a specified IP address.
This command is ubiquitous across OSes and even exists on Windows, though there are some subtle differences in the commands' behaviour across the different OSes.
ping uses the Internet Control Message Protocol (ICMP).
This is a protocol that sits in Layer 2 next to IP and is used for network diagnostics rather than information transport.
ping works by sending an ICMP echo request packet to the target IP and waiting for an ICMP echo response packet back.
According to the RFCs (Requests for Comment), all TCP/IP stacks should respond to ICMP echo requests, but many do not.
Services like Steve Gibson’s Shields Up even go so far as to actively discourage obeying the RFCs.
Personally, I think it’s reasonable for home routers not to reply to pings, but world-facing servers should be good netizens and obey the RFCs.
(Windows Server also blocks ICMP requests by default, which is very annoying when trying to monitor your own network’s health!)
To use the ping command simply pass it the IP address to be pinged as an argument.
On OS X, Unix and Linux, ping will default to continuously sending pings until the user interrupts the process, while on Windows ping defaults to sending exactly 4 pings and then stops.
To get the Windows version of ping to ping continuously use the -t flag.
If ping is running continuously, you stop it by pressing Ctrl+c.
That will stop new pings being sent, and ping will then print some summary information before exiting.
To avoid having to hit Ctrl+c, while still getting a good sample size, the -c flag can be used to specify the desired number of pings to send.
10 is a sensible value to choose.
To start to probe our connectivity we should first try ping the default gateway we discovered in the previous step.
The example below shows my output, pinging my default gateway 192.168.10.1.
bart-iMac2013:~ bart$ ping -c 10 192.168.10.1
PING 192.168.10.1 (192.168.10.1): 56 data bytes
64 bytes from 192.168.10.1: icmp_seq=0 ttl=64 time=0.378 ms
64 bytes from 192.168.10.1: icmp_seq=1 ttl=64 time=0.365 ms
64 bytes from 192.168.10.1: icmp_seq=2 ttl=64 time=0.398 ms
64 bytes from 192.168.10.1: icmp_seq=3 ttl=64 time=0.383 ms
64 bytes from 192.168.10.1: icmp_seq=4 ttl=64 time=0.409 ms
64 bytes from 192.168.10.1: icmp_seq=5 ttl=64 time=0.363 ms
64 bytes from 192.168.10.1: icmp_seq=6 ttl=64 time=0.273 ms
64 bytes from 192.168.10.1: icmp_seq=7 ttl=64 time=0.396 ms
64 bytes from 192.168.10.1: icmp_seq=8 ttl=64 time=0.265 ms
64 bytes from 192.168.10.1: icmp_seq=9 ttl=64 time=0.385 ms
--- 192.168.10.1 ping statistics ---
10 packets transmitted, 10 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 0.265/0.362/0.409/0.048 ms
bart-iMac2013:~ bart$If all is well on the local network (LAN), then there should be 0% packet loss reported by ping.
You would also expect the round trip times to be very small.
The round trip times should also be reasonably similar to each other — at the very least of the same order of magnitude.
If there is little or no packet loss, we need to probe further for the source of the problems.
To do this we need to ping an IP address that is outside of the LAN.
If you happen to know your ISP’s router’s address you could try ping that, but realistically people won’t know that kind of thing, and many ISPs configure their routers not to respond to pings.
What you can do instead is ping any IP out on the internet that you know exists, and that you know answers pings.
I tend to use Google’s public DNS resolver for the simple reason that I know it’s very likely to be up, that it answers pings, and that it has a very memorable IP address — 8.8.8.8.
Below is a sample of the output I get when I ping Google’s public DNS resolver:
bart-iMac2013:~ bart$ ping -c 10 8.8.8.8
PING 8.8.8.8 (8.8.8.8): 56 data bytes
64 bytes from 8.8.8.8: icmp_seq=0 ttl=56 time=30.380 ms
64 bytes from 8.8.8.8: icmp_seq=1 ttl=56 time=18.387 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=56 time=18.423 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=56 time=13.232 ms
64 bytes from 8.8.8.8: icmp_seq=4 ttl=56 time=11.189 ms
64 bytes from 8.8.8.8: icmp_seq=5 ttl=56 time=13.054 ms
64 bytes from 8.8.8.8: icmp_seq=6 ttl=56 time=17.855 ms
64 bytes from 8.8.8.8: icmp_seq=7 ttl=56 time=12.875 ms
64 bytes from 8.8.8.8: icmp_seq=8 ttl=56 time=22.634 ms
64 bytes from 8.8.8.8: icmp_seq=9 ttl=56 time=34.798 ms
--- 8.8.8.8 ping statistics ---
10 packets transmitted, 10 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 11.189/19.283/34.798/7.488 ms
bart-iMac2013:~ bart$Notice that the round trip times are much longer now — tens of milliseconds. If you have a slower internet connection the times could even rise to hundreds of milliseconds. What is important though is that they are all similar. If there are massive fluctuations in response times that suggests that your ISP is having capacity issues and that your internet connection is unstable.
If there is ping connectivity all the way out to Google, then you know you have a working internet connection.
Expected Result
Both the default gateway and the IP address on the internet reply to the pings, and have 0% packet loss.
Any packet loss at all when pinging your default gateway is a bad sign. It is indicative of an unhealthy LAN or at the very least an unhealthy connection between the computer being tested and the core of the LAN.
If your ISP’s network is healthy, packet loss out to Google should be zero too, but if your ISP’s network is a little congested, you might see the odd dropped packet creep in. Losing the occasional packet is tolerable, especially at peak times, but it does suggest that your ISP’s network is under stress, or that your connection to your ISP is perhaps a little lossy.
If your default gateway reports expected results, but the public IP address doesn’t, that implies there is a problem somewhere between your default gateway and the public IP address you were pinging. It could be that the server hosting the public IP is down, and everything else is OK, but if you use a big server like Google’s DNS resolver for your test, that would be extremely unlikely. The most likely scenario would be that your ISP is having a problem.
If you have a simple setup with just one home router, it’s probably safe to call your ISP as soon as a ping to an outside IP fails, but if you have a more complex setup, you might want to do a little more investigation before making that call. After all, it would be embarrassing to phone your ISP only to find that the problem is actually somewhere within your own setup!
You can use the traceroute command to attempt to clarify the location of the problem.
The traceroute command streams out a series of packets with different TTLs (Time To Live specified not in time but in hops between IP routers).
Every TCP/IP stack that interacts with a traceroute packet at an IP level should decrement the TTL by one before passing the packet on to the next router along the packet’s route to the destination being tested.
If a TCP/IP stack gets a traceroute packet and there is no TTL left, it should reply to the originator informing it of where the packet got to within its TTL.
By piecing together the information contained in all the returned packets for each TTL it’s possible to see how packets between the source and destination IPs traverse the internet.
Because this protocol uses many packets, you are not seeing the journey any one packet took, but the average journey of all the packets.
Note that not all routers respond to traceroute packets, so there may be no information for some TTLs, in which case that network hop is shown with just stars in `traceroute’`s output.
The traceroute command is available in Windows, Linux, Unix and OS X, but there is one caveat, it’s spelt differently on Windows!
To trace your route to Google’s public DNS resolver you would issue the following command on OS X, Linux or Unix:
traceroute 8.8.8.8On Windows the command would be:
tracert 8.8.8.8On my home network, I have two routers — one provided by my ISP which doesn’t give me the level of control or security I want, and my own router which does.
I can see both of these internal hops when I traceroute to Googles DNS resolver.
The command issued and the two internal hops are highlighted in the sample output below:
bart-iMac2013:~ bart$ traceroute 8.8.8.8
traceroute to 8.8.8.8 (8.8.8.8), 64 hops max, 52 byte packets
1 bw-pfsense (192.168.10.1) 0.482 ms 0.339 ms 0.251 ms
2 192.168.192.1 (192.168.192.1) 0.822 ms 0.927 ms 0.911 ms
3 * * *
4 * * *
5 109.255.250.254 (109.255.250.254) 15.475 ms 12.704 ms 10.010 ms
6 84.116.238.62 (84.116.238.62) 15.239 ms 12.699 ms 11.892 ms
7 213.46.165.54 (213.46.165.54) 20.095 ms 14.596 ms 14.963 ms
8 66.249.95.135 (66.249.95.135) 13.044 ms 17.823 ms 16.784 ms
9 google-public-dns-a.google.com (8.8.8.8) 13.102 ms 27.005 ms 14.958 ms
bart-iMac2013:~ bart$If the home router provided by my ISP were to be down I would expect the trace to get stuck after it hits my main router (bw-pfsense). If that hop showed up, but then the trace went dark, then I would know that all equipment within my house is working fine, but that nothing is getting out onto the internet from my house, implicating my ISP.
Possible Problems/Solutions
-
If there is not even connectivity as far as the default gateway then either the network settings are wrong, or there is a hardware problem with the LAN
-
If there is packet loss when pinging the default gateway, then either there is congestion on the LAN, or there is a hardware problem — perhaps a faulty switch/router or perhaps a faulty network card. If using Ethernet it could also be a damaged Ethernet cable, and if using WiFi it could be low signal strength, congestion of the channel because too many of your neighbours are using the same channel, or RF interference of some kind.
-
If the ping to the public IP does not respond at all then either the server you are pinging is down, or, more likely, your connection to the internet is down.
traceroutemay help you prove it really is your ISP that is the problem before you spend an eternity on hold with them!
Step 4 — Check Name Resolution
Almost everything we do online involves domain names rather than IP addresses, so if a computer has lost the ability to convert domain names to IP addresses it will appear to have lost its internet connection even if it has full IP-level connectivity.
To test name resolution simply try to resolve a known-good domain name like google.com:
host google.comIf name resolution is working you should see output something like:
bart-iMac2013:~ bart$ host google.com
google.com has address 74.125.24.113
google.com has address 74.125.24.100
google.com has address 74.125.24.101
google.com has address 74.125.24.139
google.com has address 74.125.24.138
google.com has address 74.125.24.102
google.com has IPv6 address 2a00:1450:400b:c02::71
google.com mail is handled by 10 aspmx.l.google.com.
google.com mail is handled by 40 alt3.aspmx.l.google.com.
google.com mail is handled by 20 alt1.aspmx.l.google.com.
google.com mail is handled by 50 alt4.aspmx.l.google.com.
google.com mail is handled by 30 alt2.aspmx.l.google.com.
bart-iMac2013:~ bart$The actual details returned could vary depending on where and when you run the command; what matters is that you get back a list of IPs.
If that fails, check that DNS resolvers have been configured on the computer by running:
cat /etc/resolv.conf | egrep '^nameserver'If all is well there should be at least one line returned.
The example below shows that my Mac is configured to use one DNS resolver, 192.168.10.1:
bart-iMac2013:~ bart$ cat /etc/resolv.conf | egrep '^nameserver'
nameserver 192.168.10.1
bart-iMac2013:~ bart$It is also worth testing whether or not Google’s public DNS resolver will work from the given computer:
dig +short google.com @8.8.8.8If you can resolve names using Google’s public resolver you should see output something like:
bart-iMac2013:~ bart$ dig +short google.com @8.8.8.8
74.125.138.100
74.125.138.113
74.125.138.138
74.125.138.102
74.125.138.139
74.125.138.101
bart-iMac2013:~ bart$The actual IPs returned could well be different depending on where and when you run the command; the important thing is that a list of IPs is returned.
Expected Result
The test name resolves to one or more IP addresses without error.
Possible Problems/Solutions
-
If there are no resolvers listed in
/etc/resolve.conf, then ideally the user’s home router should be checked to make sure DNS is properly configured there because DNS settings should be passed down to the computer via DHCP. -
Only if the problem can’t be addressed on the router does it make sense to try to fix it on the computer itself by hard-coding it to use a particular resolver in the Network System Preference Pane.
Conclusions
When a family member, colleague, or friend comes to you with a vague problem statement like “the internet is down”, it’s very hard to know where to begin. By starting at the bottom of the stack and working your way up methodically you should be able to discover the point at which things break down, and hence know where to focus your efforts at fixing the problem. The methodology described here does not tell you exactly what to do in any given situation because the variability is infinite, but it should help you focus your efforts where they are needed.
Up until now, the networking segment of this series has focused on how the internet works. We’ve looked in detail at the protocols that could best be described as the infrastructure of the internet. The series is now going to shift focus away from the infrastructure itself, and onto some uses of that infrastructure.
The next few instalments are going to focus on a very powerful Layer 4 protocol that allows for secure communication between two computers — the Secure Shell Protocol, better known as SSH.
TTT Part 29 of n — Intro to SSH
In the previous six instalments, we looked in detail at how TCP/IP networks tick. In these instalments we worked our way up from the bottom of the four-layer TCP/IP network model to the top, finishing off with a look at two protocols in the Application Layer at the top of the stack. Those two protocols, DHCP & DNS exist in the top layer but are different to most other top-layer protocols in that they can reasonably be described as forming part of the infrastructure of the internet. The email and web protocols may sit within the same network layer, but they still rely on DNS to function.
For the remainder of the networking section in this series we’re moving away from infrastructure-like protocols, and focusing on the user-facing Application Layer protocols. The first of these we’ll be looking at is the Secure Shell or SSH. This protocol is one of the absolute workhorses of the internet, and a vital tool for all Linux, Unix, and OS X sysadmins.
At it’s simplest level SSH allows you to execute commands on a remote computer, but because it was designed around the concept of a secure tunnel between two systems, SSH has expanded to allow all kinds of advanced features. The least-generous description of this could be that SSH has become a kind of sysadmin’s fridgeoven. But I don’t buy that, I prefer the alternative interpretation — it simply makes sense not to reinvent the wheel, and to allow as much information as possible to flow throw the secure connection SSH provides between the two endpoints.
Today we’re just going to start with the basics, but in future instalments, we’ll move on to the more advanced features.
Listen Along: Taming the Terminal Podcast Episode 29
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Introducing SSH
The SSH protocol allows one computer running an SSH client to securely connect to another running an SSH server. In other words, SSH is a client-server protocol. The computer initiating the connection is referred to as the client, and the computer being connected to as the server.
SSH operates over TCP, and while SSH servers can listen on any TCP port, by default SSH servers listen on port 22. As its name suggests, security is integral to the Secure Shell, and all SSH traffic is encrypted by default.
SSH is often described as the secure replacement for the older insecure Telnet protocol. It’s certainly true that SSH provides a secure replacement for Telnet, but it’s much more than that, providing additional features Telnet never did.
The first version of SSH dates back to 1995, which sounds old in IT terms, but bear in mind that Telnet dates back to 1968! The first version of the SSH protocol had some security shortcomings, so a new version of the protocol, SSH 2, was released in 2006, and this is what we use today.
Some Preliminaries
To play along with this segment you’ll need two computers with SSH installed the SSH service enabled on at least one of those computers, and TCP/IP network connectivity between them. The two computers can be a mix of OS X, Linux, and Unix.
OS X comes with SSH installed by default, but remote logins over SSH are disabled by default, i.e. the SSH service is not running by default. This means that a Mac can always act as an SSH client, but can only act as an SSH server when it has been configured to do so.
To enable the SSH service on a Mac, open the Sharing preference pane and enable the ‘Remote Login’ option. This interface will allow you to limit SSH access to just some of the user accounts on your Mac, or to allow all users to connect to your Mac over SSH.
Linux machines usually have SSH installed and enabled by default. Instructions for installation and activation vary from one Linux distribution to the next, so I’ll have to leave it as an exercise for the reader to find instructions for specific Linux distros as needed.
With SSH installed and enabled on two computers, pick one to be the client, and one the server, i.e.
one to connect from, and one to connect to.
You’ll need to know the IP address (or DNS name) of the one you choose to act as the server.
In the examples below I’ll be connecting to my file server, a Linux server on my LAN with the private IP address 192.168.10.20.
Using SSH to Run a Command on Another Computer
The simplest thing you can do with SSH is use to it to execute a single command on a remote computer. This can be done using the SSH command in the following way:
ssh username@remote_computer 'command'For example, the following command returns a list of all running processes on my file server:
ssh bart@192.168.10.20 'ps -ef'Note that when you are asked for a password, you should enter the password for the remote user, not your password on the local computer.
Note that if your username is the same on the machine you are SSHing from and the one your are SSHing to, you can leave out the username, so since I log in to both computers as the user bart, I could simplify the above command to:
ssh 192.168.10.20 'ps -ef'SSH Security
If you’ve never used SSH before on a computer, the chances are very high that when you tried to play along with the previous section you encountered a strange notification that may have looked like an error, asking you to enter yes or no.
It probably looked something like:
The authenticity of host '192.168.10.20 (192.168.10.20)' can't be established.
RSA key fingerprint is 29:b0:59:4f:ef:2e:6d:ee:81:97:40:04:aa:03:f7:66.
Are you sure you want to continue connecting (yes/no)?Firstly, it’s safe to hit yes if you are connecting to a server for the first time.
It’s still important that we understand what the message meant, and why it’s OK to say yes on your first connection to a server.
When SSHing to a remote computer, your computer tries its best to authenticate the remote computer in order to protect you from man-in-the-middle attacks.
Web servers solve this problem using Certificates signed by Certificate Authorities and validated by trust anchors installed in our computers. If SSH had been designed the same way, we would need to apply for a certificate for each computer we wanted to SSH to. This would create a major barrier to the adoption of SSH, so thankfully the SSH protocol solves the man-in-the-middle problem in a very different way. The solution SSH has chosen works without the need for any central authorities like the Certificate Authorities that underpin security on the web, but the price we pay for that convenience is that we have to deal with prompts like the one above. Because there are no central authorities to rely on, the end-user has to take responsibility for their own security.
When the SSH service is installed on a computer, a random asymmetric key-pair is generated. One half of that pair is designated the server’s private key, and the other the server’s public key.
The first time a client connects to a server via SSH, the client saves the server’s public key in a special file, along with the server’s IP address and DNS name (if the client connected by DNS name rather than IP).
When the client re-connects with a server on an IP address or at a DNS name it has saved details for, it uses the saved public key to validate the server. A man-in-the-middle will not have the server’s private key, and so will not be able to pass the client’s security check.
Once you understand this process, the message you get when you first connect to a server makes more sense. You are being asked if you want to trust a server for which there is no saved public key, and hence whose identity cannot be confirmed. When you say yes a second message will pop up, telling you the key has been saved, it will look something like:
Warning: Permanently added '192.168.10.20' (RSA) to the list of known hosts.On future connections to the server, you should not see any more messages, because the key will be saved, and the server should pass validation by the client.
The database of public keys is stored in a plain text file, ~/.ssh/known_hosts, one entry per line.
You can view the content of this file with the command:
cat ~/.ssh/known_hostsIf for some reason the server validation fails, you’ll see an error message something like:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
Someone could be eavesdropping on you right now (man-in-the-middle attack)!
It is also possible that a host key has just been changed.
The fingerprint for the RSA key sent by the remote host is
29:b0:59:4f:ef:2e:6d:ee:81:97:40:04:aa:03:f7:66.
Please contact your system administrator.
Add correct host key in /Users/bart/.ssh/known_hosts to get rid of this message.
Offending RSA key in /Users/bart/.ssh/known_hosts:14
RSA host key for 192.168.10.20 has changed and you have requested strict checking.
Host key verification failed.This could mean there is a man-in-the-middle attack in progress. But before you assume the worst, remember that there are legitimate reasons a server’s public and private keys could change.
Firstly, if you reinstall the OS on a computer, a new set of SSH keys will be generated, so the server will legitimately change identity.
Secondly, if you regularly connect to multiple servers on a network that has dynamically assigned IPs, then sooner or later you’ll get this error because you once saw one computer at this IP, and now a different one has randomly been assigned it. It’s largely to avoid problems like this that I like to set static DHCP leases for all my computers on my home network.
Once you have satisfied yourself that the warning message is innocent, the solution is to edit ~/.ssh/known_hosts with your favourite text editor and remove the line containing the old key.
Conveniently, the line number is given in the error message. It’s the number after the :, so in the example above, the offending key is on line 14, so that’s the line I need to delete.
Update: An alternative to manually editing the file is to use the ssh-keygen command to delete the offending key for you.
You do this using the -R flag (R for remove) to pass the IP or hostname who’s key you need to remove:
ssh-keygen -R computer_name_or_ipThanks to Twitter user @adrianluff for the tip!
Remote Command Shells
If you need to run more than one command on a remote computer, it’s more convenient to get a full remote command shell, which you can easily do by leaving off the final argument (the command to execute remotely). So, the general form would be:
ssh username@remote_computerAgain, the username can be omitted if it’s the same on both computers, so for, me I can get a remote shell on my file server with:
ssh 192.168.10.20Once you ssh to a remote computer in this way you get a full remote shell, so it really is as if you were typing in a terminal window on that computer.
As mentioned previously, SSH defaults to using TCP port 22, but, an SSH service can, in theory, be run on any port number.
Some hosting providers add a little extra security by running SSH on a non-standard port.
This will not protect from targeted attacks, but it will stop automated scans of the internet from finding your SSH server.
If the SSH server you are connecting to is not running on port 22, you need to use the -p flag to specify the port number, e.g.
if I were to move the SSH service on my file store to port 2222 the two example commands above would become:
ssh -p 2222 192.168.10.20 'ps -ef'
ssh -p 2222 192.168.10.20Conclusions
In this instalment, we’ve covered the basics of SSH. We can now use it to execute single commands on a remote computer and to get an interactive command shell on a remote computer. This is enough to replace the old insecure Telnet protocol with a secure alternative, and, enough to get by in most scenarios.
While what we’ve learned in this instalment is usually sufficient, there are advantages to learning about some of SSH’s more advanced features, which is what we’ll be doing in the next instalment.
TTT Part 30 of n — SSHing More Securely
In the previous instalment, we saw how we can use SSH to execute a single command on a remote computer, or, to get a command shell on a remote computer. We also saw how SSH uses host keys to protect us from man-in-the-middle (MITM) attacks.
In this instalment, we’re going to look at how we can improve both SSH security and convenience with SSH keys.
|
This instalment was initially written, and the matching podcast episode recorded, in October 2015. In February 2021 some sections of this instalment specific Mac OS X/macOS were updated to reflect significant changes in Apple’s handling of SSH keys. The most significant change Apple made is in the SSH Agent, which is described in TTT37, but Apple also added support for the The podcast episode for this instalment was not updated in February 2021, but the update to |
Listen Along: Taming the Terminal Podcast Episode 30
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
SSH keys utilise asymmetric encryption, specifically public/private key cryptography. It’s important to have a clear understanding of how this works before proceeding.
|
Asymmetric Encryption and Public & Private Keys — A Quick Summary
An Encryption algorithm turns unencrypted plain text into encrypted cypher text using some kind of key. The simplest type of encryption uses the same key to encrypt and decrypt and is known as symmetric encryption. With asymmetric encryption, there is not one key, but two, a so-called key-pair. Whatever is encrypted with one key can only be decrypted with the other. Either key can encrypt, but you can only decrypt with the one you didn’t use to encrypt. For public/private key cryptography we arbitrarily designate one of the keys in the key pair as the private key, and the other as the public key. We then make sure the private key is NEVER shared. The public key can be safely published anywhere without impacting security. If we give someone our public key, and they encrypt something with it, only we can decrypt it, because only we have our private key. This fact can be used as the basis for an authentication system because only the holder of the private key that matches a public key can decrypt a test message sent by someone with that public key. |
SSH Key Authentication
The SSH protocol has support for multiple different types of authentication. By default, one of the authentication mechanisms used by SSH is password authentication. SSH will allow you to connect to a given account on a computer if you know the password for that user on that computer. By default, SSH will also try to use an SSH key-pair for authentication instead of a password, and in fact, it will try to use a key-pair before it tries to use a password.
To use SSH key authentication you need to do the following:
-
Generate an SSH key-pair on the computer you will be SSHing from (you only have to do this once, you can use the same key-pair to authenticate to multiple computers safely).
-
Give the public key from that key-pair to the person managing the computer you want to SSH to (never share your private key with anyone!).
-
Wait for the administrator of the remote computer to add your public key to the list of allowed keys within the account you will be SSHing to.
Once those steps have been completed you will be able to log in to the remote computer without having to know the password of the user you will be connecting as.
Let’s look at these steps in detail now. To play along you’ll need two computers, one to SSH from, and one to SSH to.
Generating an SSH Key-Pair
| This section assumes you are using a Linux-like operating system (Linux, Unix, Mac, or the Windows Subsystem for Linux on Windows 10) and have not yet generated an SSH key-pair for the account you will be SSHing from, if you have, please skip on to the next section. |
Update — February 2020: I blogged Instructions for generating an SSH key-pair on Windows using PuTTYgen.
The process starts on the computer you will be SSHing from. You need to open a terminal as the user who will be SSHing to the remote computer, and in that terminal type the command:
ssh-keygen -t rsaThis will create an SSH key-pair and offer to store the two halves in the default locations (press enter to accept the defaults for the location):
-
The private key:
~/.ssh/id_rsa -
The public key:
~/.ssh/id_rsa.pub
If you already have a set of keys and don’t want to replace them, you can use the -f flag and specify a different location to save the private key (the public key will get stored in the same folder and with the same name, but with .pub appended to it).
When you run the ssh-keygen command you will be asked to enter a password.
This is the password that will secure the private key.
This is a very important safety measure because it means that if your private key is lost or stolen, it cannot be used unless the attacker also knows the matching password.
The ssh-keygen command will accept a blank password, but this is to be strongly discouraged because it leaves your private key unprotected.
It should also be noted that if you forget the password protecting your private key, you won’t be able to use that key-pair any more, and you’ll need to generate a fresh key-pair!
Once you enter a password ssh-keygen will generate a public and private key, tell you where it has saved them, tell you the key’s fingerprint (a big long hexadecimal string separated with :s), and it will show you the key’s random art image.
This is a representation of the key as a little ASCII art graphic.
This is much more memorable to humans than the fingerprint. Show us two different pictures and we’ll spot the difference in seconds, show us two different strings of hex and we’ll find it very hard to spot subtle differences!
To get a sense of how difficult an SSH key is to brute force attack, you can have a look at the private key you just generated with the command:
cat ~/.ssh/id_rsaAnd the public key with the command:
cat ~/.ssh/id_rsa.pub|
Base64 Encoding
If you are wondering what format the keys are stored in, it’s the very commonly used base64 encoding. This is a very robust format that ignores characters like line breaks and spaces which could get introduced if a key were to be copied and pasted into an email or something like that. |
Granting Access With an SSH Public Key
The next step in the process is to share your public key with the person administering the computer you will be SSHing to. You can do this by attaching the public key to an email, or simply copying and pasting its content into an email. If we know the password of the remote account we will be connecting to, we can also copy the key over ourselves, but more on that later.
To grant a remote user access to a given account, a computer administrator needs to add the remote user’s public key to a special file in the home directory of the local user the remote user will be connecting as.
That special file is ~/.ssh/authorized_keys (or if the key is only to be used over the SSH2 protocol, ~/.ssh/authorized_keys2).
The ~/.ssh/authorized_keys file should contain one public key per line.
You can grant access to as many users as you like by adding as many public keys are you like.
SSH is an absolute stickler about the permissions on the authorized_keys file, including the permissions on the folder that contains it, i.e.
~/.ssh/.
No one other than the owner of the account (and root) should have write permissions to either the containing folder or the file itself.
Because public keys are not sensitive information, SSH does not care if other users can read what is effectively public information, but the ability to write to that file would allow any other user on the system to grant themselves access to that account by adding their own public key to the list.
To prevent this from happening, SSH will not accept a key if it’s contained in a file that is writeable by anyone but the owner of the account.
An example of working permissions on an account with the username bart is shown below:
1
2
3
4
5
6
7
[bart@www ~]$ ls -al ~/.ssh
total 20
drwx------ 2 bart bart 4096 May 5 2014 .
drwxr-xr-x 16 bart bart 4096 Mar 15 14:32 ..
-rw-r--r-- 1 bart bart 670 Feb 14 2013 authorized_keys
-rw-r--r-- 1 bart bart 660 May 5 2014 known_hosts
[bart@www ~]$
Remember that in a list of the contents of the folder ~/.ssh, the permissions on that folder itself are the permissions on the special file ..
I have highlighted the command, and the two important sets of permissions highlighted.
Simplifying the Process with ssh-copy-id
Update — February 2021: this section has been updated to reflect changes in macOS as opposed to Mac OS X.
It takes time and effort to manually copy across your public key and to make sure all the file permissions are correct.
Assuming you know the password to log in to the remote computer, you can automate the process with the ssh-copy-id utility.
This utility comes as standard on all the Linux distributions I have used, and on modern versions of the macOS.
|
Installing
ssh-copy-id on Mac OS X 10.11 El Capitan and OlderWhen Apple re-named Mac OS X to macOS they updated the version of Open SSH included with the OS to one that includes the |
Whatever OS you are on, once you have ssh-copy-id installed, copying over your public key becomes as easy as running the command below (replacing user and computer as appropriate):
ssh-copy-id user@computerSSHing to a Computer Using Key Authentication
Once you have generated your key-pair, and the remote admin has correctly added your public key to the authorized_keys file, you are ready to start using your private key as your authentication when SSHing to that remote computer.
If you saved your key to the default location (~/.ssh/id_rsa), then you don’t have to do anything special to start using your key, just issue your SSH command as normal.
Remember, by default, SSH tries key-based authentication before password-based authentication.
If your private key is not in the default location you need to tell SSH what key to use with the -i flag (i for identity).
Assuming you followed best-practice advice and protected your private key with a password, you will be asked for a password when you try to SSH, but you are not being asked for the password of the remote account you are connecting to, instead, you are being asked for the key to unlock your private key.
Securely Saving Your Private Key’s Password
I promised convenience AND security, but surely swapping one password for another is no more convenient?
The good news is that there are mechanisms for safely caching that password so you don’t have to keep entering it each time you SSH. The exact details of the mechanism vary from OS to OS.
Update — February 2021: this section has been updated to reflect changes in macOS as opposed to Mac OS X.
The version of SSH that ships with Apple’s macOS (formerly Mac OS X)has support for Apple’s secure keychain. This is a secure vault the Mac uses to store the passwords you save in all sorts of apps, including Mail.app and Safari. It’s possible to securely store your SSH Key passphrases in Apple’s Keychain, and once you do, you can use your key without entering your passphrase each time you use it.
On older versions of Apple’s operating system the integration with the Keychain was integrated into the Mac GUI and enabled by default. When you used an SSH key a popup window would appearing asking for your password and offering to save it to your Keychain. If you ticked the box to same the password, you could then log in with out entering your password in future. This was extremely convenient, but very much non-standard behaviour.
Starting with macOS Sierra, Apple removed their custom UI, and switched to an integration more in keeping with how SSH keys are managed on other OSes.
Regardless of whether you’re using macOS or Linux, you now need to use the SSH Agent to manage your SSH keys. This agent is discussed in detail in TTT37.
Advantages to Key-based Authentication
-
Convenience — with
ssh-agentsecurely storing the password for your private key, you can safely use SSH without having to enter a password. -
Security — once you have key-based authentication in place, you can either set a really long and secure password on the remote account or even disable password-based logins completely (we don’t cover how to do that in this series). SSH keys are much more difficult to brute force than even the most complex of passwords.
-
A Form of 2-Factor Auth — in order to log in as you, an attacker needs to have your private key and needs to know the password for your private key. Some argue that this is only 1.5-factor auth because unlike a physical dongle, you have no real way of knowing if someone has stolen a copy of your private key. Since it is digital, a copy can be taken without depriving you of your copy, and hence alerting you to its loss.
One place where key-based auth really comes into its own is with shared accounts.
Imagine you are working on a website together with some volunteers from a club you are a member of. The server hosting your site allows logins over SSH. All those working on the project need to be able to log into the webserver to edit the site. Being a club, there is going to be a natural churn of members, so people will continually join and leave the project, and it’s possible that some of the leavers will not be leaving on good terms. How do you handle this situation?
First, let’s look at the simplest and perhaps most obvious solution — a shared password. You set a password on the account, and share that password with the group. Then, each time a new member starts, you let them in on the secret. So far so good. Then, someone leaves the project. You now have to either accept the fact that someone no longer working on the project still knows the shared secret, and hence can still log in and perhaps sabotage the site, or, you need to change the password and tell only the remaining people the new password. That scheme is workable but cumbersome.
A better solution would be to give no one the password to the account at all and use SSH keys instead.
On joining the project, each participant provides their SSH public key, and those keys are added to the ~/.ssh/authorized_keys file.
As people come and go, simply add and remove their public keys.
When someone leaves, no one else has to change anything, and there is no shared secret.
Managing a long authorized_keys file does not have to be difficult for two reasons.
Firstly, ssh-keygen adds the username and hostname of the person whose key it is to the end of all public keys, so just reading the key could well tell you all you need to know to identify which key belongs to whom.
If that information is not sufficient, you can add comment lines to the file by staring those lines with the # symbol.
Conclusions
Usually, we have to choose between convenience and security, but with SSH keys we get to have our proverbial cake and eat it too. By putting in a little work up front, we get a more convenient and more secure SSH experience.
So far we have only looked at using SSH to execute terminal commands remotely, either one command at a time, or through an interactive command shell running on the remote computer. But, SSH’s encrypted connection can be used to secure much more than just a command shell. In fact, it can be used to secure just about any kind of network communication through a number of different mechanisms. In the next two instalments we’ll see how to securely transmit files over SSH, and, how to securely tunnel any network connection through an SSH connection.
TTT Part 31 of n — SSH File Transfers
In Part 29 of n, we learned how to use SSH to execute commands on a remote computer. In the previous instalment, we learned how to add security and convenience to SSH connections using SSH key-pairs.
The most important thing SSH provides is an encrypted connection between two computers. As we’ve seen, that encrypted connection can be used to securely issue terminal commands to a remote computer, but that same secured channel can also be used to secure other network connections between computers. In this instalment, we’ll look at three different ways of securely copying files between computers through an SSH connection, and in the next instalment, we’ll look at tunnelling just about any network connection through an SSH connection.
Listen Along: Taming the Terminal Podcast Episode 31
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Examples Prep.
|
Commands to Save RSA Key Passphrase to Apple Keychain
In later versions of OSX (macOS Sierra and higher), you will not get the popup offering to save your passphrase to Apple Keychain. See TTT37 under "SSH Agent on OS X & macOS" for the new method to store your passphrase in Keychain. |
Before we get tucked in, just a reminder that in order to play along with the examples, you’ll need two computers with SSH installed, one you can SSH from, and one you can SSH to. Throughout the examples, I’ll refer to the computer you are SSHing from as the local computer and the one you are SSHing to as the remote computer.
It should also be noted that if you have not set up SSH keys as described in the previous instalment, you’ll be entering your password a lot as you work through these examples!
Before getting started we need to create some dummy files to copy between the two computers.
To make things as simple as possible, we’re going to place our temporary files in a location that exists on all POSIX OSes where all users have read and write access — the temporary folder, /tmp.
We’ll use SSH to create the remote files.
In order to make the commands easier to copy and paste, we’re going to use shell variables to store the username to SSH as, and the computer to SSH to.
You’ll need to replace my_remote_username with your username on the remote computer, and my_remote_computer with the IP address or DNS name of the remote computer in the variable definitions below.
SSH_USER=my_remote_username
SSH_COMP=my_remote_computerCreate the Local Dummy Files
mkdir -p /tmp/ttt31/fromRemote
echo "Hello World! (Local Text File 1)" > /tmp/ttt31/scp_local1.txt
echo "#Hello World! (Local Markdown File 1)" > /tmp/ttt31/scp_local1.md
echo "#Hello World! (Local Markdown File 2)" > /tmp/ttt31/scp_local2.mdAs we move files around, you can monitor the content of the local folder, and its sub-folders, with the command:
ls -R /tmp/ttt31/Create the Remote Dummy Files
1
2
3
4
5
6
7
8
ssh $SSH_USER@$SSH_COMP 'mkdir -p /tmp/ttt31/fromLocal'
ssh $SSH_USER@$SSH_COMP 'echo "Hello World! (Remote Text File)" > /tmp/ttt31/scp_remote.txt'
ssh $SSH_USER@$SSH_COMP 'mkdir /tmp/ttt31/scp_folder'
ssh $SSH_USER@$SSH_COMP 'echo "Hello World! (Remote Text File 1)" > /tmp/ttt31/scp_folder/file1.txt'
ssh $SSH_USER@$SSH_COMP 'echo "Hello World! (Remote Text File 2)" > /tmp/ttt31/scp_folder/file2.txt'
ssh $SSH_USER@$SSH_COMP 'mkdir /tmp/ttt31/rsync_folder'
ssh $SSH_USER@$SSH_COMP 'echo "Hello World! (Remote Text File 1)" > /tmp/ttt31/rsync_folder/file1.txt'
ssh $SSH_USER@$SSH_COMP 'echo "Hello World! (Remote Text File 2)" > /tmp/ttt31/rsync_folder/file2.txt'
As we move files around, you can monitor the content of the remote folder, and its sub-folders, with the command:
ssh $SSH_USER@$SSH_COMP 'ls -R /tmp/ttt31/'Tidying Up
If you want to start over at any stage or to clean up after yourself when finished, the following commands will remove the local and remote dummy files:
rm -rf /tmp/ttt31
ssh $SSH_USER@$SSH_COMP 'rm -rf /tmp/ttt31'scp — The Secure Copy Command
The simplest way to securely copy files between computers is with the secure copy command, scp.
As its name would suggest, it is very like the regular POSIX copy command, cp, but with the added ability to copy files between computers.
The basic syntax is the same as that for the copy command:
scp source_file_1 [source_file_2 ...] destinationYou can specify one or more source files, and a destination to copy them to.
The big difference is that with scp, both the source and destination can be on another computer.
If you want to specify a remote file path as source or destination, simply prefix the path with user@computer:.
Because the scp command uses SSH to connect to remote computers, it can use SSH key-pairs, so if you have them configured as described in the previous instalment, you can copy files between computers without needing to enter a password.
As a first example, let’s copy the remote file /tmp/ttt31/scp_remote.txt to the local folder /tmp/ttt31/fromRemote:
scp $SSH_USER@$SSH_COMP:/tmp/ttt31/scp_remote.txt /tmp/ttt31/fromRemote/You can verify that the remote file was downloaded with:
ls /tmp/ttt31/fromRemoteNext, let’s copy the local file /tmp/ttt31/scp_local1.txt to the remote folder /tmp/ttt31/fromLocal.
scp /tmp/ttt31/scp_local1.txt $SSH_USER@$SSH_COMP:/tmp/ttt31/fromLocal/You can verify that the file transferred over with the command:
ssh $SSH_USER@$SSH_COMP 'ls /tmp/ttt31/fromLocal'We can specify as many source files as we like, and we can use wild card characters to specify multiple files at once.
As an example, let’s copy all MarkDown files in the local folder /tmp/ttt31/ to the remote folder /tmp/ttt31/fromLocal.
scp /tmp/ttt31/*.md $SSH_USER@$SSH_COMP:/tmp/ttt31/fromLocal/Again, you can verify that the files transferred over with the command:
ssh $SSH_USER@$SSH_COMP 'ls /tmp/ttt31/fromLocal'We’re not going to describe all the optional flags scp supports. You can read about those in the man page for scp.
However, I do want to mention that like cp, scp allows entire folders to be transferred using the -r flag (for recursive).
As an example, let’s copy the entire remote folder /tmp/ttt31/scp_folder to the local folder /tmp/ttt31/fromRemote/.
scp -r $SSH_USER@$SSH_COMP:/tmp/ttt31/scp_folder /tmp/ttt31/fromRemote/You can verify that the folder, and its contents, were downloaded with the command:
ls -R /tmp/ttt31/fromRemotersync over SSH
The rsync command allows one folder, and all its nested content, to be intelligently synchronised with another.
rsync will only copy files that are different between the source and the destination, so it’s a very powerful and efficient backup tool.
So powerful in fact, that many GUI backup tools are little more than GUIs for the rsync command.
The basic structure of the rsync command is shown below, but in practice, a number of flags are needed in order to use rsync as an effective backup tool.
rsync source_folder destination_folderIn order to create a good backup, I would advise always using a number of flags, so the command I suggest remembering is:
rsync -av --delete source_folder destination_folderThe -a flag puts rsync into archive mode, which is a synonym for backup mode.
In this mode, file permissions are preserved, and symlinks are copied as links, not replaced with the files they point to.
The -v flag puts rsync into verbose mode, which means it will print out each file it copies or deletes.
The scary looking --delete option tells rsync that it should remove any files at the destination that are not present at the source.
If this flag is not used, the destination will get ever bigger over time as files deleted at the source are left in place at the destination.
When specifying the source folder, whether or not you add a trailing / makes a really big difference to the behaviour of rsync.
If you leave off the trailing /, then a new folder with the same name as the source folder will be created in the destination folder.
If you add the trailing /, then the contents of the source folder will be copied to the destination folder.
I always use the trailing /, because I find that behaviour the most intuitive.
If you add the trailing / to the source, then rsync will make both the source and destination be the same.
So far, we have seen how rsync can synchronise two folders on the same computer, now let’s add SSH into the mix.
Historically, rsync used its own custom networking protocol, but that protocol is not secure.
Modern versions of rsync can use an external program to create the network connection across which it will transfer files.
This is done with the -e flag (for external program).
To transfer files over SSH, we need to use -e ssh.
Like scp, rsync allows either the source or destination (or both) to be specified as being remote by prefixing the path with user@computer:.
Like with scp, rsync over SSH can use SSH key-pairs to allow password-less synchronisation of folders across the network.
One caveat is that rsync has to be installed on both the local and remote computers for a synchronisation operation to succeed.
OS X comes with rsync installed by default, as do many Linux distros.
However, on some Linux distros, particularly the more minimalist ones, you may need to install rsync using the distro’s package manager.
This is true if you do a minimal install of CentOS for example.
As an example, let’s use rsync to back up the contents of the remote folder /tmp/ttt31/rsync_folder to the local folder /tmp/ttt31/fromRemote/rsync_backup.
Using rsync to pull a backup from a remote computer is a very common use-case.
For example, every night at 4 am my Linux file server at home reaches out to the web server that hosts all my websites to do a full backup of my sites using rsync over SSH.
Running an rsync backup for the first time can be nerve-wracking, are you sure the right files will be copied/deleted etc.?
The -n flag is here to save your nerves!
When you issue an rsync command with the -n flag (I remember it as n for not really), rsync will print the changes it would make, but not actually do anything — think of it as a dry run.
Let’s start by running our example backup as a dry run, just to be sure we have everything correct.
rsync -avn --delete -e ssh $SSH_USER@$SSH_COMP:/tmp/ttt31/rsync_folder/ /tmp/ttt31/fromRemote/rsync_backupNote that because we want to backup the content of the folder rsync_folder, rather than the folder itself, a trailing / has been included in the source specification.
You’ll see from the output that a folder to hold the backup named rsync_backup would be created and that two files would be downloaded to that folder.
This is as expected, so we can now run the command for real by removing the -n flag:
rsync -av --delete -e ssh $SSH_USER@$SSH_COMP:/tmp/ttt31/rsync_folder/ /tmp/ttt31/fromRemote/rsync_backupYou can verify that the files have been downloaded with the command:
ls /tmp/ttt31/fromRemote/rsync_backupBecause we have not changed the remote files, if you re-run the command, nothing will be transferred. Try it!
Let’s give rsync some work to do by creating a third remote file:
ssh $SSH_USER@$SSH_COMP 'echo "Hello World! (Remote Text File 3)" > /tmp/ttt31/rsync_folder/file3.txt'Now, run the rsync command again, and you should see just this new file get downloaded.
You can verify that the file was downloaded by running the ls command again.
Finally, let’s edit one of the remote files, and delete another.
We’ll add some text to file1.txt, and delete file2.txt:
ssh $SSH_USER@$SSH_COMP 'echo "EDITED" >> /tmp/ttt31/rsync_folder/file1.txt'
ssh $SSH_USER@$SSH_COMP 'rm /tmp/ttt31/rsync_folder/file2.txt'With those changes made, run the rsync command again.
You should see file1.txt get downloaded again, and file2.txt get deleted.
You can verify that file1.txt was updated with:
cat /tmp/ttt31/fromRemote/rsync_backup/file1.txtAnd you can verify that file2.txt has been deleted from the local backup with:
ls /tmp/ttt31/fromRemote/rsync_backupSecure FTP
The final secure file transfer protocol we’ll be looking at is SFTP, which is basically the old insecure FTP protocol reimplemented to use SSH as the communication channel.
This protocol is mostly used by GUI apps like Panic’s Transmit rather than from the terminal.
This is because, unlike rsync and scp, this command does not immediately do anything, it simply gives you a new command shell in which to enter FTP commands.
If you know the source and destination paths, I would recommend using scp or rsync over SFTP when working in the terminal.
However, it can be useful if you need to explore the remote file system to find the file you want to transfer, or if you are already familiar with the FTP shell.
Like scp and rsync, SFTP can make use of SSH key-pairs to connect without the need to enter a password.
This is also true when using SFTP through most SFTP GUI apps.
Good GUI SFTP apps like Transmit will use SSH keys automatically, but some SFTP GUI apps make you manually specify that you wish to use a key, and/or specify the key to be used.
Transmit is the SFTP client I use each and every day, and I love it, but, they didn’t make it at all obvious that they have SSH key support. Users could be forgiven for not connecting the small key icon next to the password field with SSH key-pairs. If you hover over that icon you’ll see that Transmit uses keys in the default location automatically and that if you want to use a key in a different location, you need to click on the key icon to specify the path to the key file you’d like to use.
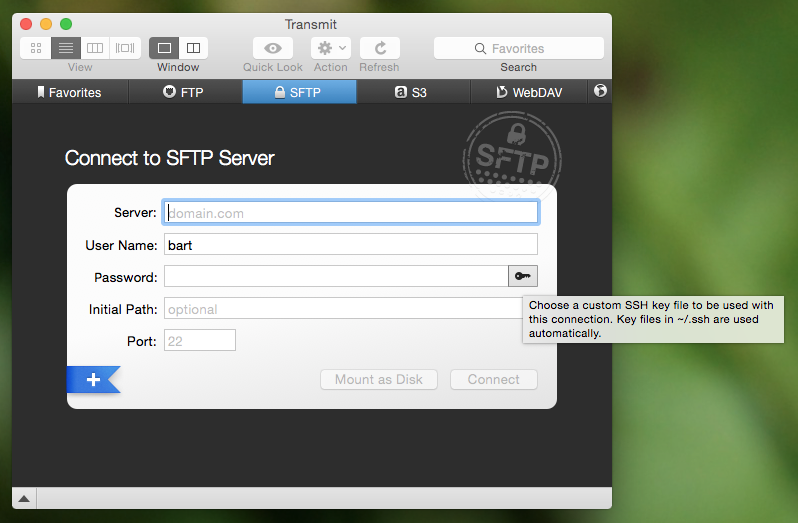
While the FTP shell is not difficult to use, I don’t think it is worth spending too much time on it in this series.
Personally, I never use it because I find that scp and rsync allow me to achieve my goals more easily.
But, I would like to give you a flavour of it, and you can then decide whether or not you’d like to learn more.
Let’s look at how to initiate an SFTP session, and some of the most important FTP commands.
You can connect to the remote computer with the command:
sftp user@computerIf you know the remote folder you want to copy files from, you can also specify that while connecting as follows:
sftp user@computer:remote_pathWhenever any command puts me into another shell, the first thing I want to know is how to get out!
With SFTP you have two choices, the traditional FTP command bye, or the more memorable command exit.
Within a Bash shell you are used to the concept of a present working directory, but in an (S)FTP shell that concept is extended to two present working directories, a present local working directory, and a present remote working directory.
The default local present working directory is the folder from which you issued the (S)FTP command, and the default remote present working directory is the home directory of the user you connected as.
You can see each of these two current paths with the commands lpwd (local present working directory) and pwd (remote present working directory).
You can change both of these paths at any time using the lcd (local change directory), and cd (remote change directory) commands.
You can also list the contents of both present working directories with the commands lls (local file listing), and ls (remote file listing).
Finally, there are the all-important commands for uploading and downloading files.
To download a file from the remote present working directory to the local present working directory, you use the get command, which takes one or more arguments, the names of the files to download.
Similarly, to upload a file from the local present working directory to the remote present working directory, you use the put command, which also takes file names as arguments.
Conclusions
We have now seen three different commands for securely copying files between computers via an SSH connection.
All three of these commands have different strengths and weaknesses and are the best-fit solution for different scenarios.
For example, backing up files that don’t change very often with scp would be very wasteful on bandwidth, and using an SFTP shell is a total waste of time if you know both source and destination paths, but, if you need to explore a remote filesystem to find a file to download, SFTP is the best fit.
There are a lot of similarities between the three commands.
All three of them can make use of SSH key-pairs, and all three of them use the same syntax for specifying a remote path, i.e.
user@computer:path.
So far we have learned to use SSH to execute terminal commands on remote computers and to securely transfer files between computers. In the next instalment, we’ll learn about three more SSH features, one that allows us to use SSH teleport GUIs between computers, and two to use SSH’s secure connection to protect any arbitrary insecure network connection.
P.S.
I backup up my own web server, a Linux server, over SSH each night. I use SSH to reach in and back up my MySQL Databases and Subversion source code repositories, then I use SCP to download those backups, and I use rsync over SSH to back up all the regular files that power all my websites.
Because this is a very generic thing to want to do, I have released the script I use as open source over on GitHub as backup.pl — you can read the documentation and download the script on the project’s GitHub page.
TTT Part 32 of n — SSH Tunnelling
This is the fourth SSH instalment. So far we’ve learned how to securely execute terminal commands on remote computers, how to securely copy files across the network using SSH, and how to add both security and convenience to both those operations with SSH key pairs.
As we saw in the previous instalment, SSH’s ability to provide a secure connection between two computers can be used in many different ways. In this instalment we’ll learn about three more ways to encapsulate other network traffic within an SSH connection, adding encryption to that traffic.
Running commands and copying files are the kinds of things most people do, so the three SSH instalments to date have been quite generally applicable. That is not the case for this instalment. The three SSH features we’ll be discussing are all very useful to those who need them, but only a minority will have a use for any one of these features. However, even if you don’t need these features today, I would argue that it’s good to know these features exist because they could well solve a problem you’ll have in the future.
There will be illustrations of the uses for these technologies, but not commands you type into your terminal to play along at home. That makes this an unusual instalment, but I hope you will still find it worthwhile.
Listen Along: Taming the Terminal Podcast Episode 32
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
X11 Forwarding
The Problem To Be Solved
SSH makes it easy to execute terminal commands on remote computers, but what about running GUI apps on remote computers? That’s the problem X11 forwarding solves.
Description
Linux and Unix OSes use a technology called The X Window System (more commonly known as X11) to render the GUI. OS X is different, Apple chose to use their own Quartz technology rather than X11. But, there is an officially sanctioned version of X11 for OS X called XQuartz, which allows X11 GUIs to be displayed on OS X. With XQuartz installed, X11 apps can run in a regular OS X window.
What X11 Forwarding allows you to do is have an app running on the remote computer but with the GUI rendered on your local computer. SSH effectively teleports the GUI across the network!
For this to work the remote computer must have X11 installed, the remotely running app must use X11 to render its GUI, and the local computer must have X11 installed.
This means that Macs with XQuartz installed can receive remote GUIs, but cannot be the source or remote GUIs unless there are X11 apps installed on the Mac (possible, but uncommon).
Instructions
To enable X11 forwarding on an SSH connection, use the -X flag.
This might result in an error that looks something like:
Warning: untrusted X11 forwarding setup failed: xauth key data not generatedIf you see the above error, also add the -Y flag (the two flags can be cuddled as -XY).
You don’t need an interactive shell to use X11 forwarding, for example, to run FireFox on a remote Linux computer but have the GUI show up on your local computer you would use a command of the form:
ssh -XY my_user@my_server 'firefox'An important caveat is that X11 forwarding is very bandwidth inefficient. It works very well over a local network but can be painfully slow across the internet.
Example Use Cases
-
Running GUI Control Panels — just about anything on Linux can be configured using a text file (probably in
/etc/somewhere), but sometimes it’s much easier to just run a little GUI tool to configure the setting you need. X11 forwarding makes it possible to do this on remote Linux servers. -
Accessing web interfaces that are restricted to local access Only — if you have a web interface that allows something sensitive to be configured, it’s good security practice to limit access to it to
localhostonly. This means it can only be accessed by a browser running on the computer itself. If you don’t have physical access that gets awkward unless you have X11 forwarding which will allow you to run a browser on the remote computer, but with the GUI forwarded to your local computer. Two common examples of this are the CUPS (Common Unix Printing System) printer sharing configuration interface (you’ll find it athttps://localhost:631if it’s configured), and the webmin server management interface.
SSH Port Forwarding
The Problem To Be Solved
Wrap encryption around an otherwise unencrypted network connection.
Description
SSH port forwarding allows you to map a local TCP port to a TCP port on a remote computer. Any traffic you send to the local port is sent through the SSH connection and then routed to its final destination after it comes out of the other end of the SSH connection.
While it is inside the SSH connection it is encrypted. Once it leaves the SSH connection on the other side it continues the rest of its journey unprotected.
This can be used in two ways:
-
To map a port on the computer you are SSHing to, to a port in your local computer. When used in this way the traffic is encrypted for its entire journey. This is the most secure way to use port forwarding.
-
To map a port on a third computer to a port on your local computer, with all traffic flowing through the computer you are SSHing to. In this scenario the traffic is encrypted between your computer and the computer you are SSHing to, but not for the remainder of the journey from the computer you are SSHing to onto the third computer. I would recommend against using port forwarding in this way if possible.
A crude analogy would be to think of SSH port forwarding as a single-port VPN.
Instructions
A single SSH connection can forward many ports.
For each port to be forwarded, an instance of the -L flag should be used in the following way:
-L[LOCAL_PORT]:[DESTINATION_HOST]:[DESTINATION_PORT]Example Use Case — MySQL
Many websites are powered by MySQL databases.
It’s common when working on a website to need access to the MySQL server powering your site from your local computer.
You can do this using the MySQL command-line tools, or, using a MySQL GUI.
The problem is that the MySQL protocol is insecure (at least by default, it is possible to configure it to use SSL, but that’s not straight forward).
Your username, password, and all the queries you issue and the server’s responses are all sent across the network unencrypted.
Because this is so dangerous, it’s common to limit MySQL to using the localhost IP address (127.0.0.1) or to firewall off access so that only computers within a secured network segment can access the server.
This is no good if you are working from home! SSH port forwarding can save the day, assuming you have SSH access to either the server running MySQL (or another server in the same network as the MySQL server that has been granted access to it.)
Assuming the most secure scenario, MySQL limited to 127.0.0.1 only, and SSH access to the server running MySQL, you would map the port with a command of the form:
ssh user@computer -L 3306:127.0.0.1:3306As long as that SSH connection is left open, port 3306 on your computer (the standard MySQL port) is mapped to port 3306 on the remote computer’s localhost IP. You now instruct your favourite MySQL client to connect to port 3306 on your local computer, and SSH then securely forwards that connection to the remote server for you, allowing you safe and secure access to MySQL.
This is such a common use case that many modern MySQL GUI clients allow you to configure this kind of port forwarding from within the GUI, removing the need to remember the terminal command. An example of a beautiful free MySQL GUI with SSH port forwarding support is Sequel Pro (OS X Only). I use SSH port forwarding with Sequel Pro each and every day!
Dynamic SSH Port Forwarding (SSH+SOCKS)
The Problem to be Solved
Regular SSH port forwarding requires that the local port, the destination IP and the destination port all be specified at the moment the SSH connection is created. This means it can only be used when all that information is known in advance and does not need to be changed while the connection is open.
This limitation makes it effectively impossible to route applications that make many network connections to many destinations, like a web browser, through regular SSH port forwarding.
Dynamic Port Forwarding makes it possible for any app that can use the standard SOCKS protocol to route traffic through an SSH connection. That includes apps like web browsers, chat clients, and email clients.
Description
Dynamic port forwarding is a relatively recent addition to SSH, and one of SSH’s little-known gems.
The SOCKS protocol can be used to proxy a TCP connection from any port to any port on behalf of any client that supports the protocol. It is normally used at the perimeter of corporate networks to regulate external internet access. All computers inside the corporation that need to make out-going network connections use the SOCKS proxy, which can then apply any rules to those connection requests the corporation desires. All network connections effectively get broken in two. The clients talk to the SOCKS proxy and the SOCKS proxy talks to the destination server.
When using SSH dynamic port forwarding, what happens is that a SOCKS server is started on your local computer, running on a port you specify, and it sends all the traffic it proxies through the SSH connection, and out onto the internet from the remote end of the SSH connection. While the traffic is encapsulated within the SSH connection it’s encrypted. Once it leaves the SSH connection it is unencrypted for the remainder of its journey.
This really is analogous to a VPN, with the caveat that only traffic sent to the locally running SOCKS proxy is secured.
The good news is that the SOCKS standard is very widely implemented. All the major browser can use SOCKS, and there is OS-level support for SOCKS in Windows and OS X.
The down-side over a real VPN is that you MUST be sure all apps are configured to use the SOCKS proxy before you start to use them, and you must remove the SOCKS configuration once the SSH connection is closed or all your apps will lose internet access.
Instructions
To instruct SSH to behave as a SOCKS proxy, use the -D flag.
The -D flag requires that the local port the SOCKS server should listen on be specified.
The default SOCKS port is 1080, so that’s a good choice.
To set up a SOCKS proxy on the default port use a command of the following form:
ssh -D 1080 user@computerExample Use Cases
-
Access local-only web servers on remote servers — if X11 forwarding is not a viable option for whatever reason, dynamic port forwarding can be used as an alternative to access local-only web interfaces like those for CUPS or webmin. Simply configure your locally running browser to use the SOCKS server provided by SSH, and then browse to the local URL (be sure the browser is not configured to bypass the proxy for local addresses).
-
Securely browse the web in coffee shops/hotels — if you set up an SSH server in your home, you can use SSH dynamic port forwarding to route all your browser traffic through an SSH connection to your home, safely getting you through the hostile coffee shop or hotel network.
-
Bypass geographic restrictions — some websites are only available from some countries. If you set up an SSH server in your home, you can use dynamic port forwarding to browse the web from anywhere and make it appear you are at home. This is a great way to keep up with your favourite sports ball matches while travelling. Assuming you have no moral objections to doing so, you could also rent a cheap virtual server in a country whose TV you like better than the TV in your own country, and use dynamic SSH port forwarding to watch streaming TV from that country from anywhere in the world.
Conclusions
We’ve almost covered everything about SSH that we will be covering in this series. We can now issue remote terminal commands, run remote GUI apps, transfer files, and tunnel TCP connections through SSH. All that remains now is for a few little tips to make your SSHing easier, which is what we’ll cover in the next, and final, SSH instalment.
TTT Part 33 of n — SSH 'Bookmarks'
This is the final SSH instalment. So far we’ve learned how to securely execute terminal commands on remote computers, how to securely copy files across the network using SSH, how to add both security and convenience to both those operations with SSH key pairs, and how to tunnel just about anything through SSH.
In this final instalment, we’ll look at two approaches for creating SSH bookmarks, SSH config files, and SSH GUIs.
Listen Along: Taming the Terminal Podcast Episode 33
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
SSH Config Files
Each time you issue an SSH command, SSH checks for the presence of a system-wide config file at /etc/ssh/ssh_config, and a user-specific config file at ~/.ssh/config.
If either or both of these files exist, they’ll be checked for a host definition matching the computer name specified in the command.
If both files exist and contain conflicting information, the user-level file takes precedence.
If the contents of either file conflicts with flags passed to the SSH command, the flags passed to the command will take precedence.
Config files can be used to set things like the port number, username, and even the hostname/IP address for a given computer name.
The syntax for SSH config files is very simple.
A file contains one or more host sections, and host sections contain one or more options.
You start a new host section by starting a line with the word Host followed by a space and the computer name you want the section to apply to.
You add the options for that host on the lines below, one option per line.
For readability, the options for each host are usually indented with 2 or 4 spaces or a tab.
You can add comment lines by starting them with the # symbol.
Option lines can be added in three forms:
Option_name Option_valueor
Option_name "Option value"or
Option_name=Option ValueThe first form can only be used if there are no spaces in the value for the options.
You can get a full list of all the supported options and values with the command:
man ssh_configHere is a short-list of some of the more commonly used options:
User-
Specify the username to use when connecting to the host.
Port-
Specify the port to use when connecting to the host. This option is equivalent to the
-pcommand-line option. HostName-
Specify the real hostname or IP to use when connecting to the computer name.
ForwardX11-
Specify whether or not X11 forwarding should be enabled. This option can only accept the values
yes, andno. Setting the value of this option toyesis equivalent to including the-Xcommand-line flag. ForwardX11Trusted-
This option can only accept the values
yes, andno. Setting the value of this option toyesis equivalent to including the-Ycommand-line flag. LocalForward-
Specify a local port to forward to a remote port when connecting to the host. This option takes two arguments (separated by a space), the local port number to forward, and the destination host and port number in the form
host:port. This option is equivalent to the-Lcommand-line option. DynamicForward-
Set up dynamic port forwarding (a SOCKS Proxy). The value must be a port number, and this option is equivalent to
-Dcommand-line option.
SSH config files are very often used to specify that all SSH-based connections to a given computer should go to a given non-standard port.
When using the SSH command itself you can specify the port number with the -p option, but you can’t always do that when using SSH via another command.
For example, rsync does not allow you to specify an SSH port number, so if you need to use rsync to connect to a computer with SSH running on a non-standard port, you must use an SSH config file.
E.g.
if the computer my-rsync-server.com has SSH listening on port 2222, you would use the following host declaration in an SSH config file to enable rsync connections over SSH:
Host my-rsync-server.com
Port 2222Even if you never find yourself in a situation where you must use an SSH config file, you might still find it worth the effort to set one up. You can use them to create what are effectively SSH bookmarks.
As an example, let’s say we regularly have to connect to the server this-is-a-really-long-name.com on port 2222 with the username rhododendron.
You could type the following each time you wanted to connect:
ssh rhododendron@this-is-a-really-long-name.com -p 2222Or, you could shorten that command to:
ssh myserverAll you would have to do to make your life that much easier would be to create the following host definition in your SSH config file:
Host myserver
HostName this-is-a-really-long-name.com
User rhododendron
Port 2222Notice how the HostName option allows us to give short nicknames to servers.
Finally, you can use wild cards when specifying a Host declaration.
* is interpreted at as ‘zero or more of any character’, and ? is interpreted as ‘exactly 1 character’.
This can be very useful if, for example, you have the same username on all servers for a given company (perhaps the one you work for). You could set SSH to use that username on all servers in the organisation’s domain with an entry like:
Host *.my-company.com
User my_usernameSSH GUIs
Whatever OS you happen to be using, you’ll have many SSH GUI clients to choose from. In general, they all provide the same basic functionality — they allow you to save SSH connection details so you can quickly and easily connect to the computers you regularly connect to. In effect, most of the GUIs are just graphical alternatives to SSH config files.
Rather than spend an eternity making an exhaustive list of all the SSH GUIs out there, I thought I’d simply recommend the ones I have found the most useful. Below are the three SSH GUIs I use regularly.
JellyfiSSH (OS X Only)
This little OS X app is available in the OS X App Store for just €3.49. It provides a small window containing your SSH bookmarks, and optionally a menubar dropdown with all your bookmarks. You use the app to open your saved SSH connections in new Terminal windows.
You can organise your bookmarks into categories, and you can set all sorts of settings for each bookmark. The app supports all the obvious stuff like hostname, username, and port number, but you can also set up the more advanced stuff like X11 forwarding and port forwarding, and you can customise the Terminal settings for each bookmark. This means that you can do clever things like creating a custom background image for each bookmark, or, set the background colour depending on the server’s role. I like to use red backgrounds for live servers for example, and green backgrounds for test servers.
The more energy you put into creating your bookmarks, the more use you’ll get out of the app. I find it well worth taking the time to create custom background images for each server so I can see at a glance what terminal window is connected to what server. My background images have the name of the server in big writing in the centre of the background image at 25% opacity and an icon for the OS the server is running in the top right corner.
Prompt 2 (iOS Only)
In my opinion the best SSH client for iOS is without doubt Prompt 2 from Panic. It’s a universal app, and costs just €4.99 in the iOS App Store.
The standard iOS keyboard is not very SSH-friendly, but with Prompt 2 that’s not a problem — the app’s UI provides quick and easy access to things like the control and tab keys, as well as special characters you’ll need often like |.
PuTTY (Windows)
I prefer to avoid using Windows desktops when possible, but when I have no choice but to use them, I use PuTTY for all my SSH needs.
The app is as old as the hills and has a website straight from the 1980s, but it works like a charm and is very popular.
The app is small, efficient, and easy to use, and it’s also free and open source.
PuTTY is a single stand-alone .exe file, so you don’t even have to install it, and you can run it straight from a thumb drive.
As well as just putty.exe, the SSH GUI, the same project also provides SCP (pscp.exe), SFTP (psftp.exe), and SSH Agent (pagent.exe) commands for Windows.
You can get all these Windows utilities from the PuTTY download page.
There are also versions of PuTTY for Unix and Linux.
Conclusions
With SSH keys for secure password-less authentication and either SSH config files or an SSH GUI app to bookmark the computers you connect to regularly, you should be able to have a nice easy SSH experience. You can now easily execute remote commands, and transfer files across the network securely.
Within the context of the larger networking section within this series, SSH is just one of the Application Layer protocols we’ll be looking at. In the next instalment, we’ll move on to look at terminal commands for interacting with HTTP(S), the protocol that powers the world wide web.
TTT Part 34 of n — Introducing HTTP
In the previous instalment, we finished a five-part series on SSH. Before moving on, let’s take a moment to step back and look at the big picture. The five SSH instalments are all part of the now long-running series on networking. We have been working our way through the networking stack since instalment 23. We started at the bottom of the stack, and have worked our way up. We are not exploring protocols in the Application Layer.
In this instalment, we’re moving on from SSH to HTTP, the protocol that powers the world wide web.
Before we look at some HTTP-related terminal commands, we need a basic understanding of how HTTP works, so that’s what this instalment is all about.
Listen Along: Taming the Terminal Podcast Episode 34
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Introducing HTTP
HTTP, the Hyper Text Transfer Protocol, is an application layer protocol that sits on top of TCP. By default, HTTP servers listen on TCP port 80. HTTP is a request-response protocol, where the clients (usually web browsers) formulate an HTTP request and send it to an HTTP server, which then interprets it and formulates an HTTP response which the client then processes. The HTTP protocol is plain-text and human-readable.
The HTTP protocol is most closely associated with web browsers, which use it to fetch web pages, but it’s used by other apps too. Another common example is podcatchers, which use HTTP to fetch the RSS feeds that define podcasts, as well as the media files those feeds link to. Many modern phone & tablet apps also use HTTP to communicate with the so-called cloud that powers them. HTTP is one of the real workhorses of the modern internet.
HTTP Requests
An HTTP request consists of between one and three sections. It always starts with a request line. This request line can be followed by zero or more request header lines, and finally, a data section may follow, separated from the headers by an empty line. The data section, should it be present, contains data entered into web forms, including file uploads.
The HTTP request line specifies the HTTP method to use, the path to request from the server, and the version of the HTTP protocol the remainder of the request will use.
The HTTP request headers are specified one per line, as name-value pairs, with the name separated from the value by a : character.
The headers are used by the client to pass information to the server which it can use in generating its response.
The following is an actual HTTP request for www.podfeet.com/blog/ as emitted by FireFox:
GET /blog/ HTTP/1.1
Host: www.podfeet.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:37.0) Gecko/20100101 Firefox/37.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en,en-US;q=0.7,ga;q=0.3
Accept-Encoding: gzip, deflate
Cookie: __utma=188241321.1236907656.1162169166.1408563404.1431184789.53; __qca=P0-1257128144-1331857305112; PHPSESSID=n7uq31arql1uao8g3rahchu743; __utmb=188241321.2.10.1431184789; __utmc=188241321; __utmz=188241321.1431184789.53.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmt=1
DNT: 1
Connection: keep-alive
Cache-Control: max-age=0The first line is the request line, which states that the HTTP GET method should be used, that the path /blog/ is being requested, and that the request is being made using version 1.1 of the HTTP protocol.
The remainder of the lines are request headers, there is no data included in this request. We won’t look at all the headers, but I do want to draw attention to a few notable ones.
The Host header is what makes it possible for multiple websites to be served from a single IP address.
The receiving web server will have many different domains configured, and this header will tell it which content is being requested.
The User-Agent header identifies the browser to the server and makes it possible to gather browser and OS usage stats.
Notice how you can tell from the above header that I was using FireFox 37 on OS X 10.10.
Notice that any cookies my browser has stored for the domain podfeet.com have been added to the request via the Cookie header.
Each HTTP request to a server is completely independent of all other requests.
There is no relationship between them, no concept of an extended connection or session.
This was a major shortcoming of HTTP, and cookies were added later to make it possible for multiple requests to be tied together.
When sending a reply to the client, the server can include a Set-Cookie header containing a string of text.
It is expected that the client will include this cookie in the request headers of all future requests to that same domain until the cookie expires.
The server can then tie together all the separate requests into a persistent state, making it possible to log in to websites.
Without cookies, there would have been no so-called web 2.0!
The Accept-Language header enables internationalisation of websites.
Servers can store multiple versions of the same site in different languages, and use this header to return the correct version to the user.
You might also notice that I have the Do Not Track (DNT) header set to 1, which means I am asking not to be tracked.
HTTP Methods
There are quite a few different HTTP methods, but there are only two in common use, GET and POST.
GET requests should be used when there is little or no form data to send to the server.
What little data there may be gets added to the end of the URL after a ? symbol.
GET requests should never be used to send sensitive data, as the data is included in the URL, and hence recorded in logs.
GET requests should be used to retrieve data, and should not be used to alter the internal state of a web app.
Because GET requests append their data to the end of the URL, and because there is a maximum allowed length for URLs, there is a limit to how much data can be sent using a GET request.
A big advantage to GET requests is that their URLs can be bookmarked and shared with others.
E.g., when I use Google to search for something, the text I type into the text box is sent to Google’s servers using a GET request.
I can see it in the URL of the search results.
I can then copy and paste that URL into an email to share that search with someone else.
POST requests should be used when there is a lot of data to send, or when the data is sensitive.
POST requests should be used for all request that changes the internal state of a web app, e.g.
to send an email in a webmail interface, add a post on a social media site, or change a password.
POST requests add the form data after the headers, so it is not logged and has no restrictions on the length of the data.
POST requests cannot be bookmarked or shared.
Encoding Form Data
Whenever we submit a web form, the data we have entered is submitted to the server as part of an HTTP request.
If the submit button is configured to use GET, then the data is appended to the URL, like a Google search, and if the submit button is configured to use POST, the data is added to the end of the HTTP request, after the request headers, separated from them by a blank line.
However, regardless of how the data is sent, it is always encoded in the same way.
Each form element on a page has a name and a value.
The data is encoded as a sequence of name=value pairs, separated with & symbols.
Neither names nor values can contain special characters, so any such characters in the data must be encoded using URL escape sequences.
These are two-digit hexadecimal codes prefixed with the % symbol.
You’ll find a full list of URL escape codes here, but as an example, a space character is encoded as %20.
HTTP Responses
When a web server receives an HTTP request, it interprets it, tries to fetch the data requested and return it. It may well fail, but whatever the result of attempting to fulfil the request, the server will formulate an HTTP response to communicate the outcome of the request to the client.
Similar to the request, an HTTP response has three parts, a status line, zero or more response header lines, and a final optional data segment, separated from the headers by a blank line.
Below is a truncated version of the HTTP response from Allison’s web server to a request for https://www.podfeet.com/blog/:
HTTP/1.1 200 OK
Date: Sat, 09 May 2015 15:52:42 GMT
Server: Apache
X-Pingback: https://www.podfeet.com/blog/xmlrpc.php
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
Set-Cookie: PHPSESSID=eand2g7q77privgcpvi6m7i7g2; path=/
Vary: Accept-Encoding
Transfer-Encoding: chunked
Content-Type: text/html; charset=UTF-8
<!DOCTYPE html PUBLIC '-//W3C//DTD XHTML 1.0 Transitional//EN' 'https://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd'>
<html xmlns='http//www.w3.org/1999/xhtml' lang='en-US'>
<head>
<meta http-equiv='Content-Type' content='text/html; charset=UTF-8' />
<title>NosillaCast</title>
...The first line of the response gives the HTTP version, and most importantly, the HTTP response code. This tells the client what kind of response it is receiving. You could receive a successful response, a response instructing the client to re-issue its request to a different URL (i.e. a redirect), a request for authentication (a username and password popup), or an error message.
After the HTTP response line comes a list of HTTP header lines, again, we won’t go into them all, but I do want to draw your attention to a few important ones.
Firstly, the Server header makes it possible to gather statistics on the web servers in use on the internet — notice that Allison’s site is powered by an Apache webserver.
The single most important response header is Content-Type, which tells the client what type of data it will receive after the blank line, and optionally, how it’s encoded.
In this case, the data section contains HTML markup encoded using UTF-8.
Also notice that the server is requesting the client set a new cookie using the Set-Cookie header and that the Cache-Control header is telling the client, in many different ways, that it absolutely positively should not cache a copy of this page.
The actual HTML markup for Allison’s home page is hundreds of lines long, I have only shown the first six lines.
It’s important to note that rendering a single web page generally involves many HTTP requests, often to multiple servers. The first response will usually be the HTML markup for the web page in question, but that HTML will almost certainly contain links to other resources need to render the page, like style sheets, images, JavaScript files, etc. As an example, rendering Allison’s home page requires 107 HTTP requests! That’s on the high side because Allison has a lot of videos embedded in her home page, and quite a few widgets embedded in her sidebars. However, on the modern web, it’s not unusual to need this many requests to render a single page.
|
Note - a later redesign of Allison’s site reduced the number of http requests to 68.
|
HTTP Response Codes
There are many supported HTTP response codes (click here for a full list), and we’re not going to go into them all, but I do want to explain the way they are grouped and highlight some common ones you’re likely to come across.
HTTP response codes are three-digit numbers starting with 1, 2, 3, 4, or 5. They are grouped into related groups by their first digit. All response codes starting with a 1 are so-called informational responses. These are rarely used. All response codes starting with a 2 are successful responses to requests. All response codes starting with a 3 are redirection responses. All responses starting with a 4 are client errors (in a very loose sense), and finally, all responses starting with a 5 are server errors.
Some common HTTP response codes:
200 - OK-
This is the response code you always hope to get, it means your request was successful
301 - Moved Permanently-
A permanent redirect, this redirect may be cached by clients
302 - Found-
A temporary redirect, this redirect should not be cached by clients as it could change at any time
400 - Bad Request-
The HTTP request sent to the server was not valid. You’re unlikely to ever see this in a browser, but if you muck around constructing your own requests on the terminal you might well see it when you get something wrong!
401 - Not Authorised-
Tells the client to request a username and password from the user
403 - Forbidden-
The requested URL exists, but the client has been denied access, perhaps based on the user they have logged in as the IP address they are accessing the site from, or the file-type of the URL they are attempting to access.
404 - Not Found-
One of the most common errors you’ll see — your request was valid, the server understood it, but it has no content to return to you at that URL.
500 - Internal Server Error-
The web programmers' most hated error — it just means the server encountered an error while trying to fulfil your request.
502 - Bad Gateway-
In the days of CDNs (Content Delivery Networks), these errors are becoming ever more common. It means that your browser has successfully contacted a front-end web server, probably at the CDN, but that the back-end server that actually contains the information you need is not responding to the front-end server. The front-end server is considered a gateway to the back-end server, hence the name of the error.
503 - Service Unavailable-
The server is temporarily too busy to deal with you — effectively a request to try again later.
504 - Gateway Timeout-
This error is similar to a 502 and is also becoming ever more common with the rise of CDNs, it means the back-end server is up but is responding too slowly to the front-end server, and the front-end server is giving up.
MIME Types
HTTP uses the Content-Type header to specify the type of data being returned.
The value of that header must be a so-called MIME Type or internet media type.
MIME Types have their origins in the common suite of email protocols, and were later adopted for use on the world wide web — after all, why reinvent the wheel!?
There are MIME types for just about everything, and they consist of two parts, a general type, and then a more specific identifier.
E.g.
all the text-based code files used on the web have MIME types starting with text, e.g.:
|
HTML markup |
|
JavaScript code |
|
CSS Style Sheet definitions |
Some other common web MIME Types include:
|
JPEG Photos |
|
PNG graphics |
|
MP3 audio |
|
MPEG 4 video |
Exploring HTTP With Your Browser
Before moving on to the HTTP-related terminal commands, let’s look at some of the debugging tools contained within our browsers. All modern browsers have developer tools, and they all do similar things, but the UI is different in each. My personal preference is to use Safari’s developer tools, but so as to make this section accessible to as many people as possible, we’ll use the cross-platform FireFox browser.
To enable the developer tools we are interested in today, browse to the site you want to explore, e.g. www.bartb.ie, and click on .
This will open a new subwindow at the bottom of your FireFox window with a message telling you to reload the page.
When you do, you’ll see all the HTTP requests needed to load my home page scroll by, with a timeline next to the list. If you scroll up to the very top of the list you’ll see the initial request, which received HTML markup in response from my server. All the other requests are follow-up requests for resources needed to render my home page, like JavaScript code files, CSS style sheets, and images.
You can click on any request to see more details. This will add a tab to the right with lots of tabs to explore, though the Headers tab is the one we are interested in. There is a button to show the raw headers.
You’ll notice a lot of 304 response codes.
This is a sign of efficient use of caching.
If you click on one of these requests and look at the raw headers, you’ll see that the request headers included a header called If-Modified-Since, which specifies a date.
That tells the server that the browser has a cached copy of this URL that was retrieved at the specified date.
The server can use this date to check if the content of the URL has changed since then.
If the data is unchanged, the server can respond with a 304 status code rather than a fresh copy of the data, this tells the client that the data has not changed, so it’s OK to use the cached version.
This kind of caching of static content like images saves a lot of bandwidth.
Conclusions
Hopefully, you now have a basic understanding of what your browser is doing when you visit a webpage. Do bear in mind though that we have ignored some of the subtle detail of the process so as not to add unnecessary confusion. While this description will be sufficient to understand the terminal commands that interact with web servers, it would not be sufficient to pass an exam on the subject!
Now that we understand the fundamentals of how HTTP works, we are ready to look at some related terminal commands.
In the next instalment, we’ll learn about three such terminal commands, lynx, wget and curl.
TTT Part 35 of n — HTTP Commands
In the previous instalment we introduced the HTTP protocol. In this instalment, we’ll look at three terminal commands which make use of the HTTP protocol.
We’ll start by browsing from the terminal, and then move on to a pair of very similar commands for making HTTP requests from the terminal. These two commands can do many things, but we’ll focus on two specific use cases: downloading files, and viewing HTTP headers.
Listen Along: Taming the Terminal Podcast Episode 35
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Browsing the Web from the Terminal
The modern internet tends to be a flashy place full of pictures and videos, but, much of its value still comes from the text it contains. Sometimes it’s actually an advantage to see the web free from everything but the text. For example, text is very efficient when it comes to bandwidth, so if you have a particularly poor internet connection, cutting out the images and videos can really speed things up. The visually impaired may also find it helpful to distil the internet down to just the text.
In both of these situations, the lynx text-based web browser can be very useful.
It allows you to browse the web from the terminal.
While many versions of Linux come with lynx installed by default, OS X doesn’t.
The easiest way to install it is using MacPorts.
Once you have MacPorts installed, you can install lynx on your Mac with the command:
sudo port install lynxOnce you have lynx installed, you can open any web page in your browser by passing the URL as an argument to the command lynx, e.g.:
lynx https://www.podfeet.comAs lynx loads the page, you’ll see it tell you what it’s doing, and it may ask your permission to accept some cookies.
Once the page is loaded, you can move down a whole screen of text at a time with the space bar, up a whole screen with the b key, and hop from link to link within the page with the up
and down
arrow keys.
To follow a link, hit the right
arrow key, to go back to the previous page, hit the left
arrow key.
You can go to a different URL by pressing the g key, and you can quit the app with the q key.
You can also search within a page with the / key.
Hitting / will allow you to enter a search string.
When you want to submit the search, hit Enter.
If a match is found, you will be taken to it.
You can move to the next match with the n key, and back to the previous match with Shift+n.
Viewing HTTP Headers & Downloading Files
wget and curl are a pair of terminal commands that can be used to make HTTP connections, and view the results.
Both commands can do almost all the same things, but they each do them in a slightly different way.
Just about every version of Linux and Unix will come with one or both of these commands installed.
OS X comes with curl, while wget seems to be more common on Linux.
Most Linux distributions will allow you to install both of these commands, and you can install wget on OS X using MacPorts:
sudo port install wgetDownloading Files
Both curl and wget can be used to download a file from the internet, but wget makes it a little easier.
The URL to download a zip file containing the latest version of Crypt::HSXKPasswd from GitHub is https://github.com/bbusschots/xkpasswd.pm/archive/master.zip.
The two commands below can be used to download that file to the present working directory:
wget https://github.com/bbusschots/xkpasswd.pm/archive/master.zip
curl -O https://github.com/bbusschots/xkpasswd.pm/archive/master.zipBy default, wget downloads URLs, while curl’s default is to print their contents to `STDOUT.
The -O option tells curl to output to a file rather than STDOUT.
Both of the commands above will save the file locally with the name at the end of the URL.
While that is a sensible default, it’s not always what you want.
In fact, in this case, the default file name is probably not what you want, since master.zip is very nondescript.
Both commands allow an alternative output file to be specified:
wget -O HSXKPasswd.zip https://github.com/bbusschots/xkpasswd.pm/archive/master.zip
curl -o HSXKPasswd.zip https://github.com/bbusschots/xkpasswd.pm/archive/master.zip
curl https://github.com/bbusschots/xkpasswd.pm/archive/master.zip > HSXKPasswd.zipViewing HTTP Headers
When developing websites, or when configuring redirects, it can be very helpful to see exactly what is being returned by the webserver.
Web browsers have a tendency to cache things, which can make broken sites appear functional, and functional sites appear broken.
When using curl or wget, you can see exactly what is happening at the HTTP level.
As an example, let’s look at the redirect Allison has on her site to redirect people to her Twitter account: https://www.podfeet.com/twitter.
To see exactly what Allison’s server is returning, we can use wget with the --spider and -S options:
bart-iMac2013:~ bart$ wget --spider -S https://www.podfeet.com/twitter
Spider mode enabled. Check if remote file exists.
--2015-07-04 17:36:12-- https://www.podfeet.com/twitter
Resolving www.podfeet.com (www.podfeet.com)... 173.254.94.93
Connecting to www.podfeet.com (www.podfeet.com)|173.254.94.93|:80... connected.
HTTP request sent, awaiting response...
HTTP/1.1 301 Moved Permanently
Date: Sat, 04 Jul 2015 16:36:12 GMT
Server: Apache
Location: https://twitter.com/podfeet
Keep-Alive: timeout=10, max=500
Connection: Keep-Alive
Content-Type: text/html; charset=iso-8859-1
Location: https://twitter.com/podfeet [following]
Spider mode enabled. Check if remote file exists.
--2015-07-04 17:36:12-- https://twitter.com/podfeet
Resolving twitter.com (twitter.com)... 199.16.156.198, 199.16.156.70, 199.16.156.102, ...
Connecting to twitter.com (twitter.com)|199.16.156.198|:443... connected.
HTTP request sent, awaiting response...
HTTP/1.1 200 OK
cache-control: no-cache, no-store, must-revalidate, pre-check=0, post-check=0
content-length: 262768
content-security-policy: default-src https:; connect-src https:; font-src https: data:; frame-src https: twitter:; img-src https: blob: data:; media-src https: blob:; object-src https:; script-src 'unsafe-inline' 'unsafe-eval' https:; style-src 'unsafe-inline' https:; report-uri https://twitter.com/i/csp_report?a=NVQWGYLXFVZXO2LGOQ%3D%3D%3D%3D%3D%3D&ro=false;
content-type: text/html;charset=utf-8
date: Sat, 04 Jul 2015 16:36:13 GMT
expires: Tue, 31 Mar 1981 05:00:00 GMT
last-modified: Sat, 04 Jul 2015 16:36:13 GMT
ms: A
pragma: no-cache
server: tsa_b
set-cookie: _twitter_sess=BAh7CSIKZmxhc2hJQzonQWN0aW9uQ29udHJvbGxlcjo6Rmxhc2g6OkZsYXNo%250ASGFzaHsABjoKQHVzZWR7ADoPY3JlYXRlZF9hdGwrCD%252Fg7FlOAToMY3NyZl9p%250AZCIlMDc5ODNiZjRjY2VmYTZmMzkyMjViNzUzMzBjMTlmN2M6B2lkIiVlMGRl%250AMGUxNThhOGFlYjQ2MDk5MzhlYTg5MDVhZjkwYg%253D%253D--eb013985df212afa338abf74675b639d75a96486; Path=/; Domain=.twitter.com; Secure; HTTPOnly
set-cookie: guest_id=v1%3A143602777299066731; Domain=.twitter.com; Path=/; Expires=Mon, 03-Jul-2017 16:36:13 UTC
status: 200 OK
strict-transport-security: max-age=631138519
x-connection-hash: 781f41ed342615977688eb6f432f7fc4
x-content-type-options: nosniff
x-frame-options: SAMEORIGIN
x-response-time: 127
x-transaction: b3fb3de740391d24
x-twitter-response-tags: BouncerCompliant
x-ua-compatible: IE=edge,chrome=1
x-xss-protection: 1; mode=block
Length: 262768 (257K) [text/html]
Remote file exists and could contain further links,
but recursion is disabled -- not retrieving.
bart-iMac2013:~ bart$The --spider option tells wget not to download the actual contents of the URL, and the -S flag tells wget to show the server headers.
By default, wget will follow up to 20 redirects, so there is much more output here than we really need.
The information we need is there, and I have highlighted it, but it would be easier to get to if wget didn’t follow the redirect and then ask Twitter’s server for its headers too.
Since we only need the first set of headers, we need to tell wget not to follow any redirects at all, and we can do that with the --max-redirect flag:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
bart-iMac2013:~ bart$ wget --spider -S --max-redirect 0 https://www.podfeet.com/twitter
Spider mode enabled. Check if remote file exists.
--2015-07-04 17:38:45-- https://www.podfeet.com/twitter
Resolving www.podfeet.com (www.podfeet.com)... 173.254.94.93
Connecting to www.podfeet.com (www.podfeet.com)|173.254.94.93|:80... connected.
HTTP request sent, awaiting response...
HTTP/1.1 301 Moved Permanently
Date: Sat, 04 Jul 2015 16:38:45 GMT
Server: Apache
Location: https://twitter.com/podfeet
Keep-Alive: timeout=10, max=500
Connection: Keep-Alive
Content-Type: text/html; charset=iso-8859-1
Location: https://twitter.com/podfeet [following]
0 redirections exceeded.
bart-iMac2013:~ bart$
The information we need is now much easier to find. We can see that Allison’s server is returning a permanent redirect (HTTP response code 301) which is redirecting browsers to https://twitter.com/podfeet.
We can, of course, do the same with curl:
1
2
3
4
5
6
7
8
bart-iMac2013:~ bart$ curl -I https://www.podfeet.com/twitter
HTTP/1.1 301 Moved Permanently
Date: Sat, 04 Jul 2015 16:43:49 GMT
Server: Apache
Location: https://twitter.com/podfeet
Content-Type: text/html; charset=iso-8859-1
bart-iMac2013:~ bart$
The -I flag tells curl to only fetch the headers and not the contents of the URL.
When fetching headers, curl does not follow redirects by default, so there is no need to suppress that behaviour.
Often, you only care about the response headers, so the output of curl -I is perfect, but, when you do want to see the request headers too, you can add the -v flag to put curl into verbose mode:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
bart-iMac2013:~ bart$ curl -vI https://www.podfeet.com/twitter
* Hostname was NOT found in DNS cache
* Trying 173.254.94.93...
* Connected to www.podfeet.com (173.254.94.93) port 80 (#0)
> HEAD /twitter HTTP/1.1
> User-Agent: curl/7.37.1
> Host: www.podfeet.com
> Accept: */*
>
< HTTP/1.1 301 Moved Permanently
HTTP/1.1 301 Moved Permanently
< Date: Sat, 04 Jul 2015 16:46:29 GMT
Date: Sat, 04 Jul 2015 16:46:29 GMT
* Server Apache is not blacklisted
< Server: Apache
Server: Apache
< Location: https://twitter.com/podfeet
Location: https://twitter.com/podfeet
< Content-Type: text/html; charset=iso-8859-1
Content-Type: text/html; charset=iso-8859-1
<
* Connection #0 to host www.podfeet.com left intact
bart-iMac2013:~ bart$
And More …
This is just a taster of what curl and wget can do.
For more details, see their relevant man pages.
I like to have both curl and wget installed on all my computers because I find wget easier to use for downloading files and curl easier to use for viewing HTTP headers.
Conclusions
Armed with lynx, curl, and wget, you can use the terminal to browse the web, download files, and peep under the hood of HTTP connections.
When working on websites, you may find you can save a lot of time and energy by using these terminal commands to see exactly what your web server is returning.
This instalment concludes our look at the HTTP protocol. In the next instalment, we’ll move on to look at two commands that allow you to see what your computer is doing on the network in great detail.
TTT Part 36 of n — screen & cron
The previous 13 instalments in this series related to networking, but we’re going
to change tack completely for this instalment, and look at two unrelated, but
very useful terminal commands — screen, and cron.
screen has been replaced with tmuxPlease refer to ttt38 in which it is explained that |
screen is a utility that allows for the creation of persistent virtual terminal sessions that you can disconnect from without terminating, and reconnect and pick up where you left off at a later time.
screen is particularly useful when used in conjunction with SSH.
cron, on the other hand, is a system for automatically executing recurring tasks.
It’s extremely flexible and very useful for things like scheduling backups to run in the middle of the night.
Listen Along: Taming the Terminal Podcast Episode 36
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
The screen Utility
The screen command is included with OS X by default, but it is not included by default on all Linux distros.
It is however usually available through the distro’s standard package manager.
screen creates a virtual terminal that detaches itself from the shell that starts
it. It will continue to run even when that shell ends, because you closed the
terminal window or logged out of the computer.
This means that screen sessions keep running until they are explicitly ended, or the computer is rebooted.
The idea is that you can connect and disconnect as often as you like, allowing you to pick up right where you left off.
There are many situations in which this is very useful. Below are just a few examples:
-
When connecting to a server over SSH from a laptop that is regularly put to sleep — if you do all your work on the remote server in a screen session, you can disconnect and reconnect without interrupting your workflow.
-
When connecting to a server over SSH from a location with poor internet connectivity — if you use screen, a network interruption will not terminate a running command.
-
When running commands that will take a long time to execute — you can start the command in a screen session, disconnect, and check back on it a few hours, or even days, later.
-
When multiple real humans have to share a single login account on a computer — each can do their work in their own named screen session.
Remember that screen must be installed on the computer where the session will run, so if you want to run a session on a remote machine you are SSHing to, screen needs to be installed on the remote machine.
Screen sessions run as, and belong to, the user that creates them. You can run arbitrarily many screen sessions at any one time. To see all your currently running sessions, use the command:
screen -ls
If you have no running screen sessions, it will give you output something like:
$ screen -ls
No Sockets found in /var/folders/0f/8m9p9bj556394xd50jl4g_340000gn/T/.screen.
$You can start a new screen session with the command:
screen
You may get a welcome message asking you to hit space to continue, if you do, hit space.
You’ll then get a new command prompt.
This is your screen session, not your original shell.
You can run commands in here as normal.
As an example, let’s run a command that never ends, top.
We can now disconnect from this screen session and return to our regular command prompt with the key combination Ctrl+a+d.
If we now list our current sessions, we should see one listed:
screen -ls
We can reconnect to our most recent screen session with the command:
screen -r
This will get us back into our session, where top is still running, just like we left it.
Let’s end this session by typing q to quit out of top, and get our shell back within our screen session, and then exit to end the screen session.
You may want to use different screen sessions for different tasks, in which case it makes sense to give them human-friendly names.
You can create a named session with the following command (replacing SESSION_NAME with the name you would like to give the session):
screen -S SESSION_NAME
At a later time, you can then reconnect to that session with:
screen -r SESSION_NAME
Let’s create a named session for top:
screen -S top
In this session, start top:
top
Now, disconnect from the session (Ctrl+a+d).
You can see that the session has been named:
$ screen -ls
There is a screen on:
6125.top (Detached)
1 Socket in /var/folders/0f/8m9p9bj556394xd50jl4g_340000gn/T/.screen.
$(The number before the name is the process ID for the session.)
We can now re-connect to our named session with:
screen -r top
By default, each screen can only be attached to by one client at a time. If you try to attach to a screen session that already has a client attached, you will not succeed.
When you use screen over SSH, you can easily end up in a situation where you have accidentally left yourself attached to a session on a computer at home or in the office, and you now need to attach to that same session from your laptop while out and about.
When you find yourself in this situation, you have two choices — you can use the -d flag to remotely detach the other client, e.g.
screen -rd SCREEN_NAME, or, you can choose to share the session in real-time using the -x flag, e.g.
screen -rx SCREEN_NAME.
You can test both of these behaviours on a single machine by opening two terminal windows.
In the first window, start a named session with: screen -S test.
In the second terminal window, try to attach to this session with just the -r flag: screen -r test.
You will get an error something like:
$ screen -r test
There is a screen on:
31366.test (Attached)
There is no screen to be resumed matching test.
$Let’s now try the first of our options by entering the following in the second terminal window:
screen -rd test
Notice that the screen session in the first window was detached.
Finally, let’s use the first window to try our second option, sharing the session. In the first, now detached terminal window, enter:
screen -rx test
Notice that now, both terminal windows are seeing the same session, and they are sharing it in real time. If you type in one, you’ll see yourself in the other!
As well as allowing you to have multiple sessions, screen also allows you to have multiple virtual windows within each session.
When in a screen session, you can create a new window with the key combination Ctrl+a+c (for create).
You’ll see that gives us a new window.
You can toggle between the two most recent windows within a session with Ctrl+a twice in a row.
If you have more than two windows you’ll need to use either Ctrl+a+n (for next) to move forward through the windows, or Ctrl+a+p (for previous) to move backwards through the windows.
To see a list of your windows in the bottom left of the terminal, press Ctrl+a+w (this will not work if you are in an app that is constantly rewriting the screen like top).
Windows are numbered from zero, and your current window is indicated with a * after the number.
Personally, I find virtual windows within virtual screens much too confusing, so I never use this feature. Some people do find it very useful though, so I thought it was worth mentioning in case it is of use to some.
The cron Utility
Unix/Linux systems, including OS X, use a system known as cron for automating the repeated execution of tasks.
The rules of the repetition are extremely flexible, and as a result, the syntax can be a little daunting at first.
The way the cron system works is that each user may define a so-called crontab, which is a table listing tasks to be run, and defining when they should be run.
Tasks, or jobs, in a user’s crontab, will run as that user, but with a very minimal environment.
Any output sent to STDOUT or STDERR by a cron job will be emailed to the user using the local mail exchanger.
On modern OS X desktops, that means it goes into your user’s Unix mailbox, which you do not see in Mail.app, and probably have no idea exists.
We’ll look in more detail at what to do with the output from cron jobs later.
To see your crontab, simply run the command crontab -l (for list).
Unless you have added something to your cron previously, this command probably returns nothing.
You can edit your crontab with the command crontab -e (for edit).
This will open your crontab with your system’s default text editor (probably vi, which we learned about in instalment 11).
Your cron jobs need to be specified one per line in a special format.
First, you specify when the command should be run as five space-delimited time specifiers, then you add another space, and then you add the command to be run, along with all its arguments. The five time-specifiers tend to be the cause of people’s confusion when it comes to the crontab.
The way it works is that every minute, every cron job who’s five-part time specifier matches the current time gets executed.
Lines in the crontab starting with # are comment lines, that is to say, cron ignores them.
Blank lines are also ignored.
As well as lines starting with time specifiers and comment lines, a crontab can also contain a number of special command lines. We’ll see some of these later in this instalment.
Specifying When
The five parts to the time specifier are:
-
Minute (0-59)
-
Hour (0-23)
-
Day of Month (1-31)
-
Month (1-12)
-
Day of Week (0-6, with Sunday as zero)
For each of these five specifiers, you can enter a number, or, the character *, which is interpreted to mean any.
So, to run a command on-the-hour-every-hour, you would use the specifier:
0 * * * *
This will match when the minutes are exactly zero, the hour is anything, the day of the month is anything, the month is anything, and the day of the week is anything.
To run a command at 4:30 am on the first of every month you would use the specifier:
30 4 1 * *
In other words, the specifier will match when the minute is 30, the hour is 4, the day of the month is 1, the month is anything, and the day of the week is anything.
As well as taking single numbers, each of the five parts of the specifier can take multiple comma-separated values and ranges (don’t add spaces after the commas). So, to run a task at 8 am and 8 pm every weekday you would use the specifier:
0 8,20 * * 1-5
That is, when the minute is zero, the hour is 8 or 20, any day of the month, any month, and the day of the week is between 1 and 5 inclusive, i.e. Monday to Friday.
Finally, you can use the */n syntax to specify that something should happen every n minutes (or hours etc.)
To run a command every two minutes you would use the specifier:
*/2 * * * *
As a final example, to run a command every two minutes during business hours on weekdays you would use the following specifier:
*/2 9-18 * * 1-5
Dealing with Output
By default, all output to either STDOUT or STDERR will get emailed to the local Unix mailbox for the user that owns the crontab.
You can specify a different email address to send the output to with the special MAILTO command.
The format is very simple (replacing an.email@addre.ss with the actual email address output should be emailed to):
MAILTO an.email@addre.ss
A single crontab can specify multiple different MAILTO commands.
The way it works is that all defined cron jobs use the MAILTO definition that precedes them most closely.
You should consider the top of the file to have an implicit MAILTO command of the form:
MAILTO username@localhost
If both your ISP and the email provider hosting the target email address are accommodating, this will work from your desktop or laptop. It does for me. However, many ISPs and many mail servers will reject email coming from home IP addresses rather than trusted mail servers.
If you definitely want to use email, you have two options. Firstly, OS X uses the open source MTA (Mail Transfer Agent) Postfix, so you could re-configure postfix to use a mail relay to send the emails on your behalf. In the past, many ISPs provided an SMTP server for their customers to use, so if your ISP does, this is at least a plausible option. This is not for the faint-hearted though — you’ll need to take the time to familiarise yourself with Postfix and to learn what the different settings in the config file do.
Your second option is to use the built-in command-line mail client in OS X to read your Unix inbox directly.
The command is mail, and there is a man page explaining how it works.
This works, but it’s quite clunky.
A simple cron Example
To see cron in action, let’s create a simple crontab that will write the current time to a text file every 2 minutes.
The terminal command to see the current date and time is date.
We’ll write our file to a location that is universally writeable on all Macs — the temporary folder, /tmp.
To edit your crontab, run the command crontab -e.
You are now in vi.
Enter insert mode by pressing the i key.
Enter the following:
*/2 * * * * /bin/date >> /tmp/crontest.log
Exit insert mode by hitting the escape key.
Save the crontab by typing :wq and then enter/return.
Verify that your crontab has been saved with crontab -l.
Now watch for the output to the file with:
tail -f /tmp/crontest.log
Every two minutes you should see the current date and time be appended to the file.
Cron & the Environment
You may notice that I used the full path to the date command in the above example.
The reason for this is that cron executes your cron jobs with a very minimal environment.
As we learned in instalment 12, you can see the content of your environment in a regular shell with the command env.
To see what the environment looks like from cron’s point of view, add the following to your crontab, then wait for at least two minutes:
*/2 * * * * /usr/bin/env > /tmp/cronenv.txt
When more than two minutes have passed, you should see a copy of the environment from the point of view of a cron job with the command:
1
2
3
4
5
6
7
8
9
10
$ cat /tmp/cronenv.txt
SHELL=/bin/sh
USER=bart
PATH=/usr/bin:/bin
PWD=/Users/bart
SHLVL=1
HOME=/Users/bart
LOGNAME=bart
_=/usr/bin/env
$
Notice that while there is a PATH environment variable, it has very little in it.
This is why you are best off always using full paths when executing commands via cron.
You can set environment variables in the crontab. You simply assign them on a line by themselves. We can add a new variable by adding a line like:
DUMMY_ENVIRONMENT_VARIABLE=boogers
The definition needs to be earlier in the crontab than the cron jobs that will use the variable. If you edit your crontab so it contains the following:
DUMMY_ENVIRONMENT_VARIABLE=boogers
*/2 * * * * /usr/bin/env > /tmp/cronenv.txtThen wait at least two minutes, and then run the command:
cat /tmp/cronenv.txt
You should now see your new variable has indeed been added to your cron job’s environment.
You could use this technique to set your own value for the PATH environment variable.
My preference is not to alter the PATH within the crontab, but to always use full paths in my cron jobs.
That seems a more robust and explicit approach to me.
Final Thoughts
In this instalment, we’ve seen how to use screen to create persistent virtual terminals that can be disconnected from and reconnected to later, and how to use cron to schedule periodic tasks.
This is the first taming the terminal in some time, and will probably be the last one for a while too.
There will be more instalments, but not at regular intervals.
TTT Part 37 of n — SSH Agents
Since we covered SSH in parts 29 & 30, Apple has changed how their desktop OS deals with the passphrases protecting SSH identities (key pairs). This provides us with a good opportunity to have a look at the SSH Agent in general, and, how things have changed on the Mac in particular.
The good news is that while things have changed on the Mac, with a small amount of effort, you can get back all the convenience and security you had before.
|
This instalment was originally written, and its matching podcast episode recorded in May 2017. The Mac-specific aspects of this instalment were updated in February 2021, and an additional supplemental podcast was recorded and has been linked below. |
Listen Along: Taming the Terminal Podcast Episode 37
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Listen Along: Taming the Terminal Podcast Episode 37A
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Revision — SSH Identities
As a quick reminder — SSH can authenticate users in many ways.
The two most common are passwords, and so-called SSH identities (sometimes referred to as SSH keys).
An SSH identity consists of a private key, a matching public key, and some metadata.
The two keys are stored in separate files, and the name of the file containing the public key must be identical to the one for the private key, but with .pub appended to it.
When SSH config files or commands require the path to an identity, what they’re looking for is the path to the private key’s file.
SSH identities are created using the ssh-keygen command.
SSH has the concept of a default identity.
Wherever an identity can be used, SSH will check a number of pre-defined file paths (in a pre-defined order) for a valid identity file, and use the first one it finds.
Today, using the most modern versions of SSH and the default key algorithms, that effectively means that your default identity is ~/.ssh/id_rsa (and ~/.ssh/id_rsa.pub).
As with any cryptographic system based on public & private keys, your security completely depends on keeping the private key secret, and the publication of your public key has no impact on your security at all.
That means that the half of the identity that doesn’t end in .pub is the crown jewels, and you are free to share the half that does end in .pub freely.
No sysadmin should ever ask you for your private key; they should only ever need your public key. If you want to be granted access to a computer, you give the person who manages that computer your public key, they grant access to that key, and you can then log on from the computer that had the matching private key.
To protect your private key, SSH identity files support passphrase-based encryption. The actual values stored in the files can be the result of encrypting the private key with a passphrase. The ssh-keygen command will allow you to set a blank password on an identity, but it very much encourages you not to do that, and to set a good, secure passphrase.
If you follow best practice and do indeed set a passphrase on your identity, SSH will prompt you for that passphrase whenever it needs the private key part of that identity. This gets very tedious very quickly, and that’s where the SSH Agent comes in.
SSH Agents
The SSH Agent’s raison d’être is to take the pain out of using passphrase-protected SSH identities. SSH Agents securely cache the decrypted private keys belonging to SSH identities. SSH Agent processes are generally not shared between users. In fact, they’re generally not even shared between login sessions. When I log into my Mac, a new SSH Agent is automatically started, and that specific SSH Agent is only accessible by apps or commands that I start within that login session. SSH Agents don’t store anything permanently — they forget everything as soon as they stop running, and logging out will kill the SSH Agent associated with a specific login session.
The core SSH libraries are aware of SSH Agents and can communicate with them, so the caching they provide is available to all the SSH-related terminal commands like ssh, scp, sftp, as well as to any GUI apps [2] that make use of the appropriate SSH APIs, for example, both Transmit and SequelPro have SSH Agent support.
The exact mechanisms for configuring an SSH Agent to automatically start and stop on login and logout varies from OS to OS, but many desktop Unix/Linux flavours start SSH Agents by default.
Apple has done so on the Mac since Mac OS X 10.5 Leopard.
If you’re not a Mac user you’ll need to do a little Googling to figure out what the state of play is on your particular OS.
Note that there are even SSH Agent implementations for Windows.
You can use Cygwin to run OpenSSH’s SSH Agent, or, you can use pageant.exe, an SSH Agent from the people behind the venerable PuTTY SSH client.
It’s All About the ssh-add Command
On Linux/Unix systems, the SSH Agent is provided by the command ssh-agent, but that’s not the command you use to interact with your particular SSH Agent.
Instead, all your interaction with your SSH Agent will be via the command ssh-add.
Firstly, you can check that you actually have a running SSH Agent associated with your login using the -l flag (for list).
If you do have a running SSH Agent you’ll either see a list of loaded identities or, a message like the following:
$ ssh-add -l
The agent has no identities.
$If no SSH Agent is running you’ll get an error message something like:
$ ssh-add -l
Could not open a connection to your authentication agent.
$Loading Identities into an SSH Agent
You can load your default identity (generally ~/.ssh/id_rsa) into your SSH agent with the command:
ssh-addAnd, you can add a specific identity with the -a flag, e.g.:
ssh-add -a ~/some_ssh_identity_fileNote that you will be asked to enter the passphrase for each identity as you load it.
Once you have one or more identities loaded into your SSH Agent you should see them when you run ssh-add with the -l flag:
$ ssh-add -l
2048 SHA256:UNP5g9KBBOfqi2RYrtY2aGILNbcvp2pe23+38Ignvsc /Users/bart/.ssh/id_rsa (RSA)
$Removing Identities from an SSH Agent
Counter-intuitively, you also use the ssh-add command to remove identities from your SSH Agent.
You can remove just your default identity by passing only the -d flag:
$ ssh-add -d
Identity removed: /Users/bart/.ssh/id_rsa (bart@localhost)
$You can remove other identities by passing the path to the file representing the identity in question as an argument after the -d flag, e.g.:
ssh-add -d ~/some_ssh_identity_fileYou can also remove all identities at once with the -D flag:
$ ssh-add -D
All identities removed.
$SSH Agent on macOS (and OS X)
Update — February 2021: this section has been completely re-written to better reflect the current state of play on the Mac.
Since Mac OS X 10.5 Leopard, Apple has integrated SSH Agents into their OS. When you log in to a Mac, you’ll find an SSH Agent running and ready to accept identities.
SSH Agents and the Keychain
One of the Mac’s core security technologies is the Keychain. Each user account has a Keychain associated with it, and those Keychains securely store sensitive data like passwords and private keys. Keychains are encrypted files, the contents of which can only be accessed through the operating system. The keychain’s encryption key is secured with the user’s password, and by default, when the a user logs into their Mac their password is used to simultaneously unlock their Keychain, allowing the OS to securely share passwords with apps the user runs.
Since Apple added support for SSH Agents they have also customised the version of the SSH Agent that runs on the Mac to integrate it with the Keychain. While we’ve had this integration all along, the change from OS X to macOS brought with it a dramatic change in how SSH Agents behave by default, and specifically, how they interact with the Keychain by default.
In OS X the integration with the Keychain was always on, and each time a passphrase was needed for an SSH identity the OS popped up a password prompt in a separate window, and that window had a checkbox to let you store the password in the Keychain. If you checked that box, then from that point forward you would never be prompted for the password again, SSH would always read the passphrase from the Keychain without any user interaction.
What was happening under the hood is that when you logged into your Mac an SSH Agent was started for you, and all SSH passwords found in the Keychain were automatically loaded into that SSH Agent.
This behaviour was very convenient, but also very non-standard, it’s simply not how SSH Agents behave on other platforms.
When Apple released macOS 10.12 Sierra, they changed their SSH Agent’s default behaviour to bring it into line with its behaviour elsewhere.
Apple did not remove the integration with the Keychain, they simply stopped the SSH Agent sharing passwords with the Keychain by default. Unless you explicitly ask it to, your SSH Agent won’t read passwords from the Keychain, or, write passwords to the Keychain. It can still do both of those things, but only when you tell it to!
Apple’s Custom ssh-add Flags
To integrate with the Keychain Apple has added two flags to the ssh-add command — -K and -A.
The -K flag effectively means 'and on the keychain too' — if you use ssh-add -K to load your default identity into your SSH Agent the passphrase will also get copied into your Keychain. If you want to remove an identity and its passphrase from both your Agent and the keychain use the -K flag along with the -d flag (for delete).
You can load your default SSH identity into your SSH Agent and copy it into your Keychain with the simple command:
% ssh-add -K
Enter passphrase for /Users/bart/.ssh/id_rsa:
Identity added: /Users/bart/.ssh/id_rsa (/Users/bart/.ssh/id_rsa)
%Note that you may not be prompted for the passphrase, in which case you’ll get a message like the following:
% ssh-add -K
Identity added: /Users/bart/.ssh/id_rsa (/Users/bart/.ssh/id_rsa)
%You can similarly add other identities by adding their file paths to the command above, e.g. ssh-add -K some_identity.
|
View SSH Identities in Keychain
You can see the SSH identities stored in your keychain by opening the Keychain Access app (in Applications → Utilities) and searching for ssh. Identities will be listed as the path to the private key pre-fixed with |
To remove your default identity from your Keychain (and your SSH Agent), use the -d and -K flags with the path to your default identity. Note that you can cuddle the flags, so for me the command is:
% ssh-add -dK /Users/bart/.ssh/id_rsa
Identity removed: /Users/bart/.ssh/id_rsa (bart@bartmac.local)
%Note that you have to remove identities from the Keychain one-by-one, you can’s use the -K flag in conjunction with the -D (delete all) flag.
So, we use the -K flag to send changes to the Keychain, how do we read identities from the keychain? That’s what the -A flag is for — it loads all SSH identities found in your Keychain into your SSH Agent'. The flag requires no arguments, so loading SSH identities into your SSH Agent from your Keychain is as simple as:
ssh-add -AStart Using your Keychain for your SSH Identity
To start using your Keychain for your SSH identity you’ll need to load it into your Keychain with:
ssh-add -KYou only have to do that once — your identity has been permanently added to your Keychain.
|
SSH Identities on Multiple Macs
If you have multiple Macs and have iCloud Keychain enabled, the passphrases for your SSH Keys will synchronise to all your Macs. For this to work reliably you should use the same SSH identity on all your Macs. |
To use the passphrase now stored in your keychain, simply run ssh-add -A once before using SSH to load the passphrase for your identities into your SSH Agent from your Keychain.
Remembering to run ssh-add -A every time is not a huge imposition, but it seems like the kind of thing you should be able to automate, and thankfully, it is!
Automating the Keychain Integration
As well as adding two flags to the ssh-add command, Apple also added two additional config directives.
The first of these, AddKeysToAgent can be used to automatically load the SSH identities for which there are passphrases in your Keychain into your SSH Agent when you log in to your Mac. This has the same effect as always running ssh-add -A after login.
The second, UseKeychain, defaults ssh-add to always add passphrases to your Keychain when you load them into your SSH Agent. In effect, it turns ssh-add into ssh-add -K, saving you the need to remember to use the -K flag.
To enable one or both of these options, add them to your SSH config file (~/.ssh/config):
UseKeychain yes
AddKeysToAgent yesFor example, this is what my config file looks like:
% cat ~/.ssh/config
# enable integration between Keychain and SSH Agent
UseKeychain yes
AddKeysToAgent yes
%To make sure you have enabled Keychain integration correctly, log out, log back in again, and open a fresh Terminal window. If everything is working as expected your default identity should be loaded into your SSH Agent ready for use. You can verify this with ssh-add -l, e.g.:
% ssh-add -l
2048 SHA256:rTpb4ShxOt0QzwfFu+SJ5nCIeA99/EUC8WPeYp56WCk /Users/bart/.ssh/id_rsa (RSA)
%Final Thoughts
Regardless of your OS, you can make use of an SSH Agent to avoid having to re-enter passwords for SSH identities over and over again. This is true on all OSes, even Windows. This is yet another reason to stop using password-less SSH identities — with an SSH Agent, you can have both security and convenience!
And, for all you Mac users like me who were cranky at the loss of the automated integration between the Keychain and the SSH Agent in macOS Sierra, you’ve now got a robust and supported fix.
TTT Part 38 of n — TMUX (A Screen Alternative)
Since we covered the screen command in instalment 36, it has been deprecated in Red Enterprise Linux 8, and the official advice from Red Hat is to transition to the tmux command. Having been a fan of screen for years, I was skeptical, but I shouldn’t have been. tmux can do everything screen can, it can arguably do it better, and, it can do much more than screen ever could!
Listen Along: Taming the Terminal Podcast Episode 38
part of episode 645 of the Chit Chat Across the Pond Podcast
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
As you may remember, the screen command allows you to create a command line session that continues to run after you close your terminal window or disconnect from your SSH session. At a later time you can then reconnect to the still-running screen session and pick up where you left off. This is very useful for executing long-running commands, and for working on a remote server over a spotty internet connection.
It’s very easy to use tmux to achieve exactly the same result, and the commands are arguably simpler — the arguments are certainly a lot more sensible and obvious anyway. 🙂
Sessions, Windows, and Panes
The screen command works on a very simplistic model — each virtual terminal is a session, and you can have as many sessions as you like. By default screen sessions are numbered, but you can name them for your convenience.
The tmux command expands this model by introducing the concepts of windows and panes within numbered or optionally named sessions. The name tmux is a portmanteau of terminal multiplexer, so it’s built around the idea of running multiple terminals within a single visible window.
tmux sessions contain one or more tmux windows each of which contain one or more tmux panes. A tmux pane is a command shell. You can tile these panes into tmux windows, and you can stack these tmux windows one on top of the other within tmux sessions.
It’s unfortunate that tmux chose to re-use the word window, because it already has a meaning within GUI operating systems, so it often leads to confusion. I find it helpful to think of tmux windows as being like browser tabs — multiple full-page vertically stacked windows-within-a-window. Like a single browser window stacks multiple tabs on top of each other, a single tmux session stacks multiple tmux windows on top of each other.
If this all sounds too complicated, don’t worry, a default tmux session contains a single window which contains a single pane. In other words, by default tmux behaves like screen.
Installing tmux
On Linux tmux will almost certainly be available from your distribution’s standard package manager, so for people on RHEL-flavoured distros it will probably be:
sudo yum install tmuxAnd for Debian-flavoured distros probably:
sudo apt-get install tmuxOn macOS we’ll need to use a third-party package manager like Homebrew to easily install tmux:
brew install tmuxThe tmux Command
Regardless of what you’re trying to do with tmux, the command will generally be of the form:
tmux COMMAND [OPTIONS]Where COMMAND is one of the many tmux commands listed in the extensive manual page (man tmux), and OPTIONS are optional extra flags to pass information to the specified command.
The tmux commands are very descriptively named, which makes them easy to read but hard to type, so tmux provides short aliases for the most commonly used commands, e.g. lscm is an alias for the extremely convenient list-commands which lists all the commands tmux supports, or, gives details on a specific command:
bart-imac2018:~ bart% tmux lscm
attach-session (attach) [-dErx] [-c working-directory] [-t target-session]
bind-key (bind) [-nr] [-T key-table] [-N note] key command [arguments]
break-pane (breakp) [-dP] [-F format] [-n window-name] [-s src-pane] [-t dst-window]
capture-pane (capturep) [-aCeJNpPq] [-b buffer-name] [-E end-line] [-S start-line] [-t target-pane]
...
unbind-key (unbind) [-an] [-T key-table] key
unlink-window (unlinkw) [-k] [-t target-window]
wait-for (wait) [-L|-S|-U] channel
bart-imac2018:~ bart% tmux lscm rename-session
rename-session (rename) [-t target-session] new-name
bart-imac2018:~ bart%Managing Sessions
Let’s start our exploration of tmux at the highest level — the session.
Listing Sessions Creating & Joining Sessions
Before we create our first session, let’s learn how to list the currently running sessions. The command is list-sessions, but it has the convenient alias ls.
When you have no sessions running you should expect to see something like:
bart-imac2018:~ bart% tmux ls
no server running on /private/tmp/tmux-501/default
bart-imac2018:~ bart%The default command is new-session, or new, so to create an un-named new session and attach to it (tmux jargon for connect), simply run tmux with no arguments.
You’ll now find yourself inside a tmux session. Leave this session alone for now, and open another terminal window.
From this new terminal we can see that we now have a single running tmux session numbered 0 with no name:
bart-imac2018:~ bart% tmux ls
0: 1 windows (created Sat Jul 11 12:39:56 2020) (attached)
bart-imac2018:~ bart%When reading this output, note that the session’s name is the very first line in the output. Since we didn’t give our session a human-friendly name, it defaulted to the very computery 0! We can also see that the session contains one window, the date it was created. The (attached) suffix tells us there is currently a client connected to the session, i.e. our first terminal window.
In tmux-jargon connecting to a session is attaching, and disconnecting is detaching.
If we run the tmux command again in our second terminal window we will create a new session — let’s go ahead and do that:
tmuxNow, go ahead and open a third terminal window and list the sessions again:
bart-imac2018:~ bart% tmux ls
0: 1 windows (created Sat Jul 11 12:39:56 2020) (attached)
1: 1 windows (created Sat Jul 11 12:47:35 2020) (attached)
bart-imac2018:~ bart%We can now see that we have two sessions, again, rather un-imaginatively named 0 and 1. 🙂
Let’s now use our third terminal window to join our first session using the attach-session command via its alias attach:
tmux attach -t 0Note that you use the -t flag to target a specific session with any session-specific tmux commands.
Let’s do something inside this session, say run the top command with no arguments. Have a look at your first terminal window — both windows are now seeing the same session in real time! Switch to the first window and end the top command by pressing q. Not only can both windows see the same session, both are controlling it!
Before we move on, notice that while you’re in a tmux session there is a green status bar at the bottom of your terminal window. This tells you important information about your current session. Here’s my third terminal window:
On the right of the status bar you’ll see the text "bart-imac2018.localdo" 12:59 11-Jul-20. The part in quotation marks is my Mac’s hostname (not very imaginative). That’s not that useful when you’re running tmux on your local computer, but can it can be very convenient when SSHed into a remote server. You’ll also see the current date and time, not all that useful, but it can be convenient.
On the left of the status bar you’ll see information about your current session, in this case [0] 0:zsh*. The first part is the name of the session, simply 0 in this case, and the part after that is the name of the window, and the command executing in that window. Since we only have one window by default, and since we didn’t name it, it also has the default name 0.
You’ll notice that I’m using zsh as my shell these days rather than bash (more on this in future instalments). If you run the top command again you’ll see the current command change appropriately.
Controlling The Session From the Inside
You’ll notice that we now have three terminal windows open — that’s literally what a terminal multiplexer is supposed to avoid, so clearly, we’re missing something!
You can issue commands for controlling your tmux session from within your tmux session by first pressing Ctrl+b to enter command mode, and then entering your desired command.
Notice it’s Ctrl+b followed by another key, not Ctrl+b+OTHER_KEY.
Once you can enter command mode there are lots of things you can do, but thankfully, most of the really important stuff is mapped to single-key shortcuts. There is even a single-key shortcut to see all the available commands: the question mark. Try pressing Ctrl+b then ?. You can now scroll up and down through a list of all the supported commands. When you’re done being overwhelmed by how much tmux can do, hit the escape key to return to your session. 🙂
The single most important shortcut is the one to detach from a session, i.e. to exit out of tmux but leave your session running. To detach from tmux press Ctrl+b followed by d.
Naming Sessions
If you’re only going to use tmux as a work-around for a spotty internet connection to a server then you’ll only want one session, so having it named 0 is not a problem. It’s short and logical, so you’re not likely to forget it. You would simply connect each time using tmux attach -t 0 in fact, when there is only one session you don’t even have to specify its name, you can simply connect with tmux attach!
However, if you’re going to have multiple sessions, numbers become a real pain to manage. In that situation you really want descriptive names on your sessions to help you remember which is which.
Naming a Session from Within
You can (re)name a session any time from within the session by pressing Ctrl+b followed by $.
Practice by re-naming the first session to ttt by pressing Ctrl+b, then $, then back-space to delete the existing name (0), and finally typing ttt and pressing enter.
Notice that the name immediately changes in the status bar. If you now detach from this session with Ctrl+b followed by d you can see the name is also visible in the session listing:
bart-imac2018:~ bart% tmux ls
1: 1 windows (created Sat Jul 11 13:33:05 2020) (attached)
ttt: 1 windows (created Sat Jul 11 13:33:00 2020) (attached)
bart-imac2018:~ bart%Naming Sessions at Creation
We can name a new session as we create it with the -s flag. Using the terminal window we just used for the session listing, let’s make a new named session:
tmux new -s ttt2Notice the name is reflected in the status bar.
We could detach and run the listing again to see our third session, but let’s use this as an excuse to learn how to list sessions from within a session. Press Ctrl+b to enter command mode, and then s to enter session selection mode. We continue to see our session in the lower half of the window, but the top of the window now contains a list of running sessions. We can select one by using the up and down arrow keys and then pressing enter, or by typing the number next to each session on the list.
Ending Sessions
Creating sessions is great, but you do also need to be able to clean up after yourself, so let’s look at some choices for ending sessions.
Ending the Current Session
If you’re in a single-window-single-pane tmux session (like all the sessions we’ve been using in this instalment), you can end it by simply exiting from the shell running within that session, i.e., simply enter the bash/zsh command exit.
Try it by using one of your three terminal windows, connecting to the ttt2 tmux session, then, from within that session simply typing exit.
Ending a Session with the tmux Command
You can also end a session from the outside using the tmux command kill-session. As an example, let’s kill the session we re-named to ttt:
tmux kill-session -t tttIf you still had a terminal window connected to that session you’ll notice you got exited from tmux and are back in your regular shell.
Killing all Sessions
We have one final proverbial sledge-hammer at our disposal to end all our sessions in one fell swoop — we can kill the tmux server process that’s hosting all our sessions with the kill-server command:
tmux kill-serverRevisiting the attach-session Command
Since attaching to a running session is one of the most important things to be able to do, let’s take a moment to circle back to this critical command in a little more detail.
Firstly, this command is so important that it doesn’t just have a regular alias (attach), it also has the single-letter alias a.
Secondly, you don’t have to specify the session you wish to attach to. If you omit the -t flag tmux will connect to the most recently detached session.
Putting those two things together in a situation where you only use one session, you can always reattach to it with the simple command:
tmux aRecipe — Using tmux for a Resilient SSH Connection
Before finishing this instalment, let’s circle back to the problem we first used the screen command to solve — executing long-running commands on a remote server over SSH from over a patchy internet connection.
What we want is a single quick and easy command to connect to session 0 if it exists, or create a new session 0 if it doesn’t.
We know that the command tmux a will try to attach to the mostly recently used session, so if there will only ever be a session 0, then that command will work most of the time. It will fail the first time you try to connect after session 0 or the entire tmux server were killed. How could that happen? Leaving aside the obvious answer that you killed them intentionally, the most likely reason is that the Linux/Mac server you are SSHing to was rebooted.
To take our simple tmux a command to the next level, and have it intelligently create a session if none exists, we can leverage three additional things:
-
The fact that the
tmuxcommand emits standards-compliant exit codes depending on whether it succeeds or fails. -
The fact that sh-derived shells like bash and zsh interpret error exit codes as
false. -
The fact that sh-derived shells implement so-called lazy evaluation of boolean operators.
In shells derived from sh, like bash and zsh, a double-pipe indicates a boolean or operation. When or-ing two values, if the first is true, the final result will always be true because true || true is true, and true || false is also true. That means that when the shell executes the command to the left of the || and it evaluates to true (emits a success exit code), there is no need to execute the command to the right to determine the result of the || operation. For this reason, sh, bash, and zsh all skip the command to the right of an
|| operator when the command to the left succeeds. This approach is known as lazy evaluation, and used by many programming languages too.
Note that sh-derived shells take the same approach when evaluating boolean and operations, the operator for which is &&. In this case, when the command to the left of the && evaluates to false, the result will always be false, regardless of the outcome of the second command, because false && true is false, and so is false && false.
This second approach is probably more commonly used than the first, because it allows you do execute a second command if, and only if, the first succeeds. I often use this to conditionally reboot a server after a successful software update:
yum update -y && shutdown -r nowHowever, in this case we want to execute a second command only if the first fails, so we’ll make use of lazy execution of || rather than &&.
What we want to do is attach to an existing session if possible, and, only if that fails, make a new session. We know that tmux a will attach to the most recent existing session if there is one, or fail with an error, and we know that tmux will create a new session and attach to it.
Putting it all together, the following very short command will try attach to an existing session or create a new one:
tmux a || tmuxTo have a robust SSH connection you can do one of the following things:
-
Always manually run
tmux a || tmuxbefore doing any work when you connect over SSH (tedious and error prone). -
Add the command
tmux a || tmuxto the end of your~/.ssh/rcfile on the server you’re connecting to. -
Assuming your SSH GUI supports it, add the command
tmux a || tmuxto the shortcut/favourite for your server so your SSH client automatically executes it for you.
Note that I am suggesting ~/.ssh/rc rather than ~/.bashrc, ~/.bash_profile, ~/.zshrc, or ~/.zlogin because I only want tmux to kick in when SSHing to the machine, not when opening a terminal window in the GUI or connecting via a console.
Not all SSH clients support automatically executing a command when you connect, but my favourite SSH client, Core Shell, does. If you’re a fellow Core Shell user you’ll find the correct place to enter the command at the bottom of the Advanced tab of the server’s Settings pane. The setting is named RemoteCommand, and is grouped under Post Command:
Final Thoughts
In this instalment we’ve focused on using tmux as a replacement for screen, so we’ve confined ourselves to the simple situation where each of our sessions has a single window containing a single pane. We’ve ignored the ways in which tmux is much more feature-rich. In the next instalment we’ll rectify that by learning how to work with windows and panes within our sessions.
Finally, you might want to bookmark this wonderful tmux cheat-sheet.
TTT Part 39 of n — Advanced TMUX
In the previous instalment we learned how to use the tmux command as a replacement for the screen command which has been deprecated on RedHat Enterprise Linux (and hence CentOS as well.) In this instalment we’ll take TMUX to the next level, making use of the fact that a single TMUX session can contain arbitrarily many windows, each consisting of arbitrarily many panes.
As a reminder from last time — in the TMUX-universe, sessions contain windows contain panes. By default a session contains one window which contains one full-width and full-height pane. Windows can be thought of as stacking behind each other, like tabs in a browser, and panes are arrayed next to each other within a window.
Listen Along: Taming the Terminal Podcast Episode 39
part of episode 647 of the Chit Chat Across the Pond Podcast
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Working with Windows
Let’s start by opening a completely vanilla default tmux session:
tmux newThis session has one window, very imaginatively named 0. So that we can recognise it later, let’s just enter a command:
echo 'The first window!'Before we start creating and navigating between windows, I’d like to draw your attention to the left-part of the status bar. In this entirely default single-window-single-pane session is should look like this:
[0] 0:zsh*As we create and manipulate windows it will change, and I expect the meaning will become intuitively obvious as we go. If not, don’t worry, we’ll circle back to it later.
Creating Windows
Let’s start by creating a new window within our simple session. We do this be entering control mode with Ctrl+b and then pressing c for create window. We immediately jump to a fresh window. If you look down at the status bar you’ll see that the left-most part has changed to:
[0] 0:zsh- 1:zsh*Let’s now start a process in this new window so we can easily recognise it in future:
topNotice that starting the top command in the second window change the status bar again:
[0] 0:zsh- 1:top*Let’s create a third one by entering command mode again with Ctrl+b and pressing c. So we can recognise it, let’s run a command so it has some content:
less /etc/profileAgain, notice the status bar change:
[0] 0:zsh 1:top- 2:less*Finally, before we look at navigating between windows, let’s create one more window by again entering command mode again with Ctrl+b and pressing c. Notice the state of the status bar is now:
[0] 0:zsh 1:top 2:less- 3:zsh*Navigating Between Windows
We can move between windows by entering control mode with Ctrl+b and then pressing p for previous window, or n for next window. Remember, think of windows like tabs in a browser, they have an order based on the order in which they were created. The first window to be opened becomes the left-most tab, and subsequent windows line up to the right. With this mental model in place, we can get into the habit of thinking of previous as the one directly to my left, and next as the one directly to my right. One last thing to note is that both next and previous wrap around, so if you go next/right from the right-most window you end up on the left-most window, and vice-versa.
Use those keystrokes to move about as you wish, and as you do, watch the status bar changing.
The more windows you have, the more useful it becomes to be able to jump directly to a specific window, and we have two options for doing that. Firstly, the first ten windows are available by entering command mode with Ctrl+b and hitting the numbers 0 to 9. And secondly, like Ctrl+b s gives us a session picker (as we saw in the previous instalment), Ctrl+b w gives us a window picker.
Using the method of your choice, jump to the second window, and then, directly to the fourth (Ctrl+b 1 followed by Ctrl+b 3 will do it).
Understanding the Status Bar
The status bar should now look like this:
[0] 0:zsh 1:top- 2:less 3:zsh*So what does it mean?
The left-most item is the name of the session in square brackets. Because we opened a completely default session without naming it, it has defaulted to the very unimaginative 0! Let’s prove that it really is the session name by entering control mode with Ctrl+b and hitting $ to rename the session. I’m going to call mine BB Sess. My status bar now looks like this:
[BB Sess] 0:zsh 1:top- 2:less 3:zsh*Next to the session name in square brackets are items for each of our windows in order. Like sessions, windows have names, but unlike sessions, the default names are useful! By default a window is named for its currently running process. As you start and stop commands, the name of the window changes. The status bar item for each window consists of the windows’s number in the list and its name, separated by a colon, so 0:zsh is the first window and it’s named zsh because we didn’t give it an explicit name, and it is currently running a zsh shell. Similarly, 2:less is the third window and is currently running the less command.
But what about the - and * tagged on to the ends of the items for the second and fourth windows? As you were moving around between windows you may have noticed that * is appended to the current window, and - to the last-viewed window before the current one. Because we jumped straight from the second to the fourth window, the last-viewed window is not adjacent to the current window.
Toggling Between Last-viewed Windows
Why would TMUX dedicate valuable status bar space to an indicator for the last viewed window? Simple — because you can jump directly to that window by entering command mode with Ctrl+b and hitting l (lower-case L for last).
Renaming Windows
Just like you can rename sessions, you can rename windows. Note that when you explicitly set a window’s name it will not change as you run different processes. A lot of the time, the default name is more than sufficient, but that breaks down in situations where you’re running the same command in different windows simultaneously — perhaps you’re editing two files with vi, or watching two log files with tail.
Switch to the fourth window using what ever means you like, then change into the system log folder:
cd /var/logYou can rename the current window by entering command mode with Ctrl+b and pressing ,.
I’m going to name the window logs, and after I do my status bar now looks like this:
[BB Sess] 0:zsh 1:top- 2:less 3:logs*Closing Windows
You can close a window by ending the shell process running within it, e.g. with the exit command. Try this in the 4th window. You should now be in the third window with the top process we started near the beginning of this instalment still running.
You can also close a window by pressing Ctrl+b to enter command mode and hitting &. Try it on the third and second windows. Notice that TMUX is polite enough to ask you if you’re sure 🙂
Working with Panes
Panes are created by splitting an existing pane horizontally or vertically. Remember that by default, every TMUX window contains one pane, so there is always a pane to split.
To split a pane enter command mode with Ctrl+b, then press " to split it horizontally, or % to split it vertically. Let’s do both of those in order in our session. You should now have three panes, a big one across the top, and two small ones across the bottom. The current pane is highlighted with a green border.
Moving Between Panes
You can move between panes by pressing Ctrl+b to enter command mode and then pressing an arrow key. Additionally you can cycle through your panes by entering command mode with Ctrl+b and pressing o to move to the next pane in the sequence.
You can also jump directly to a specific pane by number. To see the numbers assigned to each pane enter command mode with Ctrl+b and press q. To jump directly to a pane by number enter command mode with Ctrl+b, press q, then the desired number. (You need to be quite quick — you have to press the number before the labels vanish!).
You can also jump to the most recently active pane by entering command mode with Ctrl+b and pressing ;.
Expanding Panes with Zoom Mode
The whole point in having panes is to be able to easily see the outputs from multiple commands at once, but that doesn’t mean there are not times you’ll want to focus in on a single pane for a while. TMUX supports this with a toggleable zoom mode. When you enter zoom mode the current pane takes up the full window until you toggle zoom mode off again. You can toggle zoom mode by entering command mode with Ctrl+b and pressing z. Note that zoom mode is applied at the window level, not the session level, so if you have multiple windows you can zoom some of them but not others. Finally, TMUX will not allow you to enter zoom mode on windows with just a single pane.
Try entering zoom mode and watch the status bar. Notice that zoomed windows get a Z appended to them in the status bar.
Closing Panes
You can close the current pane by exiting the shell running within it, for example with the exit command. Also, you can close a pane by entering command mode with Ctrl+b and pressing x.
Final Thoughts
As you might remember from the previous instalment, the name TMUX is a portmanteau of Terminal Multiplexer. In this instalment we’ve really put the multi into multiplexer by adding multiple windows to our sessions, and then splitting those windows into multiple panes.
These complex TMUX layouts can be very useful, but it takes a lot of keystrokes to create them. Wouldn’t it be nice to be able to build an entire layout in a single command and somehow save that for future use? I certainly find that ability very useful, so that’s what we’ll be doing in the next instalment.
TTT Part 40 of n — Automating TMUX
In instalment 38 we introduced TMUX as a replacement for the screen command which RedHat have deprecated on RedHat Enterprise Linux, and its free community variants CentOS and Fedora. Next we looked at how we can use TMUX’s windows and panes model to take things to the next level and give us multiple virtual terminal windows within a single actual terminal window. We learned that sessions contain windows which contain panes which run a shell.
We learned how to create a fresh TMUX session which gives us a single window containing a single pane running our default shell (bash or ZSH most probably). We then used TMUX commands to create additional windows, which we described as being like browser tabs, and we learned how to navigate between them. Finally, we learned how to split single panes vertically or horizontally, and to navigate between the panes within the current window.
Given the knowledge we have to date we can start a TMUX session, create the windows we need, and split those into the desired number of panes, but, we have to do it all manually each time we start a new TMUX session. Wouldn’t it be nice to be able to automate the process? Well, that’s what we’re going to do in this instalment, and along the way we’ll get two little shell-related bonus tips to boot!
Listen Along: Taming the Terminal Podcast Episode 40
part of episode 650 of the Chit Chat Across the Pond Podcast
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Multiple TMUX Commands in a Single Shell Command
The phraseology and nomenclature is about to get potentially confusing, so let’s nip that in the bud by being extremely explicit.
Consider the following shell/terminal command:
tmux new -s ttt40This is a single shell command that executes tmux with three shell arguments — new, -s, and ttt40. Those three shell arguments are handed to tmux which gets to interpret them how it will. To TMUX those three shell arguments are interpreted as the TMUX command new, the TMUX flag -s for session name, and a value for the flag, i.e. the name to give the session.
So, we have a single shell command executing TMUX with a single TMUX command. All our examples to date have taken this form.
The key to automating the creation of complex TMUX sessions is TMUX’s ability to accept multiple TMUX commands within a single shell command. These multiple commands will be applied in order, so they effectively allow us to script the TMUX session initialisation.
Multiple TMUX commands are separated by passing ; as a shell argument. The thing to watch out for is that the ; character has a meaning in the shells we are using in this series (Bash & ZSH), so we need to escape that character. We can do that in two ways, we can prefix it with a backslash, or, we can single-quote it. The following will both create named new sessions with a horizontally split pane:
tmux new -s ttt40-slash \; split-window
tmux new -s ttt40-quote ';' split-windowIn both cases we have a single shell command which executes tmux, and within that single shell command we have two TMUX commands, new with the -s flag, and split-window with no arguments.
Refresher — Listing TMUX Commands
As we learned previously, we can use the list-commands TMUX command (or its alias lscm) to get a listing of all TMUX commands. We can also use grep to see the details of just a single command, e.g. to see all the commands for creating new things with their arguments we can run:
[root@www2 ~]# tmux lscm | grep new
new-session (new) [-AdDP] [-F format] [-n window-name] [-s session-name] [-t target-session] [-x width] [-y height] [command]
new-window (neww) [-adkP] [-c start-directory] [-F format] [-n window-name] [-t target-window] [command]
rename-session (rename) [-t target-session] new-name
rename-window (renamew) [-t target-window] new-name
[root@www2 ~]#This is very useful for simply refreshing your memory, but you may need to refer to the man pages for more details, like for example, the meaning of the various one-letter flags supported by the new-session command.
Bonus 1 — Controlling the Current TMUX Session from Within TMUX with tmux
If you run a tmux command that operates on a specific session, pane, or window from within a shell in a TMUX session it will default to the session/window/pane the command is running in. So, to end a TMUX session from within a TMUX session simply run the command tmux kill-session. You’ll find this quite convenient as you go through the examples in this instalment, otherwise you’ll end up with a lot of TMUX sessions!
Since this sensible defaulting works with any TMUX command that targets a session, window, or pane those of you who find the ctrl+b key combinations harder to remember than English-y terminal commands can use the same approach for splitting panes (tmux split-window) or killing them (tmux kill-pane) etc..
Building Complex TMUX Sessions from the CLI
If you run tmux lscm, or indeed man tmux, you’ll notice that TMUX supports a lot of commands — far more than we’ve seen to so far in this series of TMUX instalments, and indeed, far more than we will see in the remainder of the series. If you want to do something with TMUX, there’s probably a command for it, you’ll just need to RTFM (read the fine manual).
Although I don’t want to duplicate the manual by listing everything TMUX can do, I do want to draw your attention to a few important features you’re likely to want when building TMUX sessions from the CLI (Commandline interface).
Executing Shell/Terminal Commands in Sessions/Windows/Panes
TMUX’s commands for creating new sessions, new windows, and new panes accept arguments named command in the descriptions — this is how you can specify a shell/terminal command to execute in the new session/window/pane. The command should be passed as a single shell argument, so if the command to run has spaces or special characters in it you’ll need to quote and/or escape those.
|
The astute readers of man pages among you note that in some situations TMUX can understand and accept shell commands spread over multiple arguments, but in my experience that doesn’t work reliably, especially when the commands have flags in them, so I always pass the entire command as single shell argument, quoted and/or escaped as needed. |
As an example, if we want a named session running the top command in the first pane and no command in the second we would run:
tmux new -s ttt40-top1 top \; split-windowNotice that because top is a single word shell command we didn’t have to quote or escape it.
If we wanted three panes with one for running commands, one for showing top, and one for showing the main system log file could do something like:
# on Linux
tmux new -s ttt40-toptail1-linux top \; split-window 'tail -f /var/log/messages' \; split-window
# on Mac
tmux new -s ttt40-toptail1-mac top \; split-window 'tail -f /var/log/system.log' \; split-windowNotice that because the tail -f … command contains spaces, I had to quote it to represent it as a single shell argument.
Applying Standard Layouts
So far we’ve simply been splitting panes and accepting the default behaviour of each pane splitting in half horizontally each time. What if we wanted our three panes to be equal, or what if we had six and we wanted them nicely tiled?
These are very common things to want to do, so TMUX provides us with a mechanism for easily arranging our panes into a number of pre-defined standard layouts. You’ll find the full list of them in the man page. The three I find most useful are even-horizontal, even-vertical, and tiled.
We can use the select-layout command to enable one of these standard layouts. As an example, let’s enhance the previous example by applying the even-vertical layout:
# on Linux
tmux new -s ttt40-toptail2-linux top \; split-window 'tail -f /var/log/messages' \; split-window \; select-layout even-vertical
# on Mac
tmux new -s ttt40-toptail2-mac top \; split-window 'tail -f /var/log/system.log' \; split-window \; select-layout even-verticalMoving the Focus
Notice that so far, the final pane to be created has always been the active one. What if we wanted our pane with nothing in it to be at the top and for that to be the pane to get focus? We can use the select-pane command for that:
# on Linux
tmux new -s ttt40-toptail3-linux \; split-window top \; split-window 'tail -f /var/log/messages' \; select-layout even-vertical \; select-pane -t 0
# on Mac
tmux new -s ttt40-toptail3-mac \; split-window top \; split-window 'tail -f /var/log/system.log' \; select-layout even-vertical \; select-pane -t 0Notice the use of the -t flag to target the 0th pane.
Advice on Targeting Sessions, Windows & Panes
Many TMUX commands use the -t flag to allow you to target a specific session, window, or pane. TMUX actually supports many different targeting mechanisms, and the man page explains them all in detail, and in the order they are applied, but my advice is to keep it simple.
The first thing to understand is full paths — for sessions that’s simply their name, which as we learned right at the start of our exploration of TMUX defaults to being a number. For windows the full path takes the form SESSION:WINDOW where SESSION is a session name and WINDOW is a window name or number. Finally, for panes the full path takes the form SESSION:WINDOW.PANE where PANE is the pane’s number.
Thankfully you don’t often need to use full paths because TMUX defaults to the current session, window, and pane. This is why select-pane -t 0 worked in the previous example — the session and window were defaulted to the current ones, so the target was simply pane 0.
If you do need to use full paths, I strongly recommend always naming your sessions and panes so the full paths look sensible — that can really help save your sanity. 🙂
Bonus 2 — Single Shell/Terminal Commands on Multiple Lines
At this stage our single tmux terminal commands are getting very long indeed, and as a result, quite difficult to read. Wouldn’t it be nice to be able to split long terminal commands across multiple lines? Thankfully the good people behind Bash and ZSH thought so too!
We’ve already seen that the \ can be used to escape special characters in Bash/ZSH, well, the newline character is a special character, so it too can be escaped by preceding it with a \. To spread a terminal command over multiple lines, simply end each line that’s not the last line with a backslash.
We can use this to divide our complex TMUX commands into easier to read, and hence understand, pieces:
tmux new -s ttt40-top2 \; \
split-window top \; \
select-pane -t 0Saving Complex TMUX Commands for Easy Reuse
Having taken so much time to build up a complex TMUX command, it makes sense to save it in some way for future reuse. You could use tools outside of the terminal for that, perhaps one of the many key-stroke expanders like TextExpander, but since we’re in the business of taming terminals here, let’s look at two approaches for saving our complete commands within the terminal environment.
Before we do that, we should make our commands just a little bit more robust by reusing the tip from the end of instalment 38 and using the || operator to reattach to an existing session with the desired name, or, create a new one:
tmux a -t topterm || \
tmux new -s topterm \; \
split-window top \; \
select-pane -t 0As a reminder, the || operator represents binary OR, and Bash & ZSH use so-called lazy evaluation to determine whether an OR operation evaluates to true or false. That means that if the first command succeeds, the second one will never be attempted, but if the first fails, it will. So, in this case that means if we succeed in reattaching to a session named topterm we’ll do that and never execute the command to build a new session, but if we fail to attach to an existing session we’ll create a new one named topterm.
TMUX Commands in Shell Scripts
The simplest way to save any terminal command or series of terminal commands for reuse is to save them as a shell script.
A shell script is simply a text file that meets three simple criteria:
-
The file is a plain text file
-
The first line is a so-called shebang line
-
The file is marked as executable
In Linux/Unix/Mac environments, the operating system can figure out how to run a plain-text executable file automatically if the very first line starts with #! followed by the path to a shell. This specially formatted opening line is known colloquially as the shebang line.
We’ll be using Bash, so our scripts will be plain text files starting with:
#!/bin/bashLet’s create a script to start a TMUX session named topterm that will have two panes, one to enter commands into at the top, and one below running the top command.
To start, let’s create a folder in our home folder named scripts, and change into it:
mkdir -p ~/scripts
cd ~/scriptsNote that by using -p (for path) we stop mkdir complaining if the folder already exists.
In this folder, use your favourite plain text editor to create a file named topterm without a file extension containing the following:
#!/bin/bash
tmux a -t topterm \
|| \
tmux new -s topterm \; \
split-window top \; \
select-pane -t 0Notice that I’ve chosen to use some indentation to make the complex command a little more readable.
Now make the file executable:
chmod 755 toptermYou can now run this script from the current folder with ./topterm, or better yet, from any folder using ~/scripts/topterm.
If you’d like this script to be executable from any folder without needing to prefix it with ~/scripts/ you need to add ~/scripts to your PATH environment (for a detailed discussion on PATH see instalment 13). In Bash you can do that by adding the following line to the end of your ~/.bash_profile file and opening a fresh terminal window (or sourcing the updated profile with source ~/.bash_profile):
export PATH=$PATH:~/scriptsTMUX Commands as Bash Aliases
An alternative approach to shell scripts is shell aliases. Most shells support these, including Bash & ZSH.
We looked as aliases in instalment 14, but as a quick reminder — the command to create an alias in Bash (and ZSH) is alias, it takes the following form:
alias ALIAS="COMMAND"As an example, the following aliases ls -l as lsl:
alias lsl="ls -l"You can now invoke ls -l by simply typing lsl.
Similarly, we can create an alias for our topterm TMUX session like so:
alias topterm="\
tmux a -t topterm \
|| \
tmux new -s topterm \; \
split-window top \; \
select-pane -t 0"Notice that the trick of using \ at the end of lines to split commands over multiple lines even works within double-quoted strings!
Something to note is that aliases only last until the current shell ends, so to have a permanent alias you need to create it in a file that gets loaded each time your shell starts. If you’re using Bash the correct file to add your aliases to is ~/.bashrc.
Final Thoughts
TMUX is clearly a very powerful tool. We’ve used it to build complex multi-shell environments that can be connected to and detached from at will, and simultaneously connected to from arbitrarily many terminal windows. The most amazing thing about TMUX is that we’ve only scratched the surface of what it can do!
However, since my intention here was never to try teach everything there is to know about TMUX, we’re going to end our exploration of the tool here. Hopefully this has been enough to pique your interest, and to enable you to learn anything else you need independently.
This series will now go back on hiatus for a little while, but the plan is to resurrect it again in a few months when Apple release macOS 11 Big Sur. Why? Because that’s an opportune moment to release a series of instalments on the topic of switching from Bash to ZSH. Since macOS Catalina the default shell on the Mac has been ZSH rather than Bash, with Bash available as an option. Since Catalina was such a bug-fest on launch many people have chosen not to upgrade all their machines (me included!), but I expect that with Big Sur’s debut there will be a lot of Terminal Tamers suddenly finding Bash’s familiar $ command prompt replaced with ZSH’s alien-feeling % command prompt!
TTT Part 41 of n — Protecting Your Secrets
This installment is the first in a number of years, and while its inspiration is very timely — the rise of Artificial Intelligence (AI) — the topic and the commands discussed are evergreen.
It’s always been important to protect your secrets on the terminal. Information-stealing malware has been checking shell history files for passwords and API keys for a digital eternity, but the rise of AI-integrated terminals adds an extra urgency. When you use these kinds of tools (I love WARP), the commands you type and perhaps even the output they produce are almost certainly uploaded to an AI company’s servers as context. At the very least, your secrets are now out of your control, but depending on the provider’s terms of service, your secrets could even be added to the training data for future models!
As the old cliché goes, the best time to start protecting your secrets on the command line is the first time you started using the command line, but the second-best time is now!
You need to develop the muscle memory to wince every time you type or paste a secret and see it echoed back to you, and in this instalment, we’ll give you the tools you need to respond to that wince by tweaking your behaviour a little.
Listen Along: Taming the Terminal Podcast Episode 41
Scan the QR code to listen on a different device

You can also play/download the MP3 in your browser
Secrets?
The whole point of this instalment is to help you protect your secrets, so let’s start by describing what we mean!
The term is intentionally generic because we really do mean any text that would compromise your security if it were to fall into the wrong hands. This includes passwords, API keys, private keys, and more.
Why Protect Your Secrets on the Terminal?
It has always been true that every terminal command you type gets saved in your shell’s history file. For Bash, that’s ~/.bash_history, and for ZSH it’s ~/.zsh_history. These files power the various shell history mechanisms like the up-arrow to replay recent commands, the history command to list previously executed commands, and Bash’s reverse search triggered with ctrl+r.
Some security tools stream these files to central logging servers for auditing purposes, and of course, stealer-type malware looks for and steals copies of these files as a matter of course. This is why you need to avoid including secrets directly in your commands.
Guiding Principles
Let’s start with the big picture — these are the key points to remember:
-
When possible, only store secrets in your password manager or your OS’s keychain.
-
Avoid duplication — make as few copies of secrets as possible. The ideal is to keep just one copy in your password manager or OS keychain, but that’s not always practical or possible. When you absolutely need to store copies elsewhere, make as few copies as possible, and record the locations in your password manager.
-
Never hard-code secrets into scripts or code of any kind.
-
Never include secrets directly in shell commands so they stay out of your history file!
-
For interactive commands, provide secrets in real-time as and when needed.
-
For automations, favour integrations with your password manager, your OS’s keychain, or environment variables over configuration files.
-
If you absolutely must store secrets in configuration files, use Unix file permissions to apply the principle of least privilege by configuring the file ownership and permissions as restrictively as possible.
Our focus in this instalment will be on interactive commands, because that’s how we most often interact with our command shells. Automations that need to run unattended are outside of the scope of this series, and often involve advanced tools or making carefully considered tradeoffs. As the cliché goes, we’ll leave that as an exercise for the reader 🙂
Secure Terminal Inputs are Secure
POSIX-compliant command shells like those we use in our Linux and macOS terminals provide a secure input stream expressly for the purpose of securely entering secrets. You’ll recognise these secure inputs because they silently accept your input without echoing it to the screen as you type.
Well-written terminal apps will use this secure input stream when prompting for secrets like passwords. In fact, we’ve already seen a few examples of this in previous installments — the sudo and ssh commands both use secure terminal inputs to prompt for passwords.
Create Your Own Secure Input Prompts with the read Command
It’s all good and well using secure inputs when the commands you need to use support them, but what about the situations where they don’t? Some commands expect to be passed secrets as command-line arguments. As you become more comfortable on the terminal, you may well start writing ever more and ever more complex scripts of your own, and you may need those scripts to prompt for secrets too.
The solution both for securely passing secrets as arguments and for securely prompting for secrets in your own scripts is the same — the read command with the -s (for secure) flag.
Before we look at secure inputs with read, let’s first look at how read works by default.
Read’s function is to prompt for input from the shell’s standard input stream (STDIN), generally your keyboard, and save the entered text into a shell variable.
If you run the command without any flags or arguments, a cursor will appear on a new line, awaiting your input. Confusingly, there is no prompt, just a blinking cursor! Whatever you type will be echoed to the screen until you press Enter to submit the input.
The text you entered gets saved to a special shell variable named $REPLY. We can see this for ourselves by entering the command read, typing some text, hitting Enter, and then running the command echo "$REPLY" to show the content of the $REPLY variable.
Having the text go into the $REPLY variable is not very useful, so you’ll almost always want to specify your own variable name by passing it, without a leading $, as the only argument. For example, to read into a variable named $my_text, you would run:
read my_textEnter some text, then verify that it was indeed saved to $my_text by running:
echo "$my_text"This is great for reading non-secret text, but what about secrets like passwords? For that, we need the -s flag to trigger the terminal’s secure input mode. For example, to securely read an API key into a variable named $my_api_key, you would use the command:
read -s my_api_keyNotice that as you typed, nothing was echoed to the screen. Again, you can verify that the text was indeed saved to $my_api_key by running:
echo "$my_api_key"Finally, while there’s little value in specifying a prompt when you’re reading directly into a variable on the terminal, you really do need to provide some kind of prompt when your scripts ask for input!
Unfortunately this is one of the few places where ZSH has made a breaking change from Bash, so the syntax is completely different between the two shells.
Even though Macs now ship with ZSH as the default shell, Bash is still considered the de facto standard shell for scripting, so I still write all my scripts in Bash even though I use ZSH in my terminal windows.
In Bash, you simply us the -p flag to specify a prompt string. For example, to securely read an API key into a variable named $my_api_key with a prompt, you would use the command:
# Bash only!!!
read -s -p 'API key: ' my_api_keyZSH does things differently, you add the prompt to the end of the variable name argument using ? symbol as the separator, so the example above becomes:
# ZSH only!!!
read -s 'my_api_key?API key: 'Notice that in both variants I needed to include the space after the : as part of the prompt string.
How to use read to Keep Secrets Out of Your Shell History
The problem to be solved is that we want to pass a secret to a command as an argument, but without the secret showing up in our history file.
At the time of recording, November 2025, Have I Been Pwned (HIBP) have just released a free test API key that can be used to experiment with their powerful API before you start paying for a subscription. We’re going to use this free, publicly available API key in our example. HIBP’s API is a so-called REST API, so you access it over the HTTP(S) protocol. From the terminal, we can send HTTP requests using the curl command.
Before we do things the right way, let’s first intentionally do it insecurely by directly passing the API key in our arguments to the curl command:
curl --header 'hibp-api-key: 00000000000000000000000000000000' https://haveibeenpwned.com/api/v3/breachedaccount/multiple-breaches@hibp-integration-tests.comThis command sends a request to the HIBP API asking for a list of breaches for the test email address multiple-breaches@hibp-integration-tests.com, and it returns a JSON response listing the breaches:
[{"Name":"Adobe"},{"Name":"Stratfor"},{"Name":"Gawker"}]Great, the command works, but what’s happened to our API key? We’ve written it to our disk in plain text!
We can infer this has happened because when we hit the up-arrow to show previous commands, we now see that curl command with the API key. We can also reveal it with the history command (no arguments needed).
These features are all powered by our shell’s history file, so let’s take a look at that file directly to see the API key.
If you’re running Bash, you’ll find the API key at the end of the ~/.bash_history file:
tail ~/.bash_historyAnd if you’re running ZSH (the default on modern versions of macOS), you’ll find it at the end of the ~/.zsh_history file:
tail ~/.zsh_historyOops! Not good!
Now, let’s do this the right way and contrast the resulting history file entry.
First, we’ll use the read command to securely prompt for the API key and save it to a variable named $hibp_api_key:
read -s hibp_api_keyEnter the API key (00000000000000000000000000000000) into the prompt and hit Enter.
Note that I didn’t bother to add prompt text because I’m running this directly rather than in a script.
We know that we have the API key safely stored in the $hibp_api_key variable without it ever being written to disk. We can verify this with the echo command:
echo "$hibp_api_key"Let’s now use this variable to construct a safe version of the previous curl command:
curl --header "hibp-api-key: $hibp_api_key" https://haveibeenpwned.com/api/v3/breachedaccount/multiple-breaches@hibp-integration-tests.comFirstly, the command works just as before, returning the same JSON response, but more importantly, let’s check our shell history file to see what got written there this time.
historySuccess! The API key was not written to disk this time!
|
Windows Users can Achieve Similar Results with PowerShell
When you need a modern shell on Windows, you should be using PowerShell rather than the old DOS shell, and PowerShell’s In PowerShell, there are two types of strings: regular strings and secure strings. Secure strings are encrypted in memory, so they’re more secure than regular strings, but not all commandlets support them. This means there are times you need to safely read into a secure string, and times you need to safely read into a regular string. When using this in a script, you can provide a prompt string with the |
Some Helpful Tips and Tricks
We’ve seen how to use a variable to pass a secret using a command-line argument, but there are scripts and commands that expect to find the secrets they need in environment variables. These scripts and commands will specify the name of the environment variable to use in their documentation.
Instalment 12 is dedicated to the environment, but the key difference between shell variables and environment variables is that they’re available to the commands you run in your shell as well as within the shell itself.
We’ve already seen how to read secrets into shell variables with any arbitrary name, so the only extra step needed is to use the export command to promote the shell variable to an environment variable. To do that, simply pass the name of the variable as the only argument without a preceding $.
For example, we can promote our $hibp_api_key shell variable to an environment variable with:
export hibp_api_keyA very common kind of secret is the password used to unlock an SSH key. Remember that SSH provides a tool specifically designed to avoid the need to repeatedly enter that password — ssh-agent. We explored that in great detail in Instalment 37.
Mac users can use the pbpaste command to safely copy a secret from the clipboard straight into a shell variable. For example, select the following text and copy it: some big secret!
Now, run the command:
my_secret=$(pbpaste)The text from the clipboard is now safely stored in the $my_secret variable without ever being written to disk. We can prove this with:
echo "$my_secret"One nice advantage of this approach is that you can combine it with the export command to save the value and prompt the newly created shell variable to an environment variable in one step:
export my_secret=$(pbpaste)Finally, if you use a password manager, you may find that it offers command-line tools to make it easier to move secrets from your vaults straight into shell variables. Each password manager is different, so you’ll need to check the documentation for your specific password manager to see if it has these kinds of features and how to use them.
Since I’m a long-time 1Password user, I know they offer a command-line tool named op which can be quickly installed on a Mac using Homebrew:
brew install 1password-cliYou’ll find the full documentation for how to connect the app to the command-line tool here, but here’s a quick example:
twitter_password=$(op item get 'Twitter (Personal)' --fields 'label=Password' --reveal)Final Thoughts
Remember to keep your secrets secret! If you can see a secret by hitting the up-arrow, you’re doing it wrong! Stop, think about how you can avoid doing that, and start doing it the right way from then on.
It will take some time, and perhaps some faffing about, to get the hang of things, but it’ll soon become second nature. Your future security is worth the effort!
Afterword
The creation of Taming the Terminal was executed using open source tools on an open source platform and with version control through the open source git technology. Allison Sheridan interviewed Dr. Helma van der Linden on how she created the book in an episode of the Chit Chat Across the Pond podcast. Helma walks through how each tool played its part, and how she developed the process. It’s a great story of ingenuity on Helma’s part and an amazing story of how open source allows us to build great things. You can find the audio and notes with links to the tools at https://www.podfeet.com/blog/2020/08/ccatp-649/
Colophon
The Podfeet Press
© 2020 by The Podfeet Press
Published in the Milky Way Galaxy
Version 1.6.0
Date revision 2026-02-18
Compiled: 2026-02-18 07-01-22
This book is designed and handcrafted by Allison Sheridan and Helma van der Linden. The cover is designed by Allison Sheridan. The font types are Noto Sans and Noto Serif.
Created in Asciidoctor and macOS.
Updates
This book will be updated whenever new episodes are added or errors are fixed. You can check if a new update is available at: https://github.com/bartificer/taming-the-terminal/releases
Creative Commons license
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
